
AdaSpeech
Chen, Mingjian, et al. “Adaspeech: Adaptive text to speech for custom voice.” arXiv preprint arXiv:2103.00993 (2021).
들어가며
요즘 사용자 맞춤 음성(custom voice)에 대한 관심이 늘고 있다. 개인 비서, 뉴스 방송, 음성 길 안내, 그리고 상용 음성 플랫폼 등이 발전하면서 수요가 증가하고 있는 것인데 맞춤 음성을 생성하는 기술은 주로 소스 TTS 모델을 개인화된 음성에 맞춰 조정하는 과정을 통해 이루어진다. 이때 사용되는 개인화 음성 데이터는 편의의 목적으로 양이 적은 경우가 대부분이며, 양이 적기 때문에 생성된 음성이 자연스럽고 원래의 음성과 유사하도록 느껴지게 만드는 것은 매우 어려운 과제다.
개인화 음성으로 모델 학습 시에 생기는 문제는 크게 두 가지가 있다.
첫째, 특정 사용자의 음성은 소스 TTS 모델을 학습시킨 음성 데이터와는 다른 음향적 특징(acoustic conditions)을 가진 경우가 많다. 예를 들어, 말하는 사람의 운율, 스타일, 감정, 강세, 녹음 환경 등이 다양하고 이로부터 생기는 차이가 소스 모델의 일반화 성능을 저해하여 낮은 적응 품질을 야기할 수 있다.
둘째, 소스 TTS 모델을 새로운 음성에 대해 적응시킬 때 fine-tuning 파라미터와 음성 품질에 trade-off가 있다. 즉, 더 많은 적응 파라미터를 사용할수록 좋은 품질의 음성을 생성할 수 있지만 메모리 사용량이 증가하고 모델을 배포하는 데에 큰 비용이 따른다.
기존의 연구들은 전체 모델 혹은 디코더 부분을 fine-tuning 하는 방식, speaker embedding 만을 fine-tuning 하거나 speaker encoder module을 훈련시키는 방식, 소스 음성 데이터와 적응 데이터의 도메인이 같다는 가정을 하는 등의 방법으로 접근하여 개인화 음성을 생성하고 있지만 모델의 파라미터가 너무 많거나 만족할만한 품질을 내지 못하는 이유로 실사용에 문제가 있다.
따라서 본 논문에서는 위의 문제들을 해결하기 위해 AdaSpeech라는 모델을 제시한다. 새로운 음성을 높은 품질로 효율적으로 생성할 수 있는 TTS 모델이다. 크게 pre-training, fine-tuning, inference의 3단계로 나누어 파이프라인을 구성했고 기존의 어려움을 해결하기 위해 두 가지 테크닉을 사용한다.
핵심 요약
- Acoustic condition modeling을 통하여 scope에 따른 음향적 특징들을 추출하고 기존의 phoneme encoding 벡터에 더해줌으로써 모델의 일반화 성능을 향상시켰다.
- Conditional layer normalization을 사용하여 소스 모델을 새로운 화자의 데이터에 대하여 적응시키는 과정을 효율적으로 개선하였다.
- 기존의 Baseline 모델들보다 더 적은 파라미터, 적은 양의 새로운 음성 데이터를 가지고 고품질의 맞춤 음성을 만드는게 가능해졌다.
모델 구조
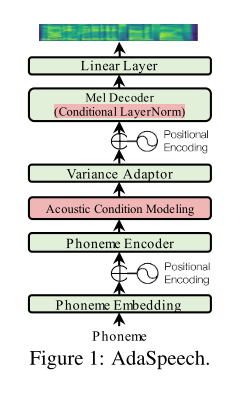
AdaSpeech의 backbone 모델은 FastSpeech 2다. 크게 phoneme encoder, variance adaptor, mel decoder로 이루어져 있고 여기에 저자들이 고안한 새로운 두 가지 요소들이 포함된 형태이다.
