
BLSTM for Chinese G2P
Shan, Changhao, Lei Xie, and Kaisheng Yao. “A bi-directional lstm approach for polyphone disambiguation in mandarin chinese.” 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP). IEEE, 2016.
들어가며
영어에서 G2P 모델을 활용해서 단어를 알맞은 발음으로 변환하는 것처럼 중국어에서도 음성 합성이나 인식을 위해서 G2P가 필수적이다. 그런데 영어는 alphabetic language로써 G2P가 해결해야 하는 주된 문제가 out-of-the-vocabulary(OOV) 단어의 발음을 생성해내는 것이라면, 중국어는 character-based language여서 대부분의 단어가 정해진 발음과 성조가 있기 때문에 소수의 다음자(polyphone)에 대한 알맞은 발음을 정해주는 것이 중요하다. 이를 polyphone disambiguation이라고 하는데 그동안 knowledge-based와 learning-based의 접근이 이루어져 왔다. knowledge-based는 다양한 발음을 가진 사전과 사람이 만든 규칙을 통해 polyphone의 발음을 결정하는 방식인데 전문가의 노력이 많이 들어가는 방식이므로 광범위하게 사용되기에는 무리가 있다. 그러므로 learning-based 접근 방식으로 polyphone disambiguation을 자동으로 해줄 수 있는 모델을 설계하는 연구가 활발히 이루어지고 있다.
본 논문에서는 단순하게 영어 G2P를 위해 사용되던 모델을 가져다 쓸 수도 있지만 언어간의 차이로 인해 그대로 활용할 경우 낮은 성능을 기록할 수 밖에 없고 언어의 특성에 맞게 문맥을 함게 모델링 해주는 방식에 대한 고민이 필요하다고 말한다. 그리고 기존 LSTM을 활용한 연구들을 발전시켜 hidden layer를 더 깊게 쌓고 양방향 flow가 가능하도록 변형시켜주면 모델이 계층적 특징을 학습하면서 성능을 향상시킬 수 있다고 주장한다.
핵심 요약
- 중국어 polyphone disambiguation을 위해 POS tag를 사용하는 것이 효과적이다.
- bi-directional LSTM으로 문장의 문맥을 학습함으로써 polyphone disambiguation 문제를 해결할 수 있다.
- G2P를 위해 많이 쓰였던 베이스라인 모델들과 비교했을 때 큰 차이로 SOTA를 기록했다.
Features
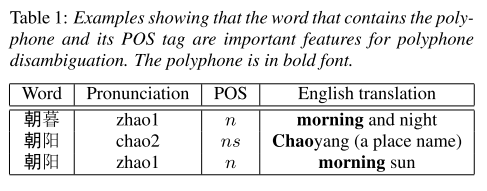
하나의 polyphone이 단어에서 어떤 품사 역할을 하는지에 따라서 발음과 뜻이 달라지는 경우를 보여준다. 따라서 polyphone disambiguation에서 POS tag가 중요한 feature임을 알 수 있다.
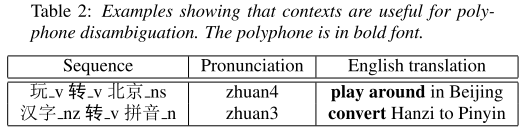
그리고 표 2를 보면 앞뒤 문맥에 따라서 polyphone의 발음이 달라지기 때문에 저자들은 이 문맥을 모델링하기 위해서 RNN을 써야겠다는 생각을 갖게 되었다고 한다.
모델 구조

모델의 입력은 한자 그대로를 사용하며, 출력은 polyphone에 해당하는 발음은 pinyin으로 출력하고 나머지 부분은 null 기호인 ‘-‘로 출력하도록 한다.
