
Sifan Wu et al., Adversarial sparse transformer for time series forecasting, 2020
들어가며
시계열 예측에 많은 딥러닝 모델들이 사용되어 왔지만 두 가지 문제점이 있었다. 첫째, 오직 정확한 값 예측에 초점을 맞춘 나머지, 데이터의 무작위성을 고려하지 못했다. 둘째, auto-regressive 모델들(논문에서는 iterative model을 한정지어 말하는 것 같다.)은 훈련 시에는 target 값이 주어지지만, 추론 단계에서는 모델의 예측값이 이를 대체하기 때문에 오차가 누적되는 결과가 초래되어 긴 시간 간격의 값을 예측하는 것이 어렵다. 그렇기 때문에 이를 해결하고자 하는 노력의 필요성이 대두되었고 이 논문에서는 Sparse Transformer와 GAN의 조합으로 그 문제를 풀었다.
핵심 요약
- 시계열 예측 모델에 GAN을 사용한 최초 사례이다.(timeGAN은 시계열 데이터에 GAN을 적용한 최초 사례이나, 이는 예측에 초점을 두지 않고 과거 데이터 모델링에 초점을 뒀다는 것에 차이가 있다.)
- Sparse Transformer를 이용해 예측 구간과 관련 있는 시간 간격의 데이터에 더 큰 가중치를 주는 모델을 구현했고 이를 통해 예측 성능을 향상시킴.
- 시계열 예측 모델에 Adversarial training을 적용하면 기존 모델에 규제 효과가 생겨 sequence-level의 예측 성능이 높아짐.
문제 정의
전형적인 multi-horizon forecasting 문제를 가정하고 50th, 90th quantile regression 을 수행한다.
모델 구조
전체적인 구조는 아래와 같다.
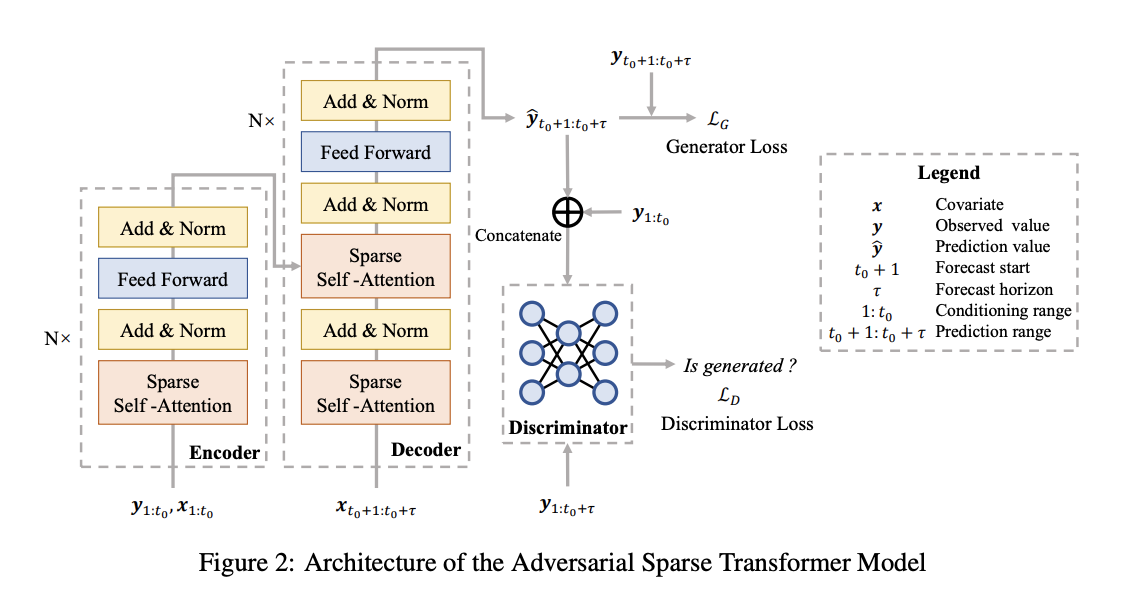
Sparse Transformer
기존의 Vanilla Transformer는 attention score가 softmax에 의해 계산되는데 이는 모든 attention score에 대해 non-zero 값을 return 하고 합이 1이 되어야 하는 성질에 의해 예측 구간과 관련된 시간 간격이더라도 작은 attention을 줄 수 밖에 없는 한계점을 지니고 있다. 이를 대신해 $\alpha-entmax$ 라는 transformation 방법(아래 그림 참조)을 사용하면 관련된 시간 간격에 높은 attention을 주고 관련이 없는 시간 간격에 대해서는 0을 부여하는 것이 가능하며 이렇게 구현된 모델이 Sparse Transformer이다.
