
High Fidelity Neural Audio Compression
Défossez, Alexandre, et al. “High fidelity neural audio compression.” arXiv preprint arXiv:2210.13438 (2022).
들어가며
실시간, 고품질을 추구하는 뉴럴 오디오 코덱 모델인 EnCodec 모델을 제안한다. EnCodec은 Discriminator를 여러 개 쓰지 않고, 스펙트로그램 기반 멀티스케일 Discriminator만 써서 학습 속도와 품질을 향상시킨다. 학습의 안정성을 위해서는 loss balancer를 새롭게 제안하면서 hyper-parameter인 loss의 가중치를 loss scale을 고려해서 주는 것이 아니라 전체 gradient 중 차지할 비율을 정의하도록 바꾼다. 그리고 가벼운 트랜스포머를 써서 양자화된 표현을 40% 가량 압축하면서도 실시간보다 빠른 속도를 유지할 수 있음을 보인다. EnCodec은 모노 오디오 뿐만 아니라 스테레오 오디오에서도 잘 작동함이 증명되었다.
핵심 요약
- MS-STFT Discriminator만 사용하여 학습 속도를 빠르게 하면서 복원된 오디오 품질도 향상 시킨다.
- loss balancer를 제안하여 학습을 안정화하고 loss의 가중치 설정에 의한 성능 저하를 최소화시킨다.
- 트랜스포머를 이용한 랭귀지 모델링과 엔트로피 코딩을 통해서 코덱 표현을 40% 가량 절약할 수 있다.
모델 구조
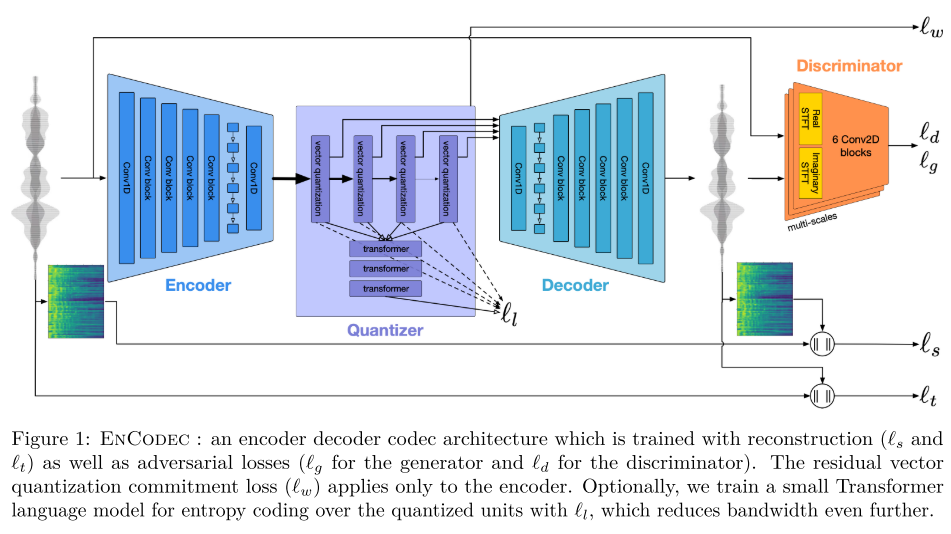
모델은 SoundStream과 유사하게 conv 기반으로 구성되어 있지만, Encoder와 Decoder 내부에 2-layer LSTM이 추가 되었고 이는 시퀀스 모델링을 위해 설계되었다. 모델이 low latency의 streaming을 목적으로 하는지 아니면 high fidelity를 목적으로 하는지에 따라 아래 두 가지 셋업이 존재한다.
- Non-streamable: convolution layer의 패딩을 앞뒤로 동일하게 구성한다. 입력 오디오는 10ms 오버래핑을 허용하면서 1초 단위의 청크로 자른다. 그리고 각 청크를 normalize를 진행하면서 스케일 정보를 저장하고 전달할 수 있는 아주 작은 오버헤드를 추가하여 Decoder에 전달한다. normalization 방법으로는 layer normalization을 사용한다.
