
AASIST
Jung, Jee-weon, et al. “Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks.” ICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022.
들어가며
스피치에서 위조된 흔적, 즉 아티팩트는 spectral 도메인이나 temporal 도메인에 모두 존재할 수 있다는 특성이 있다. 기존의 아티팩트 검출 방식들은 각각 특정 아티팩트에 맞게 튜닝된 서브 시스템들을 통합한 앙상블 시스템을 채택하였지만 계산에 많은 리소스가 필요하다는 단점이 있다. AASIST는 이런 단점을 극복하기 위해서 앙상블 시스템이 아닌 단일의 효율적인 시스템을 추구하며 만들어진 음성 딥페이크 탐지 모델이다. heterogeneous stacking graph attention layer (HS-GAL)이라는 그래프 어텐션을 사용해서 이질적인 정보를 담고 있는 spectral 그래프와 temporal 그래프를 통합하여 위조 여부를 판별한다. AASIST는 SOTA 모델보다 20% 향상된 min t-DCF를 기록하면서 우월성을 입증했고, 가벼운 버전인 AASIST-L은 85K 파라미터만으로 다른 경쟁 모델들의 성능을 능가한다.
오디오 anti-spoofing 분야에서는 spoofing 방식에 따라 logical access (LA)와 physical access로 구성된 2가지 시나리오가 연구되었는데, 본 논문에서 초점을 맞추고 있는 태스크는 LA이다. 즉, VC나 TTS 알고리즘으로 생성된 음성 탐지에 특화된 모델을 제안한다.
핵심 요약
- graph attention layer의 확장 버전인 HS-GAL을 제안하여 이질적인 그래프 표현을 함께 모델링 한다.
- 얼굴 인식 연구에서 제안된 max feature map과 유사한 max graph operation (MGO)을 제안한다.
- HS-GAL에서 나온 stack node를 사용하여 새로운 readout 방법을 제안한다.
모델 구조

Encoder
Encoder는 raw audio를 받아서 high-level feature map을 추출하는 역할을 하고, RawGAT-ST와 동일한 RawNet2-based encoder를 사용한다. RawNet2는 화자 인식 분야에서 처음 쓰이기 시작했지만 최근 anti spoofing 연구에서도 활발하게 사용되는 추세이다. 저자들은 오리지널 RawNet2와는 조금 다르게 sinc-convolution 레이어의 출력을 spectrogram과 유사한 2D 이미지로 해석한다.
Graph Module
Encoder의 출력은 절댓값으로 변환한 뒤 spectral 축과, temporal 축으로 각각 max를 취하여 2개의 graph를 생성한다. 그리고 graph attention과 graph pooling으로 이루어진 graph module을 통과한다. AASIST에서 사용하는 graph attention 레이어는 오리지널과는 조금 다르게 모든 노드가 연결된 graph를 사용한다. 왜냐하면 이 태스크에서 어떤 노드 쌍이 서로 연관이 있는지 사전에 결정하기 어렵기 때문이다. 대신에 셀프 어텐션 메커니즘을 활용해 데이터에 기반하여 어떤 노드끼리 연관이 높은지 어텐션 웨이트를 통해 나타낸다. graph pooling은 graph의 사이즈를 효과적으로 줄이기 위하여 사용하는데, graph u-net에서 제안한 attentive graph pooling 을 사용하며 오리지널 pooling 메커니즘에서 projection vector normalization은 생략하였다.
여기까지는 RawGAT-ST와 동일하다고 볼 수 있지만, AASIST에서는 2개의 그래프를 합친 이후에 단순히 element-wise operation과 fully-connected layer를 적용하는 대신 HS-GAL이라는 새로운 어텐션 레이어를 사용한다. 또한 max graph operation (MGO)과 readout도 새롭게 제안한다.
Graph Combination
graph combining을 통해 2개의 그래프에 존재하는 이질적인 노드들 사이에도 엣지를 생성하여 하나의 그래프를 만든다. 이렇게 병합을 하더라도 서로 다른 그래프에서 온 노드들이 서로 다른 latent space 상에 위치하므로 그래프는 여전히 heterogeneous하다.
HS-GAL
합쳐진 그래프는 HS-GAL을 거치게 된다. HS-GAL은 heterogeneous graph attention network (HAN)에서 영감을 받아서 만들어졌으며, heterogeneous attention과 stack node로 구성되어 있다. 먼저, HS-GAL에 들어가는 입력은 같은 임베딩 사이즈를 가지도록 projection layer를 거친다.
- heterogeneous attention: homogeneous 그래프들은 어텐션 웨이트를 만들 때 하나의 projection vector를 공유하여 사용하지만 heterogeneous 그래프를 위해 저자들은 3개의 서로 다른 projection vector를 사용한다. spectral graph의 노드들끼리 연결하는 엣지를 위한 벡터, spectral과 temporal graph 노드들을 연결하는 엣지를 위한 벡터, 그리고 temporal graph의 노드들끼리 연결하는 엣지를 위한 벡터이다. graph attention layer는 두 노드들 사이에서 element-wise multiplication을 사용하여 어텐션 웨이트를 symmetric하게 만든다. 이건 오리지널 graph attention layer에서 두 노드를 컨캣한 것과는 다른 방식이다.
- stack node: BERT의
토큰과 비슷한 존재로, heterogeneous information을 저장하는 역할을 하는 노드이다. stack node는 모든 노드와 연결되어 있지만 다른 노드에서 stack node로 가는 방향으로만 연결되어 있어서(uni-directional) 다른 노드로 정보가 전달되지는 않는다.
MGO and readout
MGO는 anti-spoofing 연구에서 element-wise maximum operation이 좋은 성능을 보여주는 것에서 영감을 받아 만들어졌다. MGO는 스푸핑(딥페이크 변조)으로 인해 발생한 다양한 아티팩트를 병렬로 감지하고 이를 결합하는 절차를 모방하는 것을 목표로 한다. 구체적으로 MGO는 2개의 브랜치로 나뉘어 있고 각 브랜치에는 2개의 HS-GAL이 연속적으로 연결되어 있다. 그리고 HS-GAL 사이에는 graph pooling layer가 있다. 각 브랜치에 있는 첫번째 HS-GAL에서 만들어진 stack node는 두번째 HS-GAL로 전달된다. 그렇게 하여 나온 각 브랜치의 출력과 stack node들에 element-wise maximum이 적용된다.
readout은 node-wise maximum과 average를 적용하여 두개의 노드를 만들어내고 이 두개를 컨캣하여 연결한 것과 stack node를 마지막 hidden layer에 통과시켜 bona-fide(real) or spoofed(fake) 판단을 내린다.
실험 결과
모든 실험은 ASVspoof 2019 LA 데이터셋을 사용해서 수행되었다. train, dev 셋은 총 6개의 spoofing attack (A01-A06)을 포함하고 있고, eval 셋은 총 13개의 spoofing attack (A07-A19)을 포함한다. 평가 메트릭으로는 min t-DCF와 equal error rate (EER)를 사용한다. min t-DCF는 스푸핑과 스푸핑 탐지 시스템이 speaker verification 시스템의 성능에 미치는 영향을 보여주는 반면, EER은 순전히 스푸핑 탐지 성능만을 반영한다.
그리고 사전 연구에 따르면 스푸핑 탐지 시스템의 성능은 랜덤 시드에 따라 변동이 심할 수 있기 때문에 이 논문의 모든 실험 결과들은 3개의 랜덤 시드로 수행된 실험 결과들의 평균과 가장 좋았던 점수로 나타낸다.

