
Almost Unsupervised Text to Speech and Automatic Speech Recognition
Ren, Yi, et al. “Almost unsupervised text to speech and automatic speech recognition.” International Conference on Machine Learning. PMLR, 2019.
들어가며
TTS와 ASR은 음성 처리 분야의 유명한 두 가지 태스크로, 딥러닝이 발전함에 따라 많은 관심을 받고 있다. 현재 딥러닝에 기반한 TTS와 ASR의 state-of-the-art(SOTA) 모델들은 모두 많은 데이터를 필요로 하는데 음성-텍스트 쌍 데이터가 부족한 언어들에는 적용하기 어렵다는 단점을 갖고 있다. 그래서 low-resource, zero-resource ASR과 TTS 기술들이 최근에 많이 제안되고 있지만 ASR을 할 때는 TTS로부터 추가적인 정보를 활용하지 않거나 특정 태스크에만 적합한 알고리즘을 사용하여 TTS와 결합하기 어렵고, 적은 샘플로 특정 화자의 TTS를 할 때는 이미 레이블링된 다량의 다른 화자 데이터를 사용한 transfer learning의 방식으로 접근하며 unsupervised learning으로 접근한 사례가 없다. 또한 TTS와 ASR을 speech chain 내에서 동시에 부스팅시키는 연구에서는 이미 잘 훈련된 TTS, ASR 모델을 unpaired 데이터로 부스팅시켜주는 것이기 때문에 low-resource, zero-resource 세팅에는 맞지 않다.
본 논문에서는 TTS와 ASR이 dual nature(서로 역방향의 문제를 풀고 있음)를 가진다는 것에 착안하여 (거의) unsupervised 방식으로 학습할 수 있는 통합 모델을 제안한다.
핵심 요약
- denoising auto-encoder를 사용해서 음성과 텍스트 도메인에서의 language modeling의 capacity를 높였다.
- dual transformation을 통해 ASR과 TTS가 서로의 output을 input으로 받아 학습에 사용하도록 유도하여 학습 데이터를 늘려주는 효과를 얻었고 이로부터 각 태스크의 정확도를 향상시켰다.
- bidirectional sequence modeling으로 긴 음성과 텍스트 시퀀스를 다루는 경우에 생길 수 있는 error propagation 문제를 완화하였다.
모델 구조
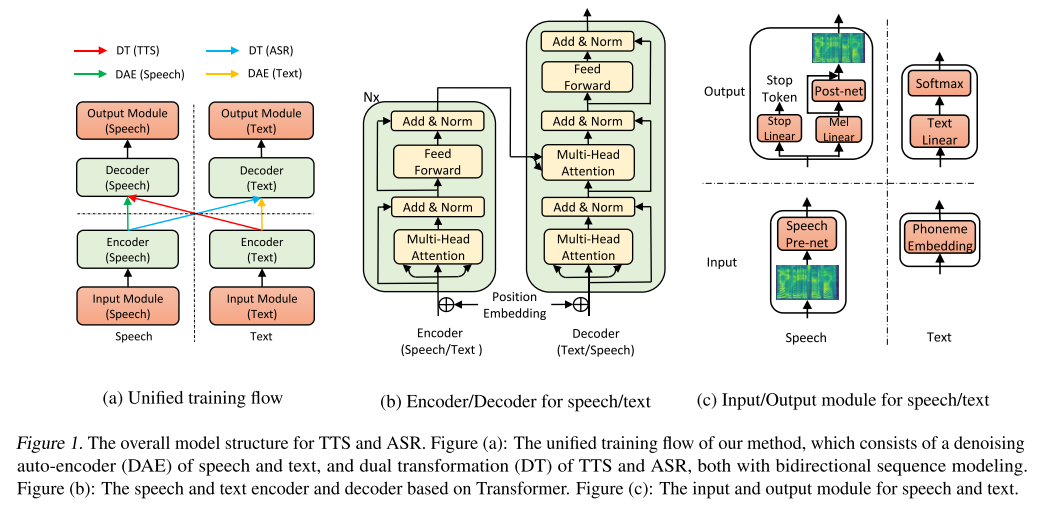
전체적인 모델은 Transformer에 기반한다. 음성과 텍스트가 각각 다른 경로로 모델에 주입되어 인코더와 디코더를 통해 음성 혹은 텍스트로 출력된다. 입출력 모듈과 인코더, 디코더의 구조는 그림 1에 나타난 바와 같다. 모델은 꽤 단순한 편이지만 이를 TTS와 STT 모두 잘 할 수 있도록 학습시키는 방식이 조금은 까다로운데 지금부터 차근차근 알아보겠다.
학습 방법
모델을 학습시키는 방식은 그림 1(a)에 요약되어 있고 각 구성요소들을 자세히 살펴보겠다.