Acoustic Condition Modeling
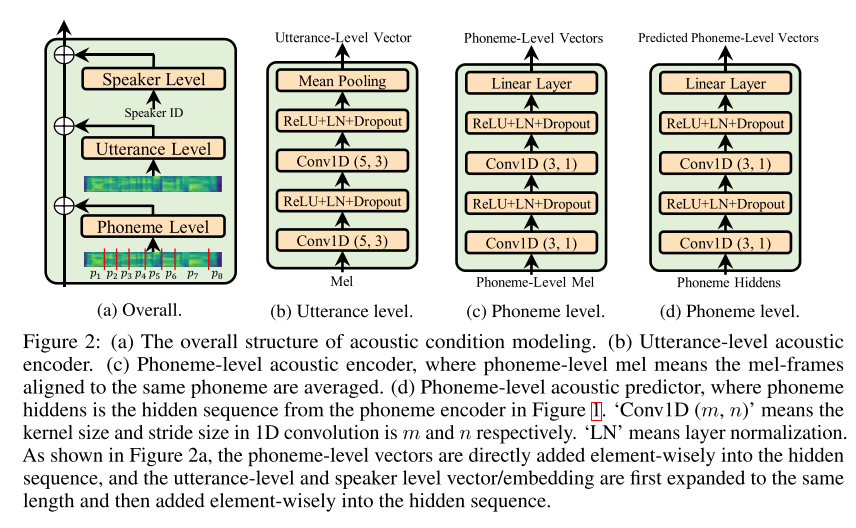
일반적으로 모델 학습에 쓰인 소스 음성이 맞춤 음성의 음향적 특징들을 모두 커버할 수 없기 때문에 모델의 일반화 성능을 끌어올리는 것이 중요하다. TTS에서 모델의 입력으로 들어간 텍스트에 이러한 음향적 특징들이 담기기는 어려우므로 모델은 학습 데이터에서 음향적 특징을 기억하는 편향을 가지게 되는데 이는 맞춤 음성을 생성할 시 일반화 성능을 저해하는 요소로 작용한다. 이를 해결하기 위한 가장 단순한 방법은 모델의 입력으로 음향적 특징들을 제공해주는 것으로, AdaSpeech에서는 speaker level, utterance level, phoneme level로 나누어 광역적인 정보부터 지엽적인 정보까지 입력으로 함께 넣어주는 방식을 택했고 이를 Acoustic Condition Modeling이라고 부른다. 각각의 레벨은 아래와 같은 정보들을 담는다.
- Speaker level: 화자의 전체적인 특징을 잡아내는 레벨로, 가장 큰 범위의 음향적 특징을 나타낸다(예: speaker embedding).
- Utterance level: 문장을 발음할 때 나타나는 특징을 잡아내는데 입력으로 레퍼런스 음성의 멜 스펙트로그램이 쓰이고 이로부터 특징 벡터를 출력한다. 모델을 훈련시킬 때는 타겟 음성이 레퍼런스 음성이 되고, 추론 시에는 그 화자의 음성 중 하나를 무작위로 골라서 레퍼런스 음성으로 활용하는 식이다.
- Phoneme level: 문장의 음소들 단위로 특징을 잡아내는 가장 작은 범위의 레벨이다(예: 특정 음소에 대한 강세, 피치, 운율, 일시적 주변 소음). 이때는 같은 음소에 해당하는 멜 프레임들을 구간 내 평균으로 치환하여 나타낸 음소 레벨 멜 스펙트로그램을 입력으로 넣어준다. 그리고 추론 시에는 구조는 동일하지만, phoneme encoder로부터 나온 hidden vector를 입력으로 받아 음소 레벨 벡터를 예측하는 acoustic predictor를 사용한다.
Conditional Layer Normalization
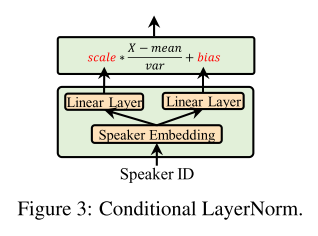
AdaSpeech의 멜 디코더는 Transformer 모델에 기반해서 self-attention과 feed-forward network로 이루어져 있는데 이 부분에서 많은 파라미터가 사용되기 때문에 새로운 음성에 맞춰 fine-tuning 시키는 과정이 효율적이지 않을 것이다. 그래서 저자들은 디코더 각 층의 self-attention과 feed-forward network에 Conditional Layer Normalization을 적용했고 여기에 사용되는 scale과 bias를 화자에 맞게 업데이트 해주는 식으로 fine-tuning 시 업데이트되는 파라미터의 수를 줄였다. 그리고 여기서 사용되는 scale과 bias는 위와 같이 각각 linear layer을 통과하여 나오게 되고 speaker embedding으로부터 이 벡터들이 계산되기 때문에 conditional이라는 이름이 붙었다.
학습 및 추론 과정

AdaSpeech를 학습시키고 새로운 화자에 대해 음성을 추론하는 과정은 위의 알고리즘으로 요약할 수 있다.
추론 시에 화자 정보로부터 계산해야 하는 파라미터(fine-tuned)와 학습을 통해 고정된 파라미터(not fine-tuned)의 값을 활용하여 멜 스펙트로그램을 만드는 것을 알 수 있다.
실험 결과
맞춤 음성 품질 평가
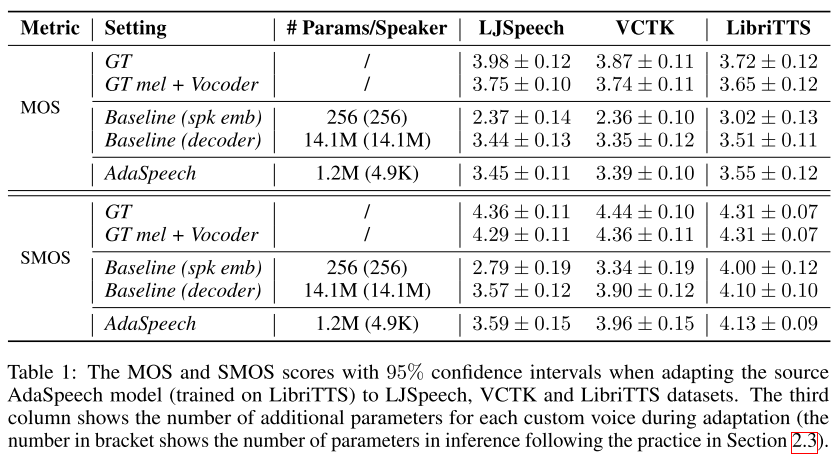
보코더로 MelGAN을 사용하였고 합성된 맞춤 음성의 자연스러움을 MOS로, 유사성을 SMOS라는 척도로 평가하였다. AdaSpeech가 Baseline보다 적거나 비슷한 수준의 파라미터만을 가지고 우수한 품질의 음성을 합성할 수 있다는 것을 알 수 있다. 그리고 당연하게도 소스 TTS 모델을 LibriTTS에 대해 pre-train하였기 때문에 LibriTTS의 새로운 화자로 적응시켰을 때 가장 높은 품질 점수를 받는 것이 보인다.