표 1은 EER eval 셋의 각 attack에 대해 EER과 pooled min t-DCF (P1), pooled EER (P2)을 나타낸 결과이다. SOTA baseline인 RawGAT-ST와 EER을 세부적으로 비교했을 때 13개 중 9개 컨디션에 대해서 AASIST가 유사하거나 더 나은 성능을 보여준다. 또한 P1, P2는 3개 실험 평균과 최고 점수 모두 베이스라인을 능가한다.
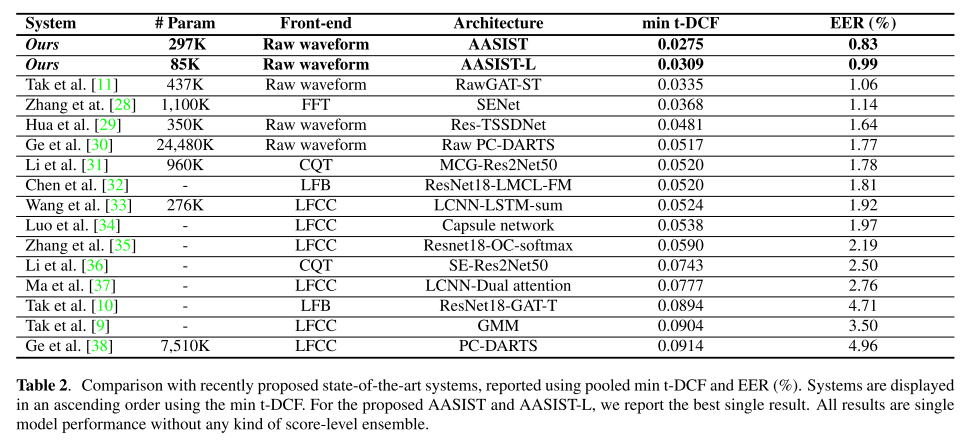
표 2는 다른 SOTA 시스템들과의 비교를 보여준다. AASIST가 모든 시스템을 능가하고 가장 좋은 성능을 보여준다. 주목할 점은 상위 6개 시스템 중 5개가 raw audio를 입력으로 받는다는 점과 상위 3개 시스템 모두 graph attention network를 사용한다는 점이다. 또한 가벼운 버전인 AASIST-L은 최고 성능을 기록하진 못했지만, AASIST를 제외한 모든 시스템을 앞지르는 결과를 보여준다.
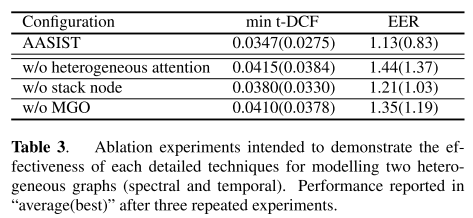
표 3에서는 어블레이션 스터디 결과를 보여준다. heterogeneous attention, stack node, MGO 모두 유의미한 성능 향상을 보여준다는 것을 확인할 수 있고, 이 중 heterogeneous attention이 성능에 가장 큰 영향을 끼친다.
의견
- spectral, temporal 그래프를 활용해서 어텐션을 계산하는 것은 RawGAT-ST 모델에서부터 자연스레 발전할 수 있는 아이디어라 생각되지만, stack node를
토큰처럼 활용하는 것이 참신하다고 느껴졌다. - AASIST-L을 만드는 방법이 더 자세하게 적혀있으면 좋았을 것 같다.

Leave a comment