- Streamable: convolution layer의 패딩을 앞에만 적용한다. 덕분에 모델은 13ms에 해당하는 320샘플을 받자마자 출력할 수 있다. 그리고 layer normalization 대신에 weight normalization을 사용한다.
RVQ를 위해서 사용하는 Quantizer는 SoundStream과 동일하고 비트레이트 세팅에 따라 24kHz 모델은 최대 32개, 48kHz 모델은 최대 16개 코드북을 사용한다. 만약, 코드북 사용이 유니폼 디스트리뷰션을 따른다면 단순한 코딩 방식이 최적이겠지만, 그렇지 않다. 따라서 이전 디코딩 정보를 활용해 코드북 확률 분포를 추정할 수 있다면 압축률을 높일 수 있다. 저자들은 작은 트랜스포머 (5 layers, 8 heads, 200 channels, 800 dim for FFT)를 사용하여 랭귀지 모델링을 통해 코드북 사용에 대한 확률 분포를 추정하고, range based arithmetic coder를 사용한 엔트로피 코딩(가변길이 코딩)으로 코드를 압축시켜 효율을 증대시킨다.
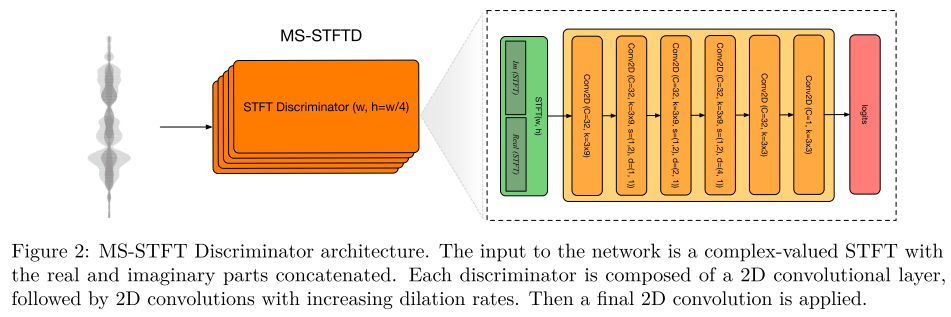
Decoder로 복원된 오디오의 perceptual quality를 향상시키기 위해 multi-scale STFT-based (MS-STFT) Discriminator를 사용한다. complex-valued STFT Discriminator와 동일한 구조를 가지는데 STFT를 수행할 때 window size를 다양하게 하여 여러 모델을 만든다. window size로는 2048, 1024, 512, 256, 128을 사용한다. activation으로는 LeakyReLU를 사용한다.
손실 함수
크게 reconstruction, perceptual, commitment loss term으로 나뉜다.
Reconstruction Loss
time domain loss와 frequency domain loss로 나뉘는데 time domain은 원본 오디오와 복원된 오디오 사이의 L1 loss를 통해 구해진다. frequencey domain은 멜 스펙트로그램 상에서 L1과 L2의 조합으로 loss가 구성된다.
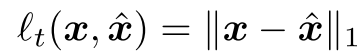
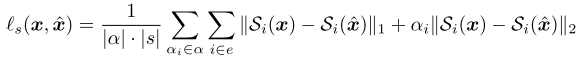
Discriminative Loss
perceptual loss term을 의미하고, MS-STFT Discriminator의 출력을 통해 계산한다.
Generator와 Discriminator는 아래의 adversarial loss를 통해 서로 적대적으로 학습된다.
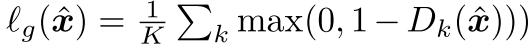
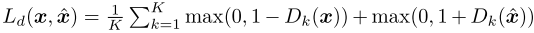
그리고 SoundStream이나 기존 보코더 연구에서 많이 쓰이는 feature matching loss도 사용한다.
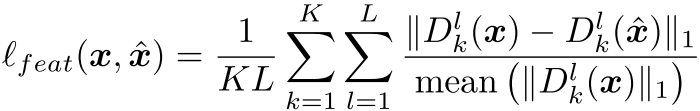
VQ Commitment Loss
Encoder의 출력과 양자화된 출력 사이의 차이를 L2로 계산하는 loss이다. 이때, 양자화된 출력에는 gradient stop을 적용해서 인코더만 업데이트 될 수 있게 한다.
