
들어가며
딥러닝의 발전으로 더 유용하고 사람의 지식에 크게 의존적이지 않은 표현을 학습하는 것이 가능해졌다. 이 논문에서는 특히 Speech 분야에서 이루어지고 있는 표현학습(Representation Learning) 연구들을 정리할 것이며 크게 Automatic Speech Recognition(ASR), Speaker Recognition(SR), Speaker Emotion Recognition(SER)의 범주로 나뉘어 있다.
배경지식
전통적인 feature learning 알고리즘으로 PCA, LDA, CCA, LLE, t-SNE 등이 각광을 받았지만 딥러닝이 발전하면서 최근에는 3 종류의 generative model(VAE, GAN, deep auto-regressive model)이 상당한 관심을 받고 있다.
Speech feature로 log-mel spectrogram이 많이 쓰이지만 몇몇의 연구에서는 feature를 잘 선택하는 것보다 모델 구조를 디자인하고 많은 훈련 데이터를 확보하는게 중요하다고 말한다.
데이터셋
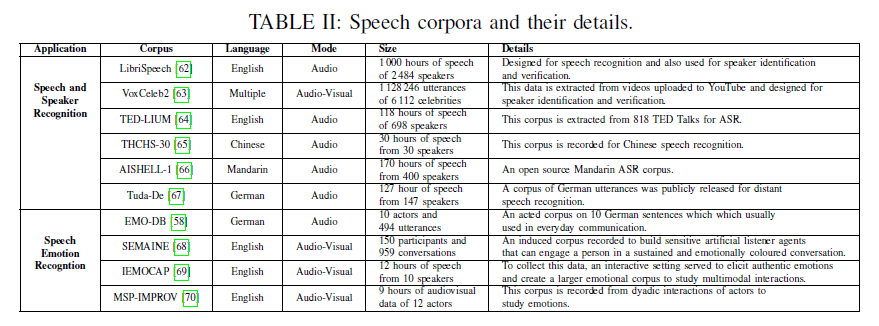
Vision 분야와 다르게 Speech 연구는 작은 데이터셋에 대한 DNN 연구로부터 시작되었다.
평가지표
- word error rate(WER): ASR의 성능을 측정하는 데 쓰이며, (insertion+deletion+substitution)/(total # of words) 으로 계산한다.
- false rejection(fr), false acceptance(fa): SR의 성능 측정에 쓰이며, 이 2개의 지표를 이용해 detection error trade-offs(DETs) curve를 그린다.
이 밖에도 equal error rate(EER), ROC curve 등을 사용하며 SR과 SER 연구에서는 분류 정확도가 평가지표로 쓰인다.
Representation Learning의 적용분야
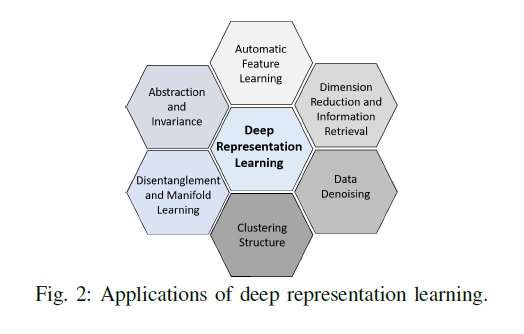
noise의 분포가 항상 알려져 있는 것이 아니기 때문에 data augmentation이 항상 도움이 되는 것은 아니다.
