
언제부턴가 음악을 안틀어주는 카페나 식당을 찾아볼 수 없듯이 우리가 대화를 많이 하게 되는 공간에는 항상 배경음악이 깔려있다. 드라마나 영화에서 수집되는 음성 데이터들도 배경음악이 섞여 있는 경우가 많은데 이런 데이터는 ASR의 성능을 안좋게 만든다. 그렇다면 이 문제를 어떻게 해결할 수 있을까? 본 논문의 저자들은 다중화자들의 음성을 분리시키는 성능에서 SOTA를 찍은 모델을 차용해서 해결했다고 하는데 지금부터 구체적으로 살펴보자.
모델 구조
Conv-TasNet과 attention-based ASR model
source separation에 관심이 많은 사람들이라면 Conv-TasNet을 익히 들어보았을 것이다. Conv-TasNet은 현재 multi-speaker source separation에서 SOTA의 성능을 기록하고 있는 모델이며 본 연구에서는 음성과 음악이 섞여 있는 데이터에서 음성 신호만을 추출해내는 역할을 하게 된다.
그리고 추출된 음성 신호에서 음성 인식을 할 때는 attention-based ASR 모델을 사용한다. Conv-TasNet을 front-end로, attention-based ASR을 back-end로 사용하는 이 모델은 raw audio를 다루는 end-to-end 시스템이며 각각의 모델을 pre-trained된 상태로 사용하지 않고 fine tuning을 거쳐 ASR 성능을 더욱 향상시켰다.
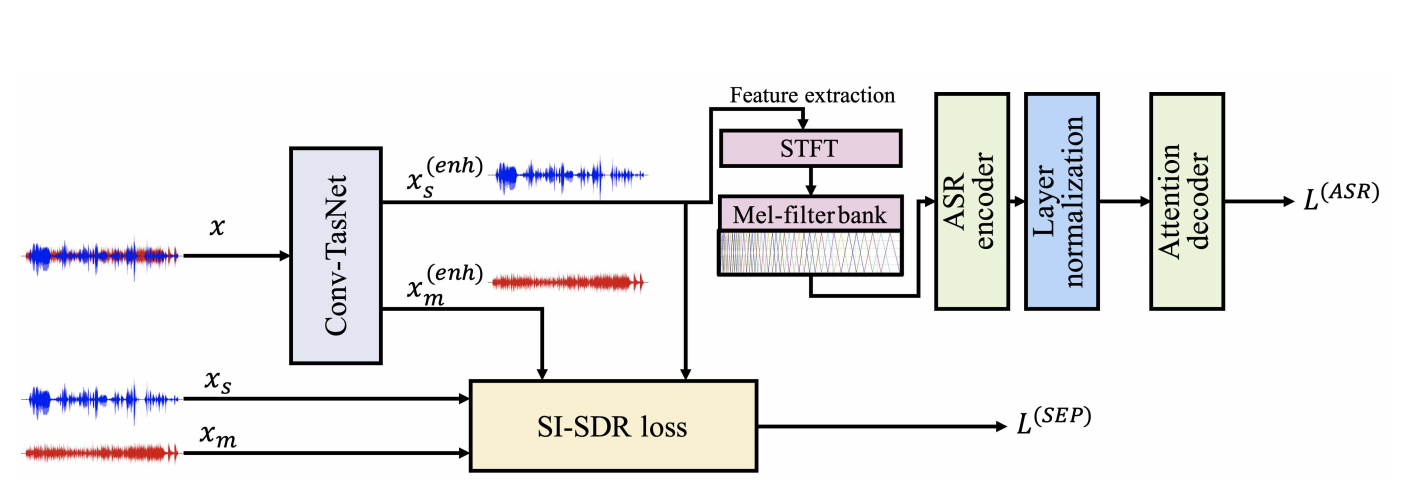
위 그림은 앞서 설명한 모델 구조를 나타내며 joint training을 시키기 위하여 구성한 loss function은 아래와 같다.
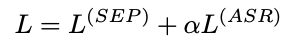
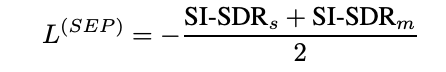 여기서 separation loss는 Conv-TasNet의 loss로 scale-invariant-source-to-distortion ratio(SI-SDR) loss로 구성되어 있으며, ASR loss는 label smoothing을 적용한 cross-entropy loss를 사용한다.
여기서 separation loss는 Conv-TasNet의 loss로 scale-invariant-source-to-distortion ratio(SI-SDR) loss로 구성되어 있으며, ASR loss는 label smoothing을 적용한 cross-entropy loss를 사용한다.
일반적으로 multi-speaker source separation에서는 permutation invariant training(PIT)[참고 논문]이 요구되지만, 이 모델 구조에서 ConvTasNet의 출력은 음성과 음악이기 때문에 출력의 순서를 직접 변경해 줄 수 있으므로 PIT가 필요하지 않다.(참고로 머신러닝 모델에서 permutation invariant는 입력 벡터 요소의 순서와 상관없이 같은 출력을 생성하는 특성을 말한다. MLP는 대표적인 permutation invariant 모델이고, CNN과 RNN은 아니다.)