Denoising Auto-Encoder(DAE)
먼저 DAE가 모델을 학습시키기 위한 핵심 요소로 쓰이고 있는데 이는 self-supervised learning이나 unsupervised learning 연구에서 많이 사용되는 방법이다. 본 연구에서는 약간의 paired 데이터를 제외한 대부분의 데이터가 unpaired 상태이므로 이렇게 정답이 없는 다량의 음성과 텍스트 데이터로부터 어떻게 표현을 추출하고(representation extraction), 임베딩을 생성해낼지(language modeling)가 중요하다. DAE를 이용하면 약간 변형된 음성이나 텍스트로부터 원본을 복원해내는 과정을 통해서 이 단계를 해결할 수 있다. DAE를 학습시키기 위한 손실 함수는 아래와 같다.
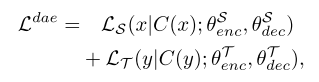
위 식에서 C는 corrupt operation으로, 시퀀스의 특정 부분을 랜덤으로 정해서 zero vector로 마스킹하는 역할을 한다. 그리고 이때 타겟 음성과 텍스트에 대한 손실 함수는 각각 MSE와 NLL을 사용한다.
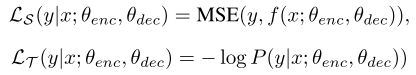
Dual Transformation(DT)
TTS와 ASR 태스크의 dual nature를 최대로 활용하는 중요한 부분이다.
음성을 ASR 모델을 통과시켜서 텍스트를 예측하고, 이렇게 (예측된)텍스트-음성 쌍을 TTS 모델 학습에 사용하는 방식이다. 물론 반대로도 진행한다. DT는 기계 번역에서 쓰이던 back-translation과 유사한 역할을 하고, 손실 함수는 아래와 같이 두 파트로 구성된다.
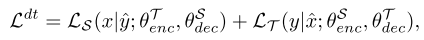
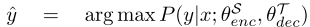
이렇게 DT를 활용하게 되면 새로운 데이터가 각 태스크 학습에 쓰이는 꼴이 되기 때문에 성능 향상에 도움이 된다.
Bidirectional Sequence Modeling(BSM)
seq2seq 모델들은 대부분 error propagation 문제를 겪게 되는데 특히 일반적인 기계 번역 태스크보다 길이가 긴 시퀀스를 다루는 TTS나 ASR에서는 이 문제가 두드러질 수 밖에 없다. 저자들도 DT를 이용해 실험할 때, 생성된 텍스트나 음성의 끝 부분(right-part) 품질이 많이 안좋아지는 것을 확인했다고 한다. 그리고 이를 해결할 수 있는 방안으로 BSM을 제안한다. 양방향으로 시퀀스를 생성해내기 때문에 시퀀스의 left-part와 right-part간의 밸런스를 맞출 수 있고 이는 data augmentation 효과를 가져다 줄 수 있으므로 적은 양의 paired 데이터를 사용하는 상황에서 매우 도움이 된다.
BSM을 사용하게 되면 DAE와 DT에 모두 적용해줘야 하므로 손실 함수는 아래와 같이 변형된다.
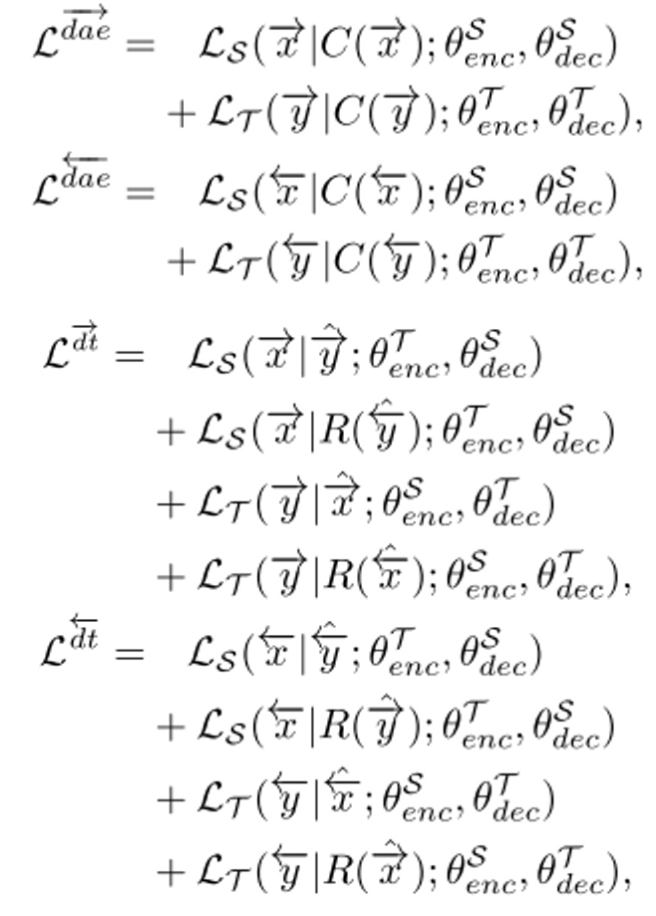
여기서 R은 시퀀스의 순서를 뒤집어주는 reverse function이다.
