
AdaSpeech 2
Yan, Yuzi, et al. “AdaSpeech 2: Adaptive text to speech with untranscribed data.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
들어가며
특정 화자의 목소리를 합성하기 위해 기존의 TTS 적응 방식은 텍스트-음성 쌍의 데이터를 사용해 왔다. 그렇지만 데이터를 쌍으로 확보하는 것이 어렵기 때문에 전사가 안된 음성 데이터만으로 TTS 모델을 학습시킬 수 있다면 훨씬 효율적인 방법이 될 것이다. 가장 쉽게 접근해 볼 수 있는 방법으로 음성의 전사를 위해서 ASR 시스템을 활용하는 것을 생각할 수 있겠으나 특정 상황에서는 적용이 어렵고 인식 정확도도 충분히 높지 않기 때문에 부정확한 전사로 인해 최종 적응 성능을 저하시킬 수 있다. 그리고 TTS 파이프라인과 적응을 위한 모듈을 함께 joint training하는 방식으로 이 문제를 해결하고자 하는 시도들이 있었는데 이런 훈련 방식은 다른 상용 TTS 모델들과 쉽게 결합시킬 수 없다는 단점을 안고 있다.
따라서 본 논문에서는 어떤 TTS 모델이든 함께 결합시킬 수 있는 추가 모듈을 설계하여 전사가 안된 음성으로 학습을 가능하게 하고(pluggable), 이로부터 텍스트-음성 쌍 데이터로 적응시킨 TTS 모델의 성능과 동등한 수준의 결과를 낼 수 있음을 보인다(effective).
핵심 요약
- AdaSpeech의 구조에 Mel Encoder를 추가 모듈로 붙여서 음성 데이터만을 활용하여 특정 화자에 대한 음성을 적응시킬 수 있도록 유도하였다.
- Mel Encoder의 잠재 공간이 Phoneme Encoder의 잠재 공간과 유사해지도록 학습시켜서 Mel Decoder 입장에서는 입력이 텍스트로 들어오든 음성으로 들어오든 상관없이 같은 피쳐를 받을 수 있다. 이는 사전 학습된 TTS 모델에 음성 데이터만을 입력으로 넣어줘야 하는 상황에 적합하다.
- AdaSpeech 2의 방식은 어떤 TTS 모델이든 붙여서 활용할 수 있으며 텍스트-음성 쌍 데이터로 특정 화자를 적응시킨 모델들과 비슷한 성능을 낼 수 있다.
모델 구조
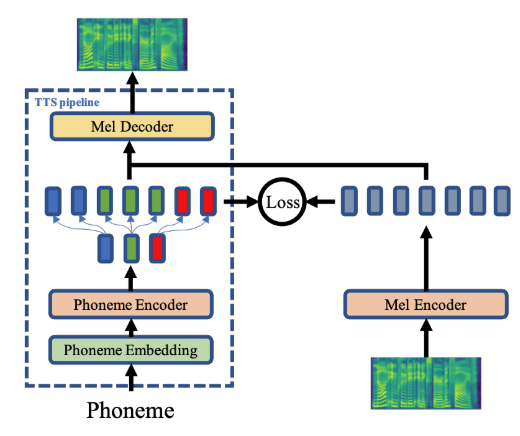
논문 제목에서도 알 수 있듯이 AdaSpeech를 backbone 모델로 사용한다. 여기에 음성 데이터를 받아서 인코딩하는 Mel Encoder를 추가하고 이를 Phoneme Encoder의 출력과 비슷하게 만들 수 있도록 L2 loss를 적용한다. 자세한 학습 과정은 아래에서 설명하겠다.
학습 과정
소스 모델 훈련
우선 소스 모델을 잘 훈련시키는 것이 중요하다. 충분한 양의 텍스트-음성 쌍으로 AdaSpeech 모델의 Phoneme Encoder와 Mel Decoder를 훈련시킨다.
Mel Encoder 정렬
잘 훈련된 소스 모델을 얻었다면 여기에 비전사 음성 적응을 위한 Mel Encoder를 붙인다. 최종적으로 음성의 오토 인코딩을 하면서 Mel Decoder의 입력으로 들어갈 피쳐를 만들어주는 역할을 하는데 전사 데이터로부터 나온 피쳐와 동일한 출력을 내뱉어야 하므로 우선 Phoneme Encoder의 잠재 공간과 동일하도록 만들어줄 필요가 있다. 그래서 텍스트-음성 쌍 데이터를 활용해 TTS 학습을 다시 진행하면서 Phoneme Encoder에서 나온 시퀀스와 Mel Encoder에서 나온 시퀀스 사이의 L2 loss를 구하고 이를 최소화 시키면서 둘 사이 잠재공간이 정렬되도록 유도한다. 이때, 전체 구조를 다시 훈련시키는 것이 아니라 소스 모델의 파라미터는 고정시키고 Mel Encoder의 파라미터만 업데이트하기 때문에 이 방식을 pluggable하다고 표현할 수 있다.