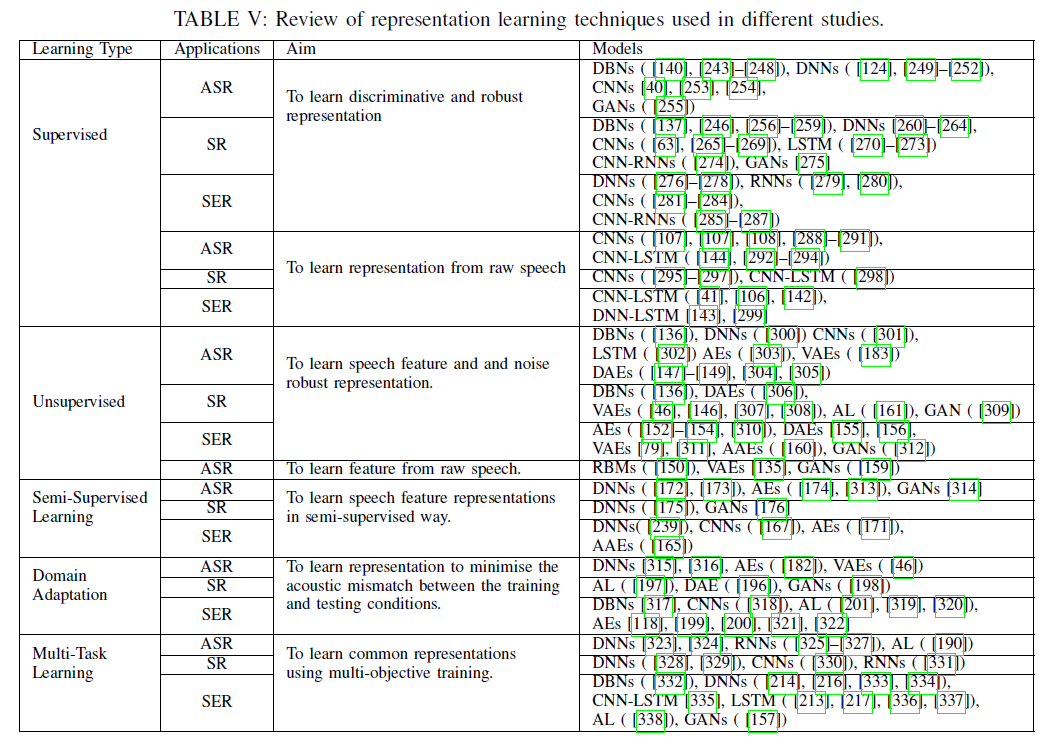
Representation Learning 모델
DNN, CNN, RNN, Autoencoder(AE), Deep Generative Models
-
RNN: 단순한 RNN은 vanishing gradient problem 때문에 긴 시간 간격을 가진 사건을 모델링하는 데 실패한다. 따라서 LSTM, GRU 구조가 나오게 되었고 ASR의 state-of-the-art(SOTA)는 LSTM 구조를 사용하고 있다.
- AE: encoder, decoder 네트워크를 가지며 reconstruction error를 최소화하는게 목표이다. AE가 identity function을 학습하는 상황을 방지하기 위해 여러 제약조건을 추가한 형태들이 있다.
- Undercomplete Autoencoders: embedding size를 작게끔 강제하는 방식이다.
- Sparse Autoencoders: hidden unit의 평균 활성도와 의도한 sparsity(ρ)간의 KL divergence를 loss function(기존의 reconstruction error)에 더해준다. denoising autoencoder(DAE)나 RBM보다 학습시키기 간편하고 표현을 더 잘 학습한다고 알려져 있다.
- Contractive Autoencoders: 무한히 작은(infinitesimal) 입력의 변동에 강건성을 가지는 유용한 표현을 학습하도록 강제한다.
- Deep Generative Models: 어떤 형식의 데이터(audio, image, video)에 대해서도 분포를 학습할 수 있으며, 새로운 데이터 포인트를 생성하는게 목표이다.
- BM, DBN: DBN은 여러 RBM 층으로 구성되어 있는데 RBM은 training data의 log-likelihood를 최대화하기 위해 Markov Chain Monte Carlo(MCMC) 기반의 알고리즘을 사용한다. 이는 상당한 학습문제를 야기한다고 알려져 있다.
- GAN: Generator와 Discriminator라는 네트워크 구조로 구성되어 있고 이 두 네트워크 간의 min-max adversarial game을 통해 학습이 이루어진다.
- VAE: AE의 reconstruction error에 prior와 posterior간의 KL divergence를 뺸 것을 data loglikelihood의 lower bound로 했을 떄 이를 최대화하도록 학습하는 방식이다.
- Autoregressive Network: 이전 시점의 데이터를 입력으로 받아서 다음 시점의 데이터를 출력하는 모델이다. Speech 분야에서 WaveNet이 가장 유명하고 강력한 acoustic modelling capability를 가짐.
Representation Learning 방식
Supervised Learning
- 좋은 성능에도 불구하고 speech 관련 task의 label이 부족하기 때문에 한계가 있다.
Unsupervised Learning
- 상응하는 레이블이 없는 입력 데이터에 대해 본질적인 구조나 분포를 학습하는게 목표이다.