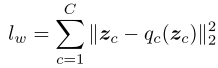
Total Loss
결국 Generator는 아래처럼 여러 loss 들의 가중치 합을 통해 학습된다.
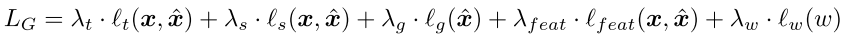
Balancer
Discriminator가 학습 시 gradient 스케일이 크게 변하기 때문에 야기되는 학습의 불안정성을 해소하기 위해 Balancer가 고안되었다. 원래는 loss별 가중치 값은 loss의 스케일을 고려해서 정해지기 마련인데 이는 굉장히 인위적인 값이기도 하고, loss 스케일이 크게 변하는 텀에 대해서는 무의미하다. 그렇기 때문에 Balancer는 hyper-parameter로 주어진 가중치와 gradient를 normalize하는 방식을 사용한다.
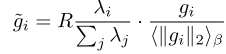
위와 같이 가중치는 가중치의 합으로 나눠주고, 원래 gradient는 gradient의 EMA로 나눠주면서 gradient를 계산하여 loss 가중치가 의미하는 바를 ‘어떤 loss를 얼마만큼 중요하게 생각할지’로 해석가능하게 바꿔 놓으면서 학습을 안정화시킨다. commitment loss는 모델의 출력에 의해 계산되는 값이 아니기 때문에 balancer를 적용하지 않는다.
실험 결과
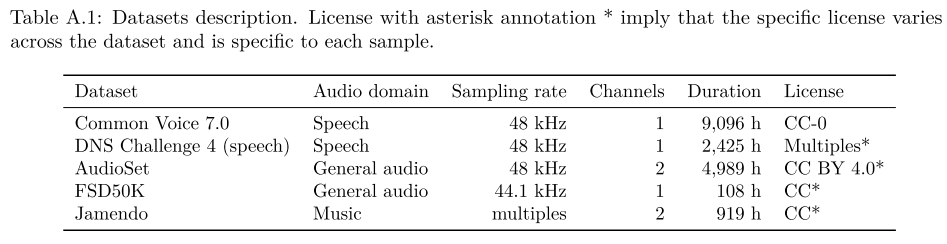
음성 데이터셋으로는 DNS Challenge 4, Common Voice 데이터셋을 사용하였다. 즉, multi-lingual 데이터를 포함하고 있다. 그리고 일반적인 오디오로는 AudioSet, FSD50K를 사용하였으며 음악 데이터로는 Jamendo를 포함시켰다.
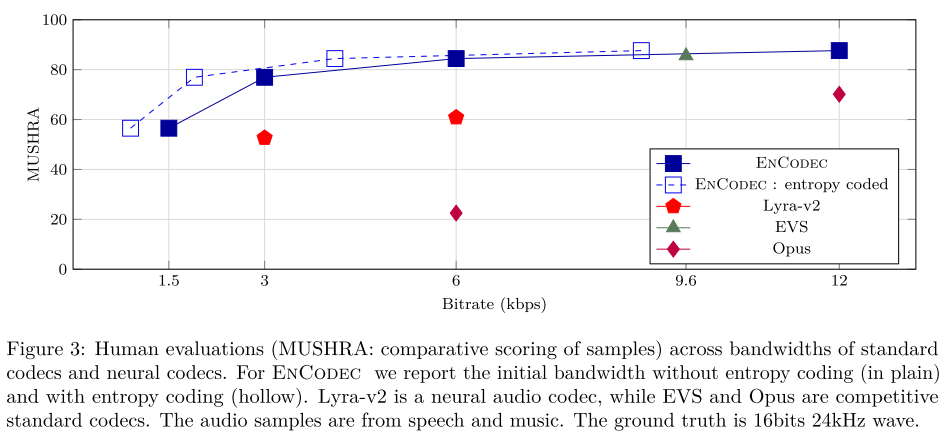
그림 3에서 나타내는 바와 같이, 베이스라인들과 MUSHRA 스코어를 비교해볼 때 EnCodec streamable 모델이 모든 비트레이트에서 베이스라인 모델들을 능가한다. 또한 EnCodec에 랭귀지 모델을 추가하여 엔트로피 코딩을 하면 비트레이트를 약 25-40% 줄일 수 있는 장점이 있다.
