
FastPitchFormant
Bak, Taejun, et al. “FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis.” arXiv preprint arXiv:2106.15123 (2021).
들어가며
그동안 TTS 모델에서 합성 음성의 운율을 조절하기 위해서 컨디셔닝으로 주어지는 acoustic feature(duration, pitch, energy 등)를 수정하는 방식을 써왔다. 이렇게 하면 실제로 운율이 수정은 되었지만 오디오의 품질이 떨어지거나 화자의 특징이 사라지는 문제점들이 발견되었고, 이에 대한 해결책이 필요해졌다. 특히 FastPitch는 pitch를 조절할 수 있는 모델인데 평균 pitch 근처에서는 pitch를 조절하여도 화자의 특성이 유지가 되지만 그보다 조금만 벗어나면 특성이 많이 사라지는 현상이 관찰되었고, 본 논문에서는 이를 FastPitch의 구조적인 결함에서 나오는 문제로 해석하여 변형된 모델 구조를 제시한다.
핵심 요약
- FastPitch 모델에 source-filter 이론을 접목하여 formant feature와 excitation feature를 따로 추출하고 두 정보를 합쳐서 최종 음성을 만들어 낸다.
- pitch를 크게 바꿔도 원래 화자의 특성을 많이 잃지 않는 음성을 합성할 수 있다.
- Parallel Tacotron과 같이 멜 스펙트로그램 디코더에 iterative loss를 적용했다.
모델 구조
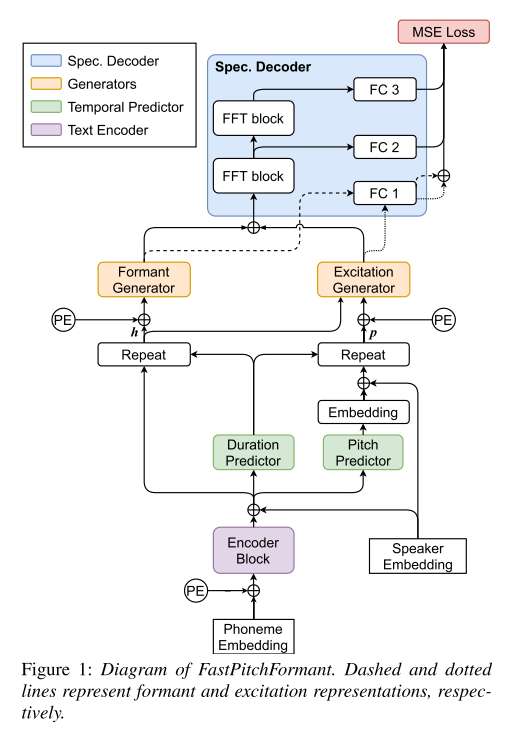
FastPitch에 2개의 Generator를 추가하고 디코더를 iterative한 구조로 바꾸었다. source-filter 이론에 따라 Formant Generator는 성도(vocal tract)에서 만들어지는 포먼트 정보를 생성하는 역할을 하고 Excitation Generator는 성대(vocal cord)에서 만들어지는 초기 진동의 정보를 생성하는 역할을 한다. 그리고 실제 음성이 만들어질 때는 둘의 곱으로 증폭과 감쇠가 결정되면서 최종 파형이 만들어지지만 모델에서 연산에 사용하는 멜 스펙트로그램은 log 스케일을 갖고 있기 때문에 두 피쳐의 합을 디코더에 전해주는 것을 확인할 수 있다.
실험 결과
Objective Evaluation
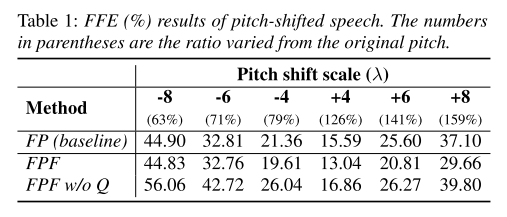
FastPitch(FP)와 FastPitchFormant(FPF) 그리고 FPF에서 Excitation Generator의 query(Q)벡터를 계산할 때 pitch representation만 쓰는 경우(FPF w/o Q)에 대해서 pitch shift 실험을 진행했다. pitch shift는 semitone 단위로 이루어졌으며 metric은 f0 frame error(FFE)이다. FPF가 모든 pitch shift scale에 대해서 FFE가 가장 낮으므로 pitch control accuracy가 높다고 할 수 있다. 또, FPF w/o Q의 결과를 통해 그림 1에 나타나 있는 것처럼 Excitation Generator의 입력으로 linguistic feature까지 함께 넣어주어야 성능이 향상됨을 알 수 있다.
