
FastPitch
Łańcucki, Adrian. “Fastpitch: Parallel text-to-speech with pitch prediction.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
들어가며
FastSpeech에 기반하여 parallel한 TTS를 유지하는 가운데 추론 과정에서 pitch contour를 예측할 수 있는 FastPitch 모델을 제안한다. 이 모델은 예측된 pitch를 활용해서 발언의 의미에 더 잘 맞고 청자에게 더 끌리는 음성을 합성할 수 있다고 한다.
핵심 요약
- FastSpeech에 pitch predictor를 추가하여 실제 화자의 운율을 흉내내는 음성을 합성할 수 있게 했다.
- 추론 시 fundamental frequency(F0)를 조절하여 합성된 음성을 변조시킬 수 있는데 변조되었더라도 화자의 특성은 유지하고 있다.
- 다화자 모델로 쉽게 확장될 수 있고 이 경우에도 베이스라인들보다 높은 성능을 보인다.
모델 구조
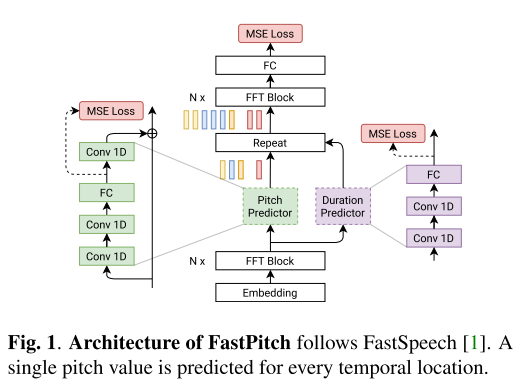
FastPitch에서 ground-truth(GT) duration은 pre-trained Tacotron 2에서 가져온다. Tacotron 2에서 어텐션 매트릭스는 1개이기 때문에 이 매트릭스에서 argmax를 이용해 input symbol별 duration을 뽑아내면 된다. 여기서 Tacotron 2가 학습한 어텐션 정렬에 성능이 크게 좌우될 수 있겠다고 생각할 수 있지만 저자들이 실험한 결과로는 같은 symbol에 대해서 다른 duration이 예측된 경우여도 최종 성능은 비슷했으므로 FastPitch는 어텐션 정렬에 대해서 강건하다고 주장한다.
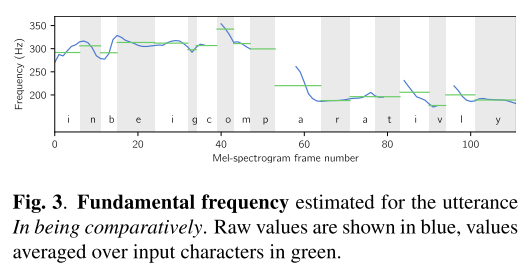
input symbol에 해당하는 pitch는 accurate autocorrelation method를 이용해서 acoustic periodicity를 탐지하는 방식으로 추출한다. 이때 window size는 멜 스펙트로그램의 resolution과 일치시켜서 매 프레임당 하나의 F0가 추출되도록 하였다. 그 후에는 아래 그림3처럼 duration을 이용하여 같은 symbol에 해당하는 프레임의 F0를 평균으로 치환해주는 작업을 거친다.
거의 동시에 고안된 FastSpeech 2는 멜 스펙트로그램의 프레임마다 하나의 F0를 갖도록 예측하는 반면, FastPitch는 symbol마다 하나의 F0를 갖도록 하는 것이 다르다. 이에 대해서 저자들은 lower resolution이 모델의 contour 예측을 더 쉽게 만들어주고, 추후 사용자 입장에서는 pitch를 interactive하게 수정할 수 있도록 해주는 장점이 있다고 주장한다.
duration과 pitch 모두 학습 시에는 GT를 사용하고 추론 시에는 예측된 값을 사용한다.
실험 결과
음성 합성 품질
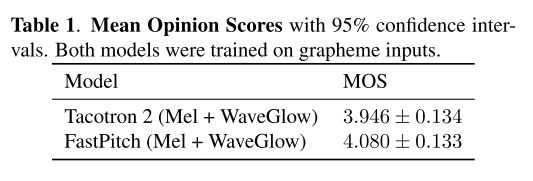
Tacotron 2와 FastPitch 모두 grapheme을 입력으로 하여 훈련시켰을 때 FastPitch가 더 높은 MOS를 기록하였다.