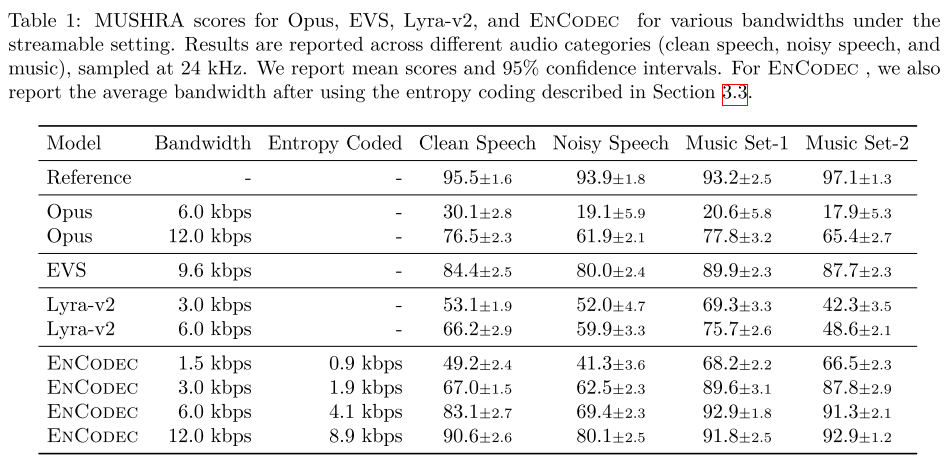
표 1은 그림 3의 결과를 오디오 도메인별로 나누어 보여주고 있다.
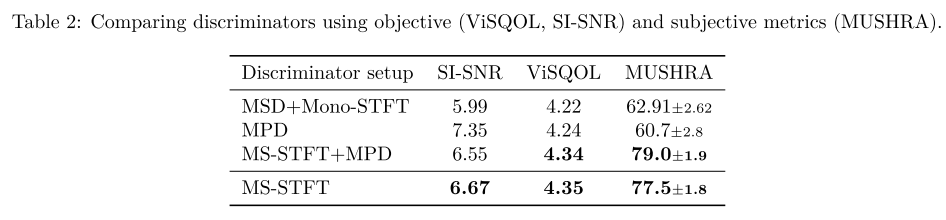
Discriminator에 대한 어블레이션 실험을 해봤을 때 논문에서 제안하는 MS-STFT를 단독으로 사용하는 경우가 SoundStream의 세팅인 MSD+Mono-STFT이나, MPD를 추가한 세팅들보다 우수한 성능을 보였다.
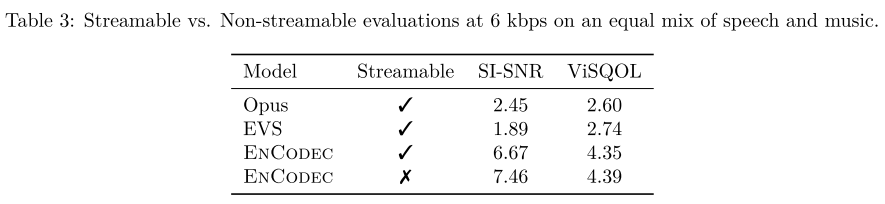
Streamable과 Non-streamable의 성능을 비교해보면 두 세팅 모두 베이스라인 모델의 성능을 뛰어넘으면서 Non-streamable의 성능이 가장 좋다. 그러나, 스트리밍이 가능한 점을 고려하면 이 정도의 degradation은 용납할 수 있는 수준이라고 한다.

음성 데이터 압축에서는 모노 오디오 실험만으로 충분하지만, 음악 데이터 압축을 위해서는 스테레오 오디오 세팅 실험이 중요하다. 표 4에서는 스테레오 오디오의 경우에도 EnCodec이 높은 MUSHRA 스코어를 보여주며 EnCodec 6 kbps가 MP3 64 kbps와 유사한 성능을 보여준다.