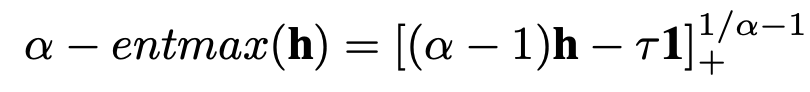
Adversarial Training

기본적인 GAN 훈련 방식과 동일하다. Generator인 Sparse Transformer를 먼저 quantile loss와 Discriminator에 의한
loss term을 더해 학습시키고, Discriminator를 가짜와 진짜 데이터를 분류하도록 cross entropy loss를 이용해 학습시킨다.
Discriminator는 모델 구조 그림에서도 볼 수 있듯이 3개의 dense layer를 이용해 간단하게 구현되었으며, activation function으로 LeakyReLu를 사용했다.
손실 함수
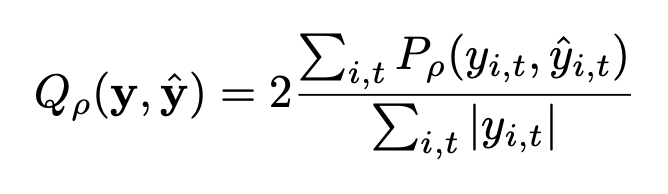
TFT와 동일한 normalized quantile loss를 사용했다.