데이터셋
Speech data로는 일본의 학회 발표 데이터셋인 Corpus of Spontaneous Japanese Academic Presentation Speech (CSJ-APS)를 사용했고 여기에 더한 배경음악이 무엇이냐에 따라 CSJ-anime, CSJ-genre로 구분해서 데이터셋을 사용했는데 anime는 애니메이션의 배경음악을 뜻하고 genre는 classical, jazz, popular music을 포함한다.
실험 결과
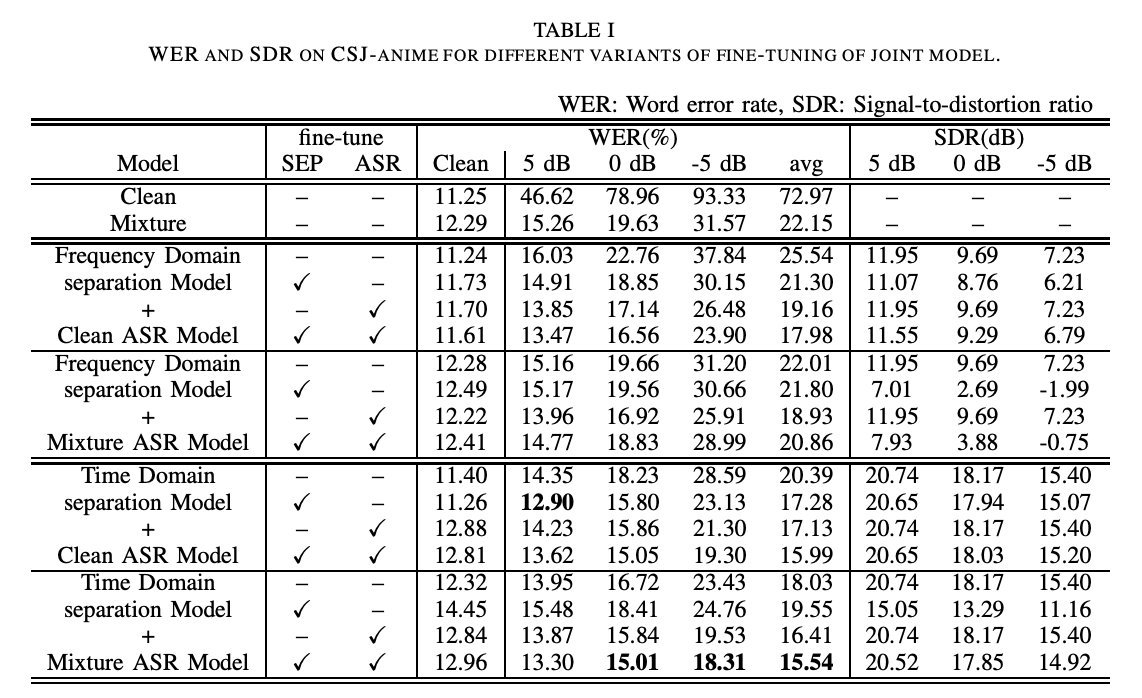
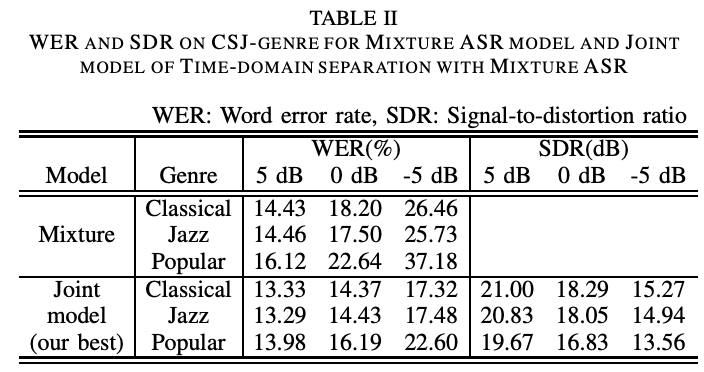
실험 결과로 제시된 두 표를 보면 time domain separation model과 speech-music mixture data로 학습한 mixture ASR을 결합하여 두 모델을 모두 fine tuing 했을 때 WER과 SDR 성능이 가장 높은 것을 확인할 수 있다. Table 2 에서 popular music에 대한 WER 성능을 보면 classical이나 jazz에 비해 안좋은 것을 알 수 있는데 이는 popular music이 가사를 포함하고 있어서 딥러닝 모델이 사람의 음성과 구분하기가 어려워지기 때문이다. 그럼에도 불구하고 joint model을 사용했을 때가 아닐 때보다 성능이 나아진 것을 보아 vocal music과 섞인 데이터에서의 음성 인식에도 본 모델이 효과적임을 알 수 있다.
TO STUDY
- WER, SDR
- Conv-TasNet




Leave a comment