하이퍼파라미터 조절
![]()
생성 모델은 생성 결과의 품질이 주관적으로 평가될 수 밖에 없다는 한계 때문에 하이퍼파라미터 튜닝이 불가능하다. 대신에 몇몇 하이퍼파라미터 세팅을 바꾼 모델들 간의 상호 비교를 통해서 우열을 나눠볼 수는 있는데 대표적으로 Glicko-2 ranking을 사용한다고 한다. 그림 4에서는 FastPitch에서 어텐션 헤드의 수(A), 트랜스포머 레이어의 수(L), input token 당 예측되는 pitch의 수(Pitch)를 바꿔가면서 실험해본 결과를 나타내고 이로부터 최적의 세팅은 어텐션 헤드는 1개를 사용하고, pitch는 1개만 예측하는 경우라는 것을 알 수 있다.
다화자 음성 합성 품질
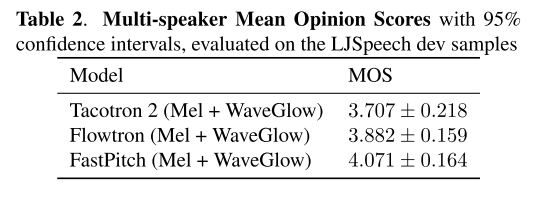
FastPitch에 speaker embedding을 추가하여 다화자 모델로 확장시킨 후 실험하였다. 다화자의 음성을 합성하더라도 베이스라인 모델들보다 높은 성능을 보인다.
피치 조절과 추론 성능
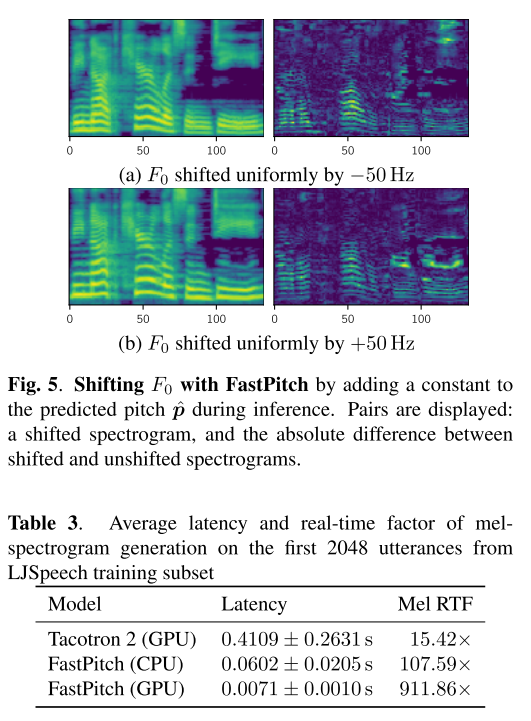
추론 시에 예측된 pitch에다가 상수 값을 더해주어 F0를 이동시킬 수 있기 때문에 같은 텍스트에 대해서 다양한 표현이 가능하다. 예를 들어, 운율을 없애거나 반대로 만들어줄 수 있고 다화자 모델에서는 두 사람의 pitch를 interpolation하여 새로운 사람의 음성인 것처럼 만들어낼 수도 있다.
FastSpeech에 기반한 모델답게 추론 시 멜 스펙트로그램을 만드는 속도는 CPU, GPU 기준 모두 베이스라인인 Tacotron 2를 크게 능가한다.
의견
- 추론 속도를 비교할 때 FastSpeech의 결과를 함께 비교하지 않은 것이 아쉬운데 아무래도 pitch prediction과정이 추가되었기 때문에 더 느려지지 않았을까 싶다.
- 데모 사이트에서 각 symbol에 해당하는 pitch를 interactive하게 조절하는 예시를 영상으로 보여주는 것이 인상적이다.
- 요즘 TTS 연구의 트렌드가 phoneme인 입력을 받아서 음성을 합성하는 것인데 grapheme을 입력으로 넣은 경우와 합성 품질의 차이가 없다고 언급되어 있어서 놀라웠다.




Leave a comment