- ASR, SR에서 VAE가 가장 많이 쓰이며 VAE는 generative model과 inference model을 함께 학습할 수 있다.
- 최근에는 ASR, SR, SER의 모든 분야에서 adversarial learning(AL)이 가장 핫하다. GAN, adversarial autoencoder(AAE)가 이에 포함된다.
Semi-supervised Learning
- SER과 같은 task에는 이용가능한 large labelled database나 pre-trained network가 없다.
- semi-supervised learning은 이런 문제를 해결하며 large unlabelled data와 small labelled data를 사용한다.
- SER에서는 ladder network-based semi-supervised 방식이 가장 유명하다.
Transfer Learning
모델의 학습을 향상시키고 목표 task의 일반화를 도모하기 위해 다른 지식들을 활용하는 방법으로 3가지 테크닉이 있다.
- Domain Adaptation: training-testing mismatch를 제거하는게 목표이다. 여기서도 adversarial learning 방식이 인기를 얻고 있다.
- Multi-Task Learning: main task 뿐만 아니라 auxiliary task를 사용해 다양한 loss function을 optimizing 한다. 이를 통해 main task 성능을 향상시킬 수 있고, 추가적인 데이터를 얻지 않고 성능을 향상시키는 방식이다. ASR에서는 gender, speaker adaptation 등을 auxiliary task로 활용한다.
- Self-Taught Learning: semi-supervised 와 transfer learning을 합친 방식이다. audio 분야 연구는 아직 거의 없다.
도전과제
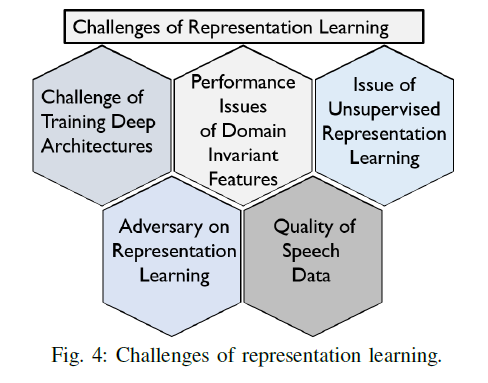
- unsupervised 방식은 매우 어렵다.
- GAN에서 minmax loss, Wasserstein loss 사용하면 vasnishing gradient, mode collapse 등의 문제를 해결할 수 있다.
- 언어에 상관없는 표현학습은 여전히 어렵다.
- adversarial attack에 취약하다. (예: SOTA ASR모델인 DeepSpeech가 attack에 100% 패배한 사례)
성과 및 트렌드
-
오픈소스 데이터셋과 툴킷이 있다.
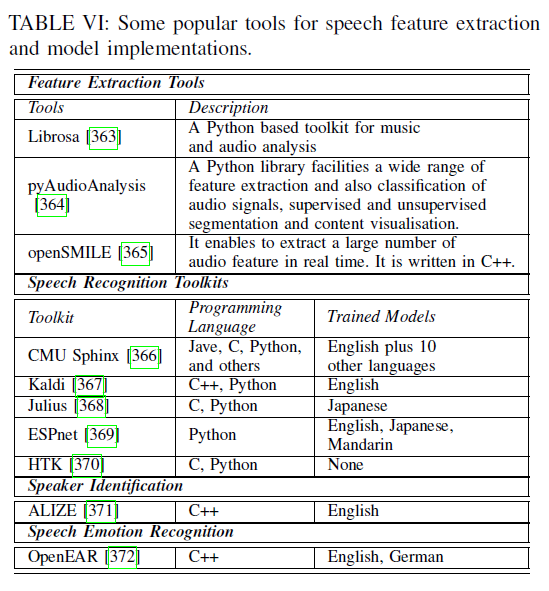
무료 데이터셋: VoxForge, OpenSLR
-
raw speech에 대해서도 바로 학습이 가능해졌다.
-
adversarial 학습이 뜨고 있으며 이는 large labelled data가 없는 SER 연구에 합성된 데이터를 제공해줌으로써 활용될 수 있다.
-
프라이버시를 지켜주는 표현학습 방식 연구가 뜬다. 한 가지 방법으로 다양한 컴퓨팅 기기에서 데이터를 공유하며 한 가지 글로벌 모델을 학습시키는 federated learning이 있다.
TO STUDY
- federated learning
- ASR 모델

Leave a comment