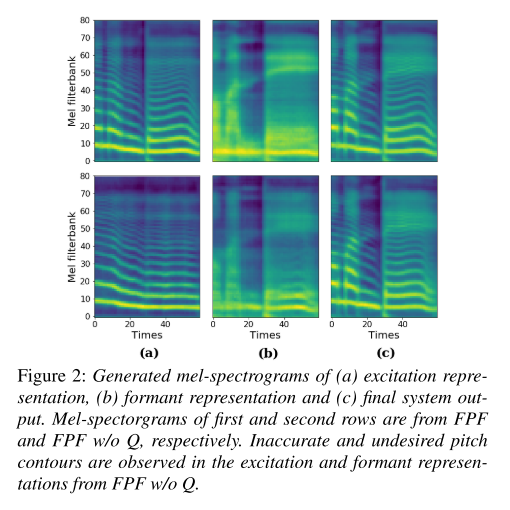
그리고 그림 2를 보면 첫번째 줄의 (a)와 (b)가 최종 파형의 excitation과 formant를 잘 분리해서 멜 스펙트로그램으로 표현하고 있는 반면에 두번째 줄의 멜 스펙트로그램에서는 이런 분리가 잘 나타나지 않는 것을 알 수 있다. 따라서 FPF의 기본 세팅으로 실험했을 때 source-filter 이론에 따라 모델의 generator들이 의도한대로 잘 학습되고 더불어 정확한 피치의 음성을 합성하게 되는 결과를 낳는다는 결론이 나온다.
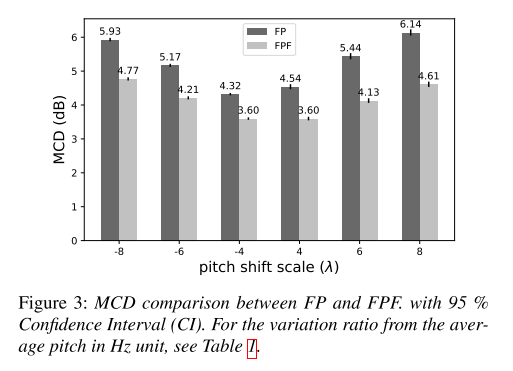
두 generator가 excitation과 formant를 잘 분리하도록 학습됐다면 피치를 조절하게 되어도 음성의 speech envelope은 일정해야 하기 때문에 이런 강건성이 유지되는지 실험해 보았다. FPF와 FP 모두 pitch shift의 크기가 커질수록 metric인 mel-cepstral distortion(MCD)의 값이 커지지만, FPF의 값이 더 작으므로 강건하다고 할 수 있다.
Subjective Evaluation
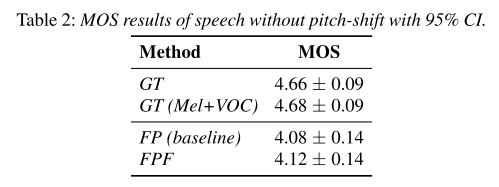
청취자들을 모집해 MOS를 했을 때 결과도 FPF가 GT에 더 근접하며 좋은 품질을 보여준다.
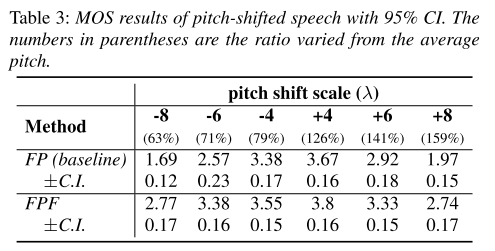
pitch shift에 따라서 MOS 결과를 나타내봐도 FPF가 베이스라인인 FP보다 좋은 품질의 음성을 합성한다는 것을 알 수 있고, 이런 격차는 shift의 크기가 커질수록 더 커지는 양상을 보인다.
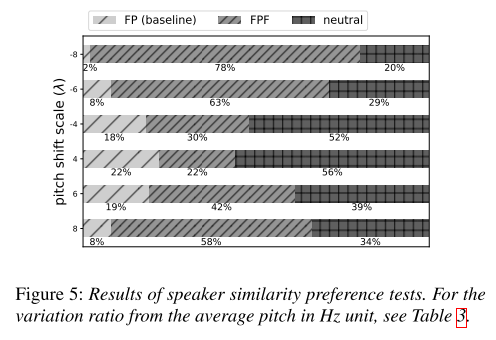
audio preference 실험을 통해서 pitch shift에 따라 어떤 모델의 음성이 화자와 비슷하게 느껴지는지도 평가했는데 shift가 작을 때는 둘 사이에 큰 차이가 없지만 shift가 커질수록 FPF의 음성을 선호하는 경향이 커진다. 즉, FPF는 pitch shift가 커져도 화자의 특성을 잘 유지하면서 음성을 합성하는 것이다.
의견
- text와 acoustic 정보를 다른 루트로 흐르게 하여 예측된 pitch에 수정을 가한 것이 최종 pitch에 거의 그대로 적용될 수 있도록 유지한 아이디어가 참신하다.
- 스피커 임베딩과 포지셔널 임베딩을 더해주는 위치를 바꿔가면서 현재의 모델 구조처럼 최적의 위치를 정하게 된 것일텐데 이 부분에 대한 설명이 궁금하다.




Leave a comment