예측 성능
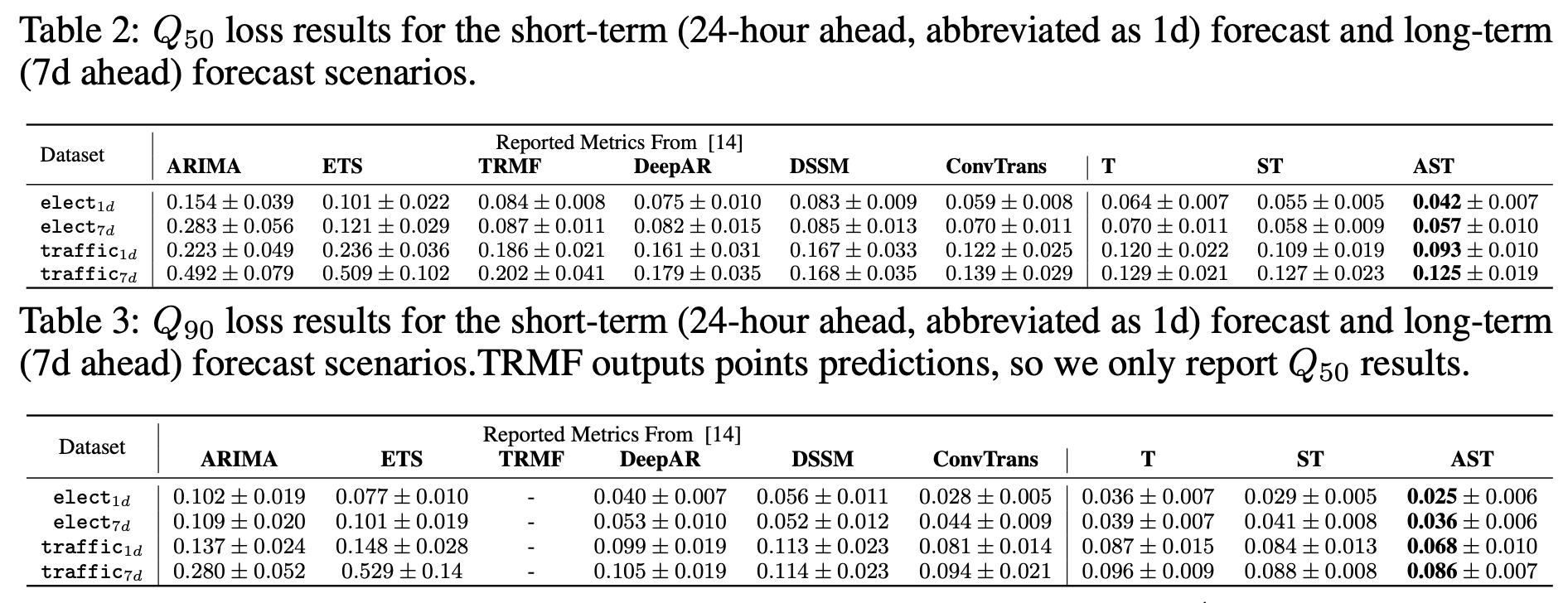
quantile, 예측 구간의 길이, 데이터셋에 상관 없이 Adversarial Sparse Transformer(AST)가 가장 좋은 성능을 보인다.
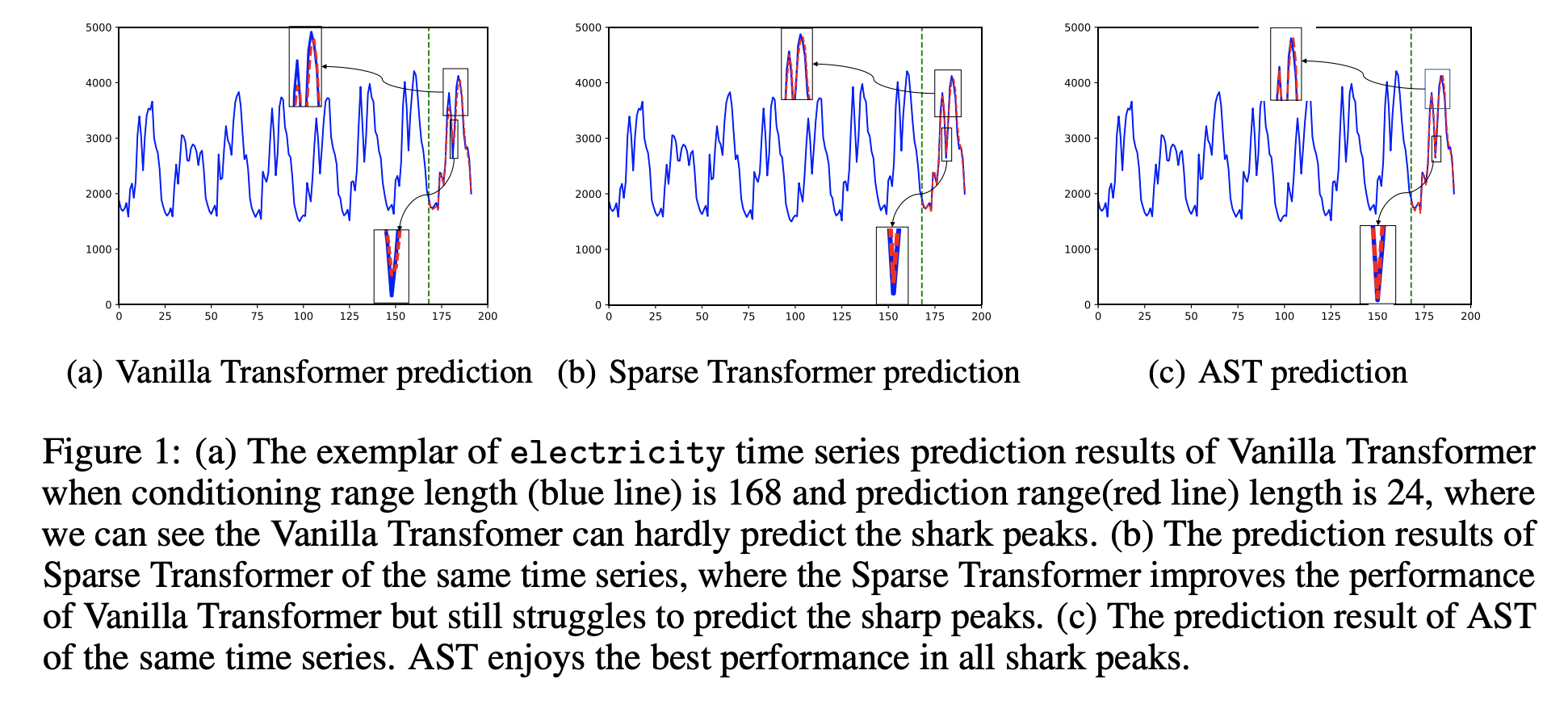
게다가 예측 구간에서 shark peak를 AST가 가장 잘 예측하는 것으로 보아 sequence-level의 regularization이 효과를
보았음을 알 수 있다.

$\alpha$ 값에 따른 성능은 위와 같이 $\alpha=1.5$일 때 극대화되는 것을 알 수 있다.
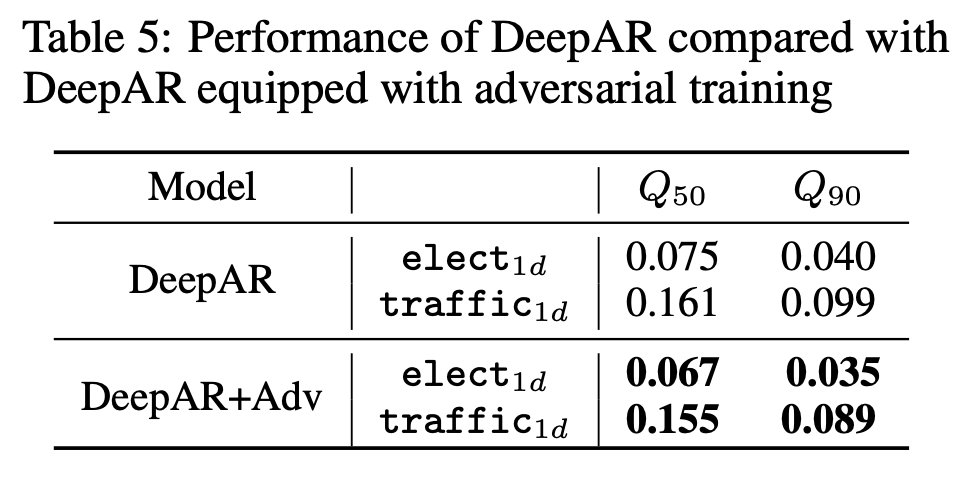
Transformer 모델이 아닌 DeepAR 모델에 Adversarial training을 적용했을 때도 적용하지 않았을 떄보다 성능이 향상되는 것을 관찰할 수 있다.
결론
시계열 예측에 Transformer 모델이 우수한 성능을 보이는 것은 이전에도 증명되었지만, Sparse Transformer로 변형시키고 GAN의 학습방식을 차용하면서 성능을 많이 끌어올릴 수 있는 것을 보여준 논문이다. Sparse Attention 방식에는 다른 방법도 존재하기 때문에 앞으로 Sparse Transformer 분야는 계속 연구가 진행되어야 할 것 같고, adversarial training은 당장 다른 시계열 예측 모델들에도 적용 가능할 것이다. 다만 학습이 어렵기로 유명한 GAN이기 때문에 본래 모델의 특성에 따라 hyperparameter tuning을 새롭게 해주는 과정에 많은 시행착오가 예상된다.

Leave a comment