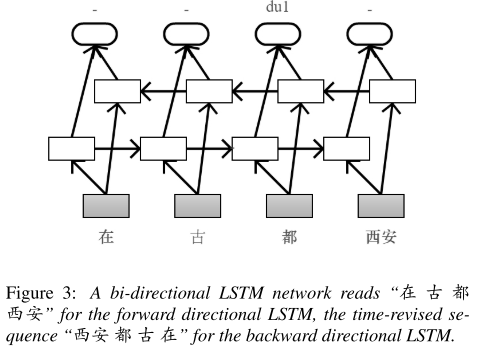
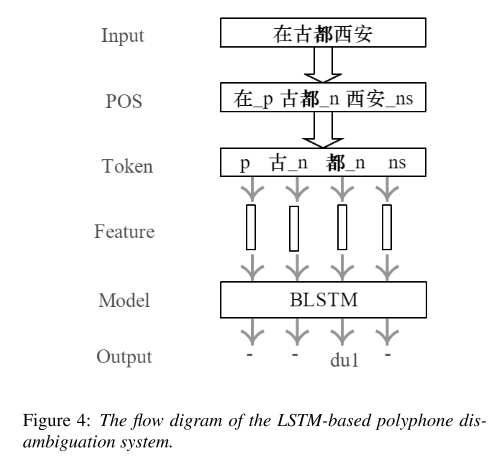
기본적인 bi-directional LSTM 구조를 가지고 있다. 앞서 언급한 것처럼 입력된 데이터를 POS tagging하여 쪼개는데 이를 다시 한번 tokenize하는 과정을 거친다. polyphone이 포함된 단어는 다시 한 번 쪼개고, 나머지 단어는 POS tag만을 남긴 채 지우는 과정이다.
실험 결과
저자들이 크롤링을 통해 수집한 174899 문장들을 이용해 실험하였다. pinyin 레이블링도 직접 진행했다고 한다. 이 문장들은 총 79개의 polyphonic 문자들을 포함하고 있다.
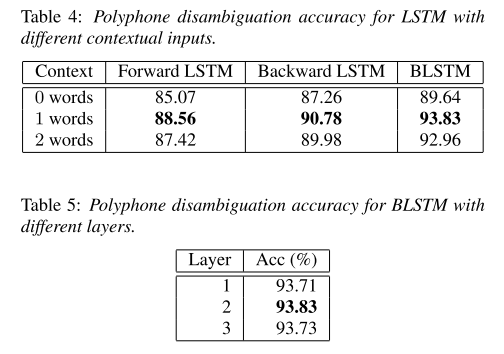
먼저 LSTM 종류와 context size에 따라 polyphone disambiguation accuracy를 비교해 보았다. BLSTM을 1 word context로 사용했을 때 성능이 가장 높았다. BLSTM이 unidirectional LSTM들보다 항상 높은 성능을 보여주기 때문에 역시 polyphone disambiguation에 앞뒤 문맥의 정보가 중요하다고 할 수 있다.
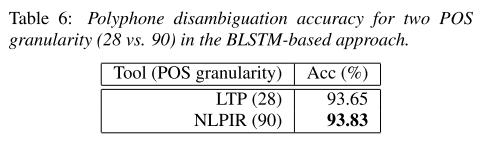
위의 실험에서 POS tagging을 진행할 때 NLPIR이라는 툴을 사용했는데 이를 granularity가 더 적은 LTP로 대체했을 때 accuracy가 감소하는 결과로 나타났다. 즉, POS tagging을 더 세분화해서 진행할수록 성능 향상에 도움이 된다.
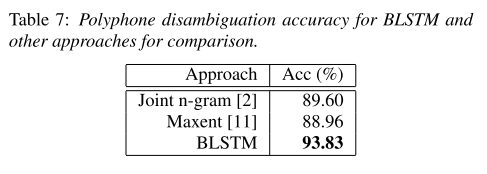
마지막으로 기존에 많이 쓰이던 joint n-gram 모델과 maximum entropy(Maxent) 기반 모델의 성능과 비교했을 때도 BLSTM이 우월한 성능을 보여주기 때문에 mandarin chinese의 polyphone disambiguation이라는 task에서 SOTA를 기록했다고 주장한다.
의견
- polyphone disambiguation을 잘 해결하였더라도 현재 BLSTM이 모든 입력을 발음으로 바꿔주는 것이 아니라 polyphone에 해당하는 입력만 pinyin으로 변환해주고 있기 때문에 모든 단어의 G2P 모델로 사용하기 위해서 사용했을 때도 성능이 유지되는지 확인이 필요할 것 같다.
- LSTM 성능 비교 실험에서 backward LSTM의 성능이 두번째로 높은 걸로 보아 이는 중국어의 polyphone 발음이 뒤의 문맥 의존도가 더 높다는 해석으로 이어질 수 있을 것 같은데 이에 대한 설명이 없어서 아쉽다.




Leave a comment