Ablation Study
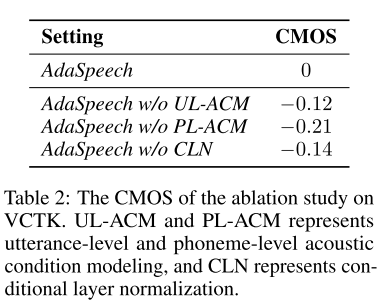
상대적 품질을 평가할 수 있는 CMOS(comparison MOS)를 활용해 본 논문에서 contribution으로 주장하는 테크닉들에 대한 ablation study를 진행하였다. 모든 테크닉들이 품질 향상에 기여한다는 결론을 내릴 수 있다.
Acoustic Condition Modeling 분석
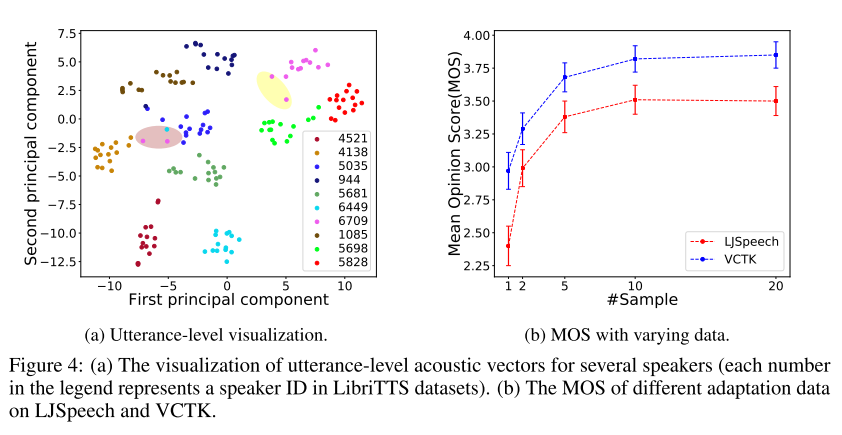
학습된 화자들의 utterance-level acoustic vector를 t-SNE로 나타낸 결과가 위의 그림 4(a)와 같다. 동일한 화자가 발음한 다른 문장들이 같은 군집으로 분류되어 있는 것을 확인할 수 있고, 이로부터 한 화자가 문장을 말할 때 가지는 고유한 특징을 모델이 잘 학습한 것으로 판단된다. 몇몇 예외들도 보이긴 하는데 이 문장들은 대개 짧거나 감정적인 음성이기 때문에 다른 화자의 발화와 구분하기가 힘든 경우라고 한다.
Conditional Layer Normalization 분석

speaker embedding을 컨디셔닝하지 않고 scale, bias를 fine-tuning 한 경우와 디코더의 다른 파라미터들을 fine-tuning한 경우를 비교해 봤을 때 Conditional Layer Normalization을 사용한 경우의 음성 품질이 가장 좋다는 것을 알 수 있다. 그러므로 layer normalization을 수행해줄 때 scale과 bias를 화자의 특징을 반영해 수정해주는 것이 좋고 이들만을 업데이트 하는 것이 모델의 적응 능력에 긍정적인 영향을 끼치는 것으로 종합해 볼 수 있겠다.
적응 데이터의 양에 따른 품질 평가
마지막으로 새로운 화자의 음성 데이터가 얼마나 필요한지 테스트 해보는 실험을 진행하였다. 그림 4(b)를 보면 알 수 있듯이 10개 샘플을 사용할 때까지는 성능이 급속도로 향상되지만, 그 이후부터는 큰 개선이 보이지 않으므로 화자별 10개만 사용해도 된다고 판단된다.
의견
- 논문에서는 phoneme-level acoustic encoder와는 다른 predictor를 사용한다는 식으로 서술하고 있지만, predictor를 따로 학습시키는 과정에 대한 언급이 없기 때문에 학습시킨 encoder의 파라미터를 고정시키고 이를 추론 시에 predictor로 활용하는 것을 그렇게 표현한게 아닌가 싶다.
- 화자별 10개 샘플만으로도 맞춤 음성 TTS가 가능한 모델이라는 점에서 활용 가치가 무궁무진하다고 생각한다.




Leave a comment