그리고 위처럼 고안된 BSM은 입력과 출력의 시퀀스 방향만 바꿔주면 되기 때문에 한 가지 모델로 학습될 수 있다. 보통 생성될 시퀀스의 방향을 알려줄 때 첫 번째 원소에 zero vector를 넣어주는 것과 달리 저자들은 학습 가능한 임베딩 벡터를 사용한다. 훈련과 추론 시에 left-to-right, right-to-left의 방향을 임베딩 벡터로 제공해주고 이들을 speech generation과 text generation 과정에 따라 나누어 배워야 하기 때문에 총 4개의 임베딩 벡터를 학습해야 한다.
Unified Training Flow
paired 데이터를 이용해서 supervised 방식으로 학습을 진행하며 손실 함수는 아래와 같다.
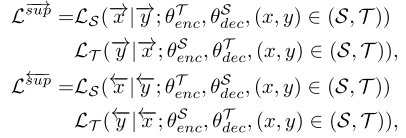
따라서 본 모델을 학습시키는 데 필요한 최종 손실 함수는 다음과 같이 쓸 수 있다.
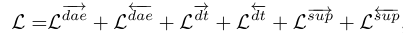
배치를 구성할 때는 DAE를 학습하기 위한 데이터, DT를 학습하기 위한 데이터, 그리고 paired 데이터가 1:2:1의 비율로 들어가 학습이 진행되며 paired 데이터는 unpaired 데이터의 양과 비슷한 수준으로 upsampling을 진행했다.
실험 결과
베이스라인 비교
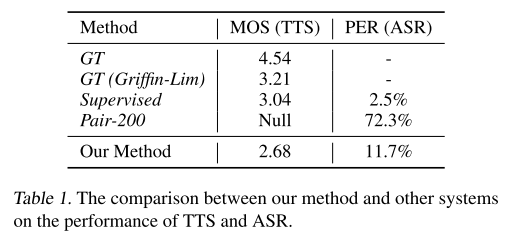
paired 데이터 200개만 사용한 베이스라인보다 MOS와 PER 모두 좋은 성능을 보여주지만 supervised 방식으로 학습한 경우보다는 안좋은 결과를 보인다.
Ablation Study
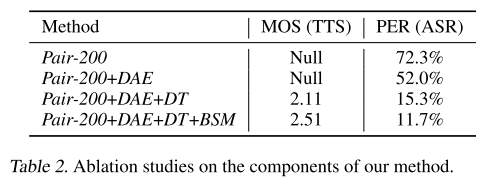
ablation study를 해봤을 때 본 논문에서 제안하는 모든 컴포넌트들을 포함했을 때 성능이 가장 좋게 나온다. 여기서 DAE까지만 적용했을 때는 알아듣기 힘든 음성이 생성되지만 DT를 통해서 학습 데이터를 늘리는 효과를 얻은 뒤에는 알아들을 수 있는 음성이 생성된다는 것을 알 수 있다.
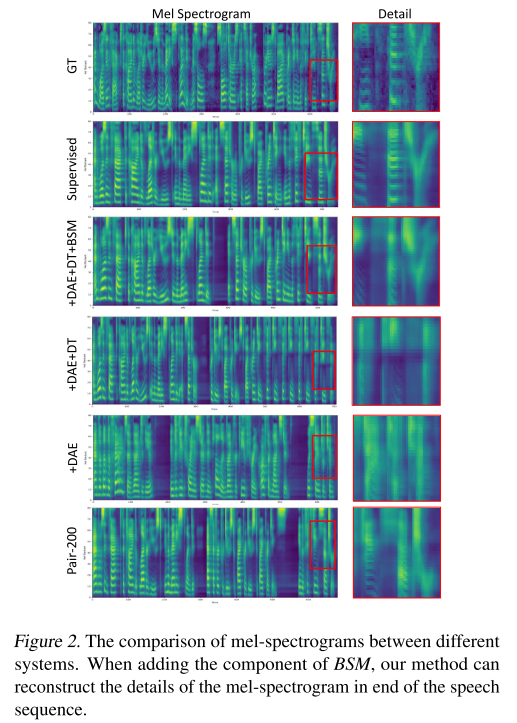
ablation study에 따른 멜 스펙트로그램은 그림 2와 같다. BSM을 적용하기 전의 모델들은 모두 GT 멜의 디테일한 특징을 잡아내지 못하는 모습을 보인다.
Varying Paired Data

학습에 사용한 paired 데이터 수를 늘려가면 MOS와 PER이 모두 향상되는 것이 관찰된다.
Different Masking Probabilities in DAE

앞서 DAE에서 시퀀스에 무작위로 마스킹을 사용한다고 했는데 그 비율을 조절해보면서 실험해봤을 때 0.3일 때 가장 좋은 PER을 보였다.
의견
- 한 가지 모델로 TTS와 STT(ASR)를 모두 할 수 있게 설계한 것이 인상적이다.
- SSL 모델이 각광받기 전, 모델의 성능을 향상시킬 수 있는 기법이 다양하게 적용되었고 실험에 대한 분석도 훌륭하다.

Leave a comment