비전사 음성 적응
이제 합성하고자 하는 특정 화자의 (비전사된) 음성 데이터만을 활용하여 모델을 fine-tuning한다. 입력으로 들어온 음성이 Mel Encoder와 Mel Decoder를 거쳐서 다시 음성으로 합성되므로 오토 인코딩을 통한 음성 복원 방식이며, 이때는 소스 모델 Mel Decoder의 conditional layer normalization과 관련된 파라미터만 업데이트를 시켜주며 연산을 최소화한다.
추론
위의 적응 과정이 모두 끝났다면 이제 모델은 텍스트가 입력으로 들어왔을 때 fine-tuning 되지 않은 Phoneme Encoder와 부분적으로 fine-tuning된 Mel Decoder를 통해서 특정 화자의 음성을 흉내낼 수 있다.
실험 결과
적응 음성의 품질
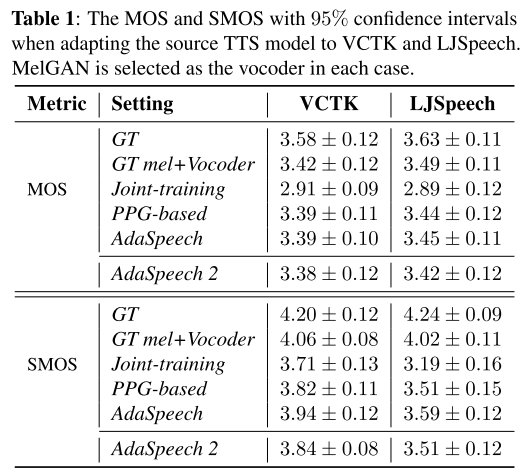
joint-training은 Mel Encoder와 Phoneme Encoder를 동시에 학습시키는 방식으로 본 실험에서 베이스라인으로 쓰이는 세팅이며, 이를 AdaSpeech 2와 비교하여 순서대로 학습시키는 전략의 우월성을 평가해 볼 수 있다. 백본으로 쓰인 AdaSpeech와 PPG-based 모델의 성능은 AdaSpeech 2의 성능이 뛰어 넘어야 할 상한으로 고려되어 함께 비교하는 실험을 진행했다. MOS와 SMOS 결과를 봤을 때 AdaSpeech 2는 베이스라인의 성능을 뛰어 넘고 상한으로 여겨지는 모델들과 거의 동등한 품질의 음성을 합성하는 것을 알 수 있다.
적응 전략에 대한 분석

앞서 학습 과정에서 언급한 전략들이 모델의 성능 향상에 기여했는지 평가하기 위해 ablation study를 진행했다. 결과적으로 Phoneme Encoder-Mel Encoder 사이에 L2 loss를 제약으로 설정한 것을 제거하거나 fine-tuning 단계에서 Mel Encoder도 함께 업데이트하게 된다면 음성의 품질이 안좋아진다.
적응 데이터 양에 따른 합성 품질 변화
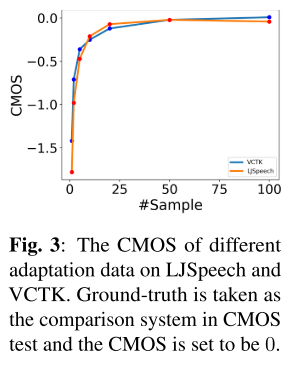
적응 음성 데이터가 20보다 적을 때는 데이터의 양이 증가할수록 합성 품질이 크게 좋아지지만 그 이상으로 가면 유의미한 품질 향상이 나타나지 않는다.
의견
- TTS 모델을 학습시키기 위해서 텍스트-음성 쌍의 데이터를 수집하는 것이 항상 고된 작업인데 특정 화자를 위한 적응 단계에서만이라도 음성 데이터만 활용할 수 있는 모델이 나와서 매우 반갑고 현실적으로 적용되기 쉬운 모델이라고 생각한다.
- L2 loss외에 다른 distance 함수를 제약으로 줬을 때 나타나는 성능 변화도 궁금하다.

Leave a comment