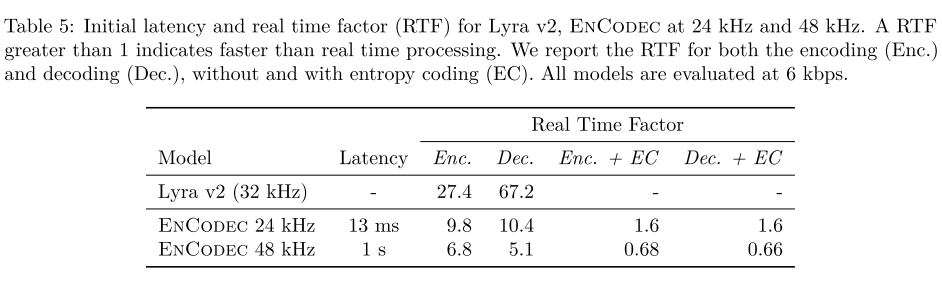
RTF는 오디오 길이와 실제 작업 시간의 비율을 나타내며, 1보다 크면 실시간보다 빠르게 처리되는 것을 의미한다. EnCodec이 Lyra v2에 비해 작업 속도가 느리지만, 여전히 실시간보단 10배 정도 빠른 속도를 보이기 때문에 실생활에서 좋은 후보로 고려될 수 있다.
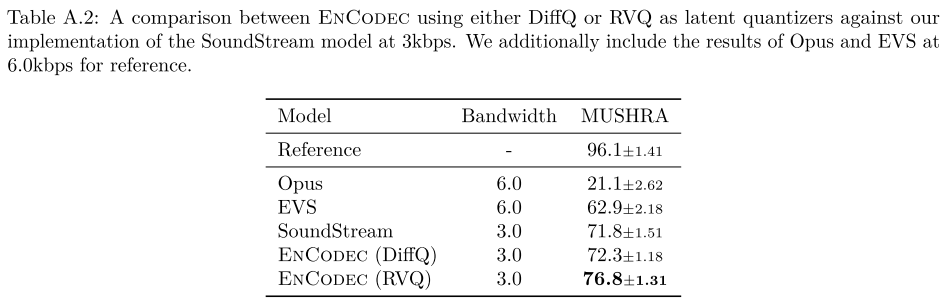
Quantizer로 RVQ 대신에 DiffQ를 사용한 결과이다. 보다시피 성능이 저하된다.
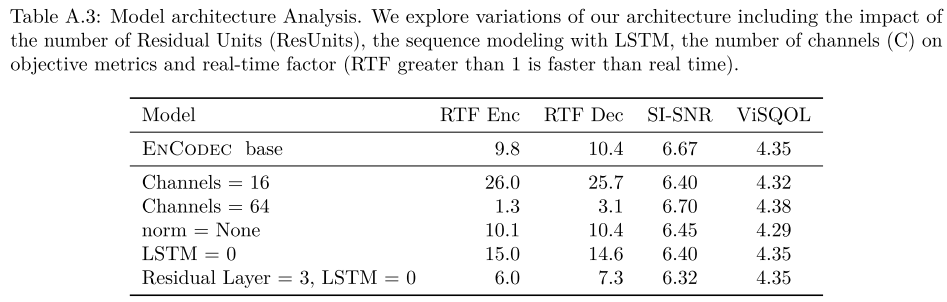
모델 아키텍처에 대한 어블레이션도 다양하게 수행했는데, LSTM을 없애거나 LSTM 대신 convolution layer(residual = 3)를 사용하여도 기존의 성능을 뛰어넘지 못한다는 점이다. 즉, LSTM을 사용하는 것이 가장 효과적이다.
