
FastSpeech
Ren, Yi, et al. “Fastspeech: Fast, robust and controllable text to speech.” arXiv preprint arXiv:1905.09263 (2019).
들어가며
뉴럴 넷에 기반한 end-to-end TTS 모델들이 음성 합성 품질을 많이 향상시키고 있지만, 추론 속도가 느리고, 에러가 많고(단어 반복 or 누락), 출력에 대한 조절이 불가능하다는 단점을 갖고 있다. 이는 기존의 모델들이 autoregressive하게 멜 스펙트로그램을 생성하기 때문에 생기는 문제이며, 이를 해결하기 위해 Transformer를 기반 모델로 사용해서 멜 스펙트로그램을 parallel하게 생성할 수 있는 FastSpeech라는 모델을 제안한다.
핵심 요약
- 멜 스펙트로그램을 parallel하게 생성함으로써 FastSpeech는 음성 합성 속도를 크게 향상시켰다.
- duration predictor를 사용하여 phoneme과 멜 스펙트로그램 사이의 정렬을 보장하기 때문에 autoregressive 모델에서 잘못된 어텐션 정렬 때문에 발생하는 오류 전파 현상을 방지할 수 있다.
- length regulator에서 phoneme duration을 수정하여 발화 속도를 조절하거나 인접한 phoneme 사이에 쉬는 부분을 넣음으로써 운율을 조절하여 다양한 음성을 합성할 수 있게 하였다.
모델 구조
FastSpeech는 autoregressive한 구조를 버리고 feed forward network 구조를 채택한다.
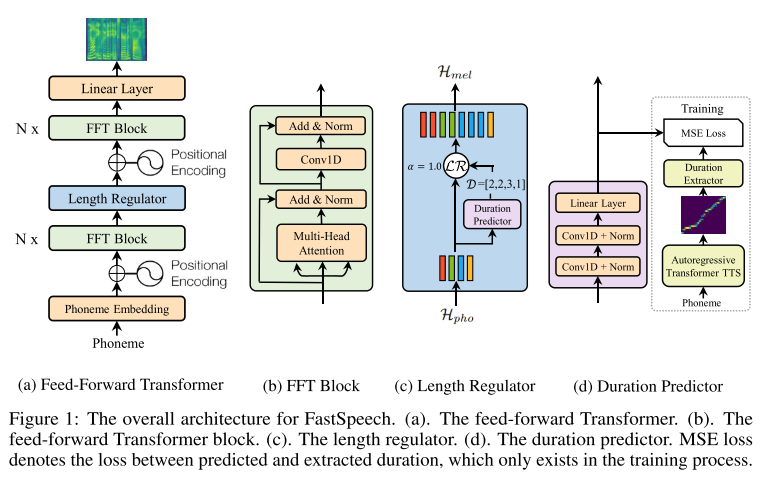
기본적인 구조는 self attention과 Conv1D로 이루어진 FFT(Feed-Forward Transformer)가 phoneme에서 멜 스펙트로그램으로 가는 변환을 수행하고 이 둘 사이의 길이 차이를 보정하기 위해서 length regulator가 끼어 들어간 형태이다. length regulator 내부의 duration predictor를 학습시키기 위해 autoregressive teacher TTS model(Transformer TTS model)로부터 phoneme duration을 추출하는 방법을 사용한다.
그리고 이 때 멀티헤드 어텐션으로부터 여러개의 디코더-인코더 어텐션 정렬이 나오고 이 중 monotonously align된 어텐션 헤드를 고르기 위해서 focus rate F라는 것을 정의해서 계산하는데 공식에 오류가 있어 보인다(찾아보니 NeurIPS의 리뷰어도 같은 의견을 제시함).
학습 과정
- autoregressive Transformer TTS model을 훈련시킨다.
- 학습된 teacher model로부터 어텐션 정렬과 생성된 멜 스펙트로그램(sequence-level knowledge distillation용)을 추출한다.
- 추출한 어텐션 정렬로부터 duration predictor를 훈련시키고, 소스 텍스트와 생성된 멜 스펙트로그램의 데이터 쌍을 통해 FastSpeech 모델을 훈련시킨다.
실험 결과
음성 품질 평가

