
AdaSpeech 3
Yan, Yuzi, et al. “AdaSpeech 3: Adaptive text to speech for spontaneous style.” arXiv preprint arXiv:2107.02530 (2021).
들어가며
TTS 모델이 발전하면서 책이나 스크립트를 읽는 것처럼 딱딱한 발화(reading-style speech)는 잘 합성할 수 있게 되었지만, 대화나 팟캐스트와 같이 자연스러운 발화(spontaneous-style speech)는 여전히 합성이 어려운 상황이다. 이런 발화에 대한 합성이 어려운 이유로는 자연스러운 발화 데이터의 부족, filled pauses(um, uh)나 다양한 리듬에 대한 모델링의 어려움이 있다.
그래서 AdaSpeech 3는 reading-style로 사전 학습된 TTS 모델을 fine-tuning 하여 filled pauses를 적당히 삽입하면서 다양한 리듬과 특정 화자의 음색을 가지고 자연스러운 음성을 합성해내는 방법을 제안한다. AdaSpeech를 backbone 모델로 하지만 이 위에 새로운 모듈이 추가되었고 이 모듈들의 효율적인 학습을 위해서 데이터셋을 직접 구축하였다고 한다.
핵심 요약
- 자연스러운 음성의 핵심인 filled pauses(FP)를 합성해내기 위해서 모델 내부에 FP predictor를 설계하여 적용하였으며 FP predictor의 threshold를 조절해서 합성된 음성 내 FP의 빈도를 조절할 수도 있다.
- 같은 문장이라도 사람마다 다른 리듬으로 읽는 것에 착안해서 FastSpeech에서부터 내려져 오던 duration predictor 구조를 수정하여 mixture of expert(MoE) 기반의 duration predictor를 만들었다.
- reading-style의 음성 데이터만 존재하는 특정 화자에 대해서도 자연스러운 음성을 합성할 수 있고 이런 음성의 품질이 기존 적응 모델의 품질보다 좋다.
모델 구조
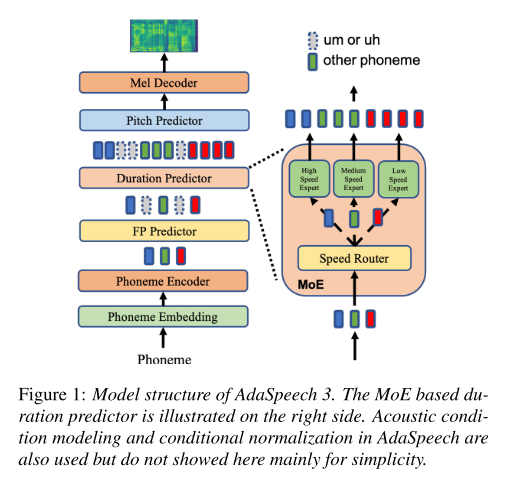
AdaSpeech 구조에 FP predictor가 추가되었고 기존의 duration predictor가 MoE based duration predictor로 수정되었다. FP predictor는 2-layer 1D CNN 구조로 이루어져 있고 phoneme의 hidden sequence를 받아서 어떤 phoneme의 뒤에 FP가 등장할지 예측하는 역할을 한다. MoE based duration predictor는 phoneme-speed tag(low, medium, high) 데이터로 학습된 speed router를 거쳐서 나온 확률 값을 weight로 하여 3개의 expert 네트워크 출력의 가중 평균으로 duration을 계산한다.
학습 과정
가장 먼저 소스 모델을 학습시킨다. forced-alignment tool로부터 추출된 GT duration과 별도로 추출한 GT pitch로 duration predictor와 pitch predictor를 각각 학습시킨다. 그 다음 FP predictor를 추가해서 FP를 예측할 수 있도록 훈련시키는데 이때 SPON-FP라는 별도로 구축한 text-FP 쌍의 팟캐스트 데이터셋을 사용한다.
이렇게 FP 적응 과정이 끝났으면 리듬 적응 과정을 진행하는데 pitch와 duration 적응의 두 가지 과정으로 나뉜다. pitch 적응은 단순한 fine-tuning으로 이루어지는 반면, duration predictor는 다양한 리듬에 적응시키기 위해 MoE based duration predictor로 변형시켜 학습을 시킨다. MoE based duration predictor에서는 먼저 speed router를 학습시켜서 해당 phoneme의 speed를 low, medium, high 3개의 확률 값으로 예측하도록 한다. 그리고 3개의 speed expert 네트워크는 각 speed tag에 맞는 phoneme을 입력 받아서 최종적으로 GT duration을 출력하도록 학습시킨다. pitch와 duration 적응에 쓰이는 데이터셋은 위와 마찬가지로 자체적으로 구축한 SPON-RHYTHM이다.