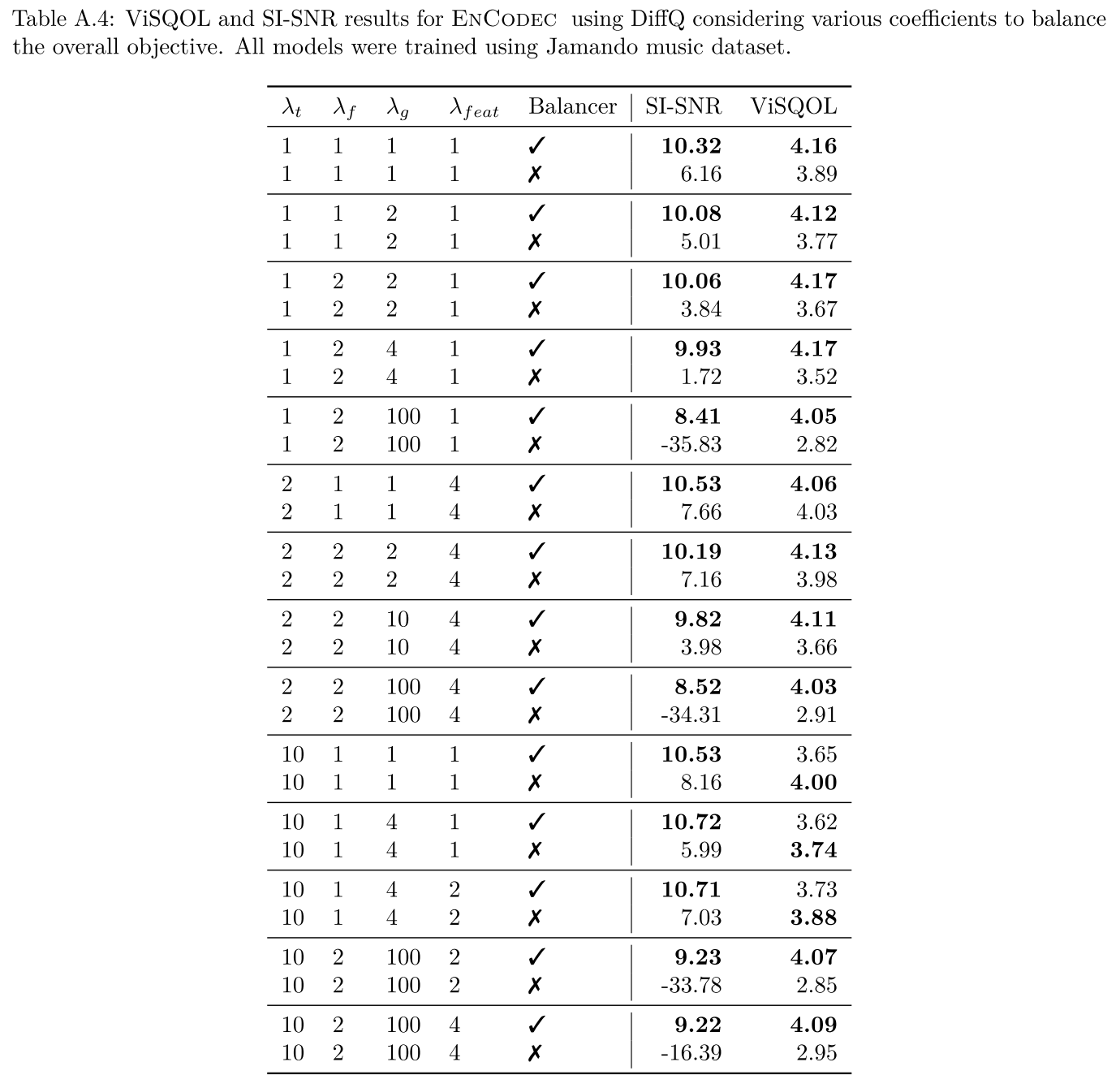
마지막으로 논문에서 비중 있게 다루는 Balancer의 역할을 보여주는 실험이다. loss 가중치들을 다양하게 바꾸면서 실험해보았을 때, Balancer가 적용된 경우에는 성능의 편차가 그리 크지 않게 안정적으로 학습되는 반면에 Balancer가 적용되지 않으면 학습에 실패하게 되는 모습을 볼 수가 있다. (예를 들어, [1,2,100,1]이나 [10,2,100,2] 같은 세팅)
의견
- Discriminator 훈련 과정을 간편하게 바꾸면서도 성능을 올린 점이 인상적이다.
- Balancer의 효과가 모델의 성능에 가장 큰 기여를 했다는 생각이 들고 GAN 기반 모델에 모두 적용해 볼 수 있겠다.

Leave a comment