보코더는 pre-training된 WaveGlow 를 사용했고, 역시 MOS로 품질을 평가한다. FastSpeech로 합성한 음성이 Baseline으로 쓰인 모델들과 비슷한 수준의 품질을 나타내는 것을 알 수 있다.
추론 속도 증가
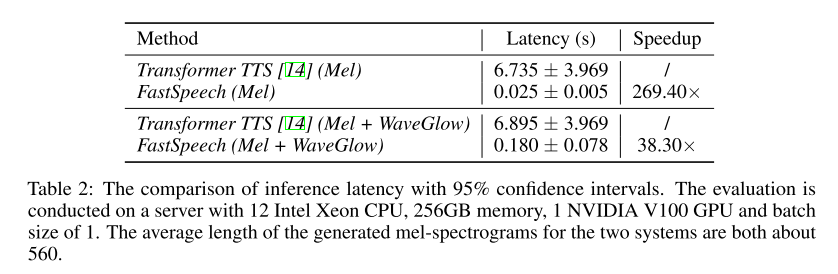
추론 스텝에서 멜 스펙트로그램을 만들기까지의 시간과 최종 오디오를 만들기까지의 시간 두 가지 모두를 측정해 봤을 때, 두 경우 모두 FastSpeech가 baseline인 Transformer TTS(파라미터 수가 FastSpeech와 비슷하도록 세팅)보다 짧게 걸리므로 훨씬 빠른 모델이라 판단된다.
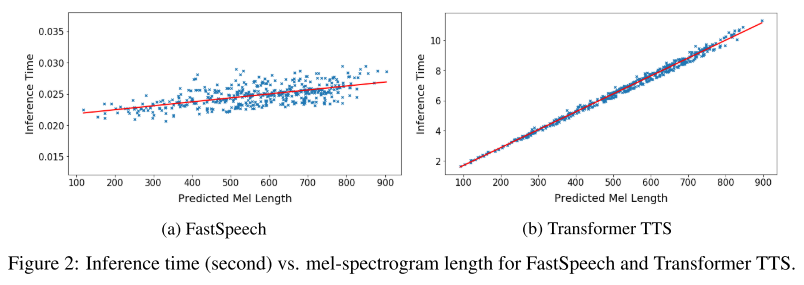
이는 멜 스펙트로그램 길이에 따른 추론 시간 그래프를 그려봤을 때 더 확연한 차이로 나타나는데 두 모델 모두 멜 스펙트로그램 길이가 길어질수록 추론 시간이 선형적으로 증가하는 모습을 보이나, 그 기울기는 FastSpeech가 훨씬 완만하다.
강건성

TTS 모델들이 발음하기 어려워 하는 50개의 문장들을 가지고 강건성 테스트를 한 결과 FastSpeech는 모두 오류 없이 발음하였다.
길이 조절
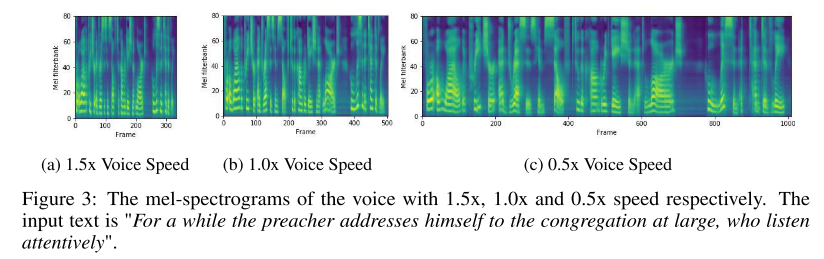
length regulator의 하이퍼파라미터를 조절하여 phoneme별 duration을 특정 배수만큼 늘리거나 줄여서 음성의 속도를 조절할 수 있다.
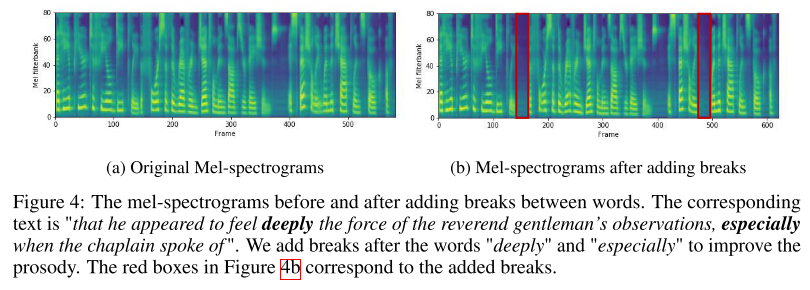
그리고 문장에서 공백 문자에 해당하는 부분의 duration만 조절하여 음성의 운율 또한 임의로 만들어줄 수 있다.
Ablation Study

FastSpeech 모델 구조에서 FFT 블록의 1D convolution을 뺀 경우(vanilla Transformer의 fully connected layer 사용)와 sequence-level knowledge distillation을 제거한 경우(모델 학습 시 생성된 멜 스펙트로그램 말고 GT 멜 스펙트로그램을 사용하는 방식)에 대하여 ablation study를 진행했다. 그 결과, 두 경우 모두 기존보다 성능이 저하됨을 확인할 수 있었다.
의견
- Transformer의 장점을 TTS에 가장 잘 접목시킨 연구가 아닌가 하는 생각이 들고 빠르기만 한게 아니라 정확성과 실용성까지 두루 갖췄다는 점에서 훌륭한 연구인 것 같다.
- 보코더 파트까지 함께 설계하여 fully end-to-end로 음성을 합성해 보는 시도가 있었다면 더 완벽한 연구가 되었을 것 같다.




Leave a comment