마지막으로 화자의 음색에 대한 적응 과정을 거친다. SPON-TIMBRE라는 데이터셋을 사용해서 AdaSpeech 모델 구조 내의 conditional layer normalization과 speaker embedding을 fine-tuning한다. 이 과정으로부터 어떤 유형(reading-style or spontaneous-style)의 특정 화자에 대해서도 자연스러운 음성을 합성할 수가 있다.
실험 결과
합성 품질 평가
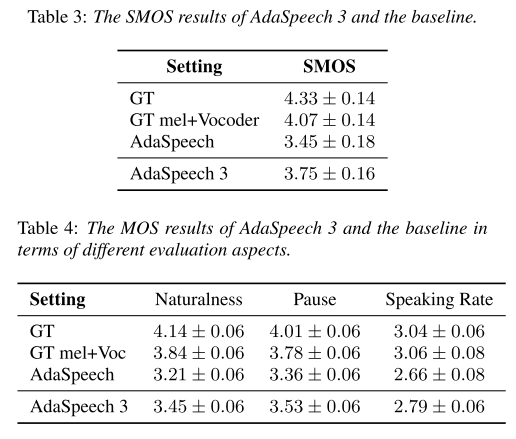
AdaSpeech 3의 합성된 음성이 실제 화자의 음성과 비슷한지 SMOS로 평가했고 음성의 자연스러움, 정지 부분, 말의 속도 등을 척도로 MOS를 평가했을 때 위와 같은 결과가 나왔다. 베이스라인인 AdaSpeech보다 자연스러운 음성을 합성하고 있음을 알 수 있다.
Ablation study
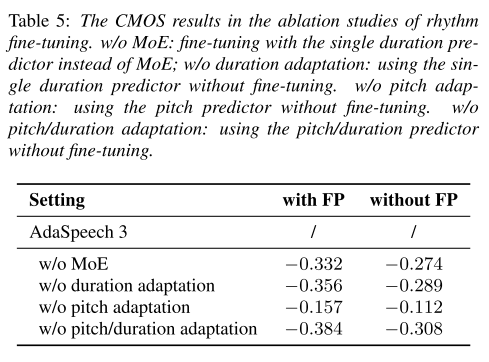
본 논문에서 contribution이라 주장하는 부분들을 제거해보면서 품질 평가를 진행했다. 먼저 duration predictor를 3개의 expert network 없이 single duration predictor로 구성했을 때(w/o MoE), 성능이 저하되었으므로 MoE 디자인이 자연스러운 발화에 기여했음을 알 수 있다. 그리고 single duration predictor에 대해서 fine-tuning 없이 소스 모델의 파라미터를 그대로 사용했을 경우(w/o duration adaptation), 성능 하락이 더 컸기 때문에 fine-tuning에 대한 정당성도 얻을 수 있다. pitch predictor에 대한 fine-tuning 역시 제거했을 때(w/o pitch adaptation) 성능 하락이 일어났으나 duration에 비해서는 미미한 수준이었고 duration predictor와 pitch predictor의 fine-tuning을 모두 제거했을 때는 성능이 심각하게 하락하는 것이 확인된다. 한 가지 흥미로운 점은 위의 ablation study 모두 FP predictor를 결합한 경우와 아닌 경우에 대해서 실험을 진행해봤는데 모두 FP를 예측하는 경우에 성능 하락이 더 크게 나타났다. 이로부터 FP를 예측하는 것과 리듬 fine-tuning은 함께 이루어질 때 높은 시너지를 낼 수 있는 상호보완적인 관계라는 것을 알 수 있다.
발화 스타일 전환
화자간 발화 스타일 전환이 가능한지 실험해 보았다. 즉 오로지 적은 양의 reading-style 데이터로만 fine-tuning을 진행한 화자에 대해서 자연스러운 스타일의 발화 음성이 잘 합성될 수 있는지 실험하였는데 AdaSpeech보다 남성과 여성 모두에 대해서 더 좋은 품질의 음성이 합성되었다.
의견
- 자연스러운 발화의 특성을 간단하게 규정 짓고 이런 음성을 합성하기 위해 알맞는 데이터셋을 구축한 것이 인상적인 연구다. 어떤 태스크이든 잘 갖춰진 데이터가 중요한데 처음으로 이런 데이터를 만든 것은 큰 업적이라 보여지고 추후의 연구를 위해 공개해주면 좋을 것 같다.
- 합성 속도가 빠른 FastSpeech의 장점을 그대로 가져가면서 이를 실용적인 모델로 발전시키려는 시도들이 계속 나타나고 있는데 이렇게 변형된 모델들의 합성 속도에 대한 실험 결과는 명시되지 않아서 아쉽다.
- speed router를 학습시키기 위해서 입력으로 들어온 phoneme에 3가지의 speed tag를 달아야 하는데 어떤 기준으로 low, medium, high speed를 구분하였는지 명시해주면 좋겠다.




Leave a comment