
FastSpeech2 & FastSpeech2s
Ren, Yi, et al. “Fastspeech 2: Fast and high-quality end-to-end text to speech.” arXiv preprint arXiv:2006.04558 (2020).
들어가며
FastSpeech가 경쟁력 있는 품질로 autoregressive 모델들보다 더 빠르게 음성을 합성할 수 있게 되었지만 teacher model을 사용하기 때문에 비롯되는 문제점들을 안고 있다. 우선 학습 과정이 복잡하고 오래 걸리며, teacher model에서 추출된 duration이 부정확할 수 있다. 또한 teacher model로부터 나온 타겟 멜 스펙트로그램도 실제 멜 스펙트로그램보다는 단순하게 표현될 수 밖에 없기 때문에 정보의 손실이 발생한다.
이런 문제점들은 음성의 품질을 저하시키는 원인으로 작용하기 때문에 FastSpeech 2에서는 teacher model을 제거하고 실제 타겟 멜 스펙트로그램을 이용해 학습하면서 conditional input으로 다양한 variation information을 추가해줌으로써 음성 합성 품질을 한층 더 향상시킨다.
더 나아가 parallel하게 End-to-End TTS가 가능한 FastSpeech 2s를 제시하고, 베이스라인 모델들보다 음성 합성 품질과 속도 모두 향상됨을 보인다.
핵심 요약
- teacher model을 없앰으로써 FastSpeech보다 3배 빠른 학습이 가능하다.
- variance adaptor를 통해 conditional input의 양을 늘려 줌으로써 음성 합성의 품질을 향상시킬 수 있다.
- FastSpeech2s는 높은 합성 품질을 유지하면서도 End-to-End로 text에서 speech를 바로 합성함으로써 추론 과정을 단순하게 만들었다.
모델 구조
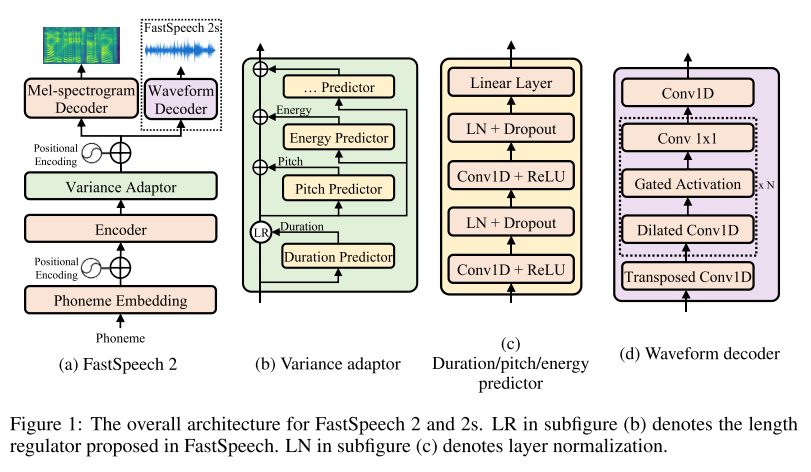
FastSpeech가 non-autoregressive한 방식으로 기존의 TTS 모델들보다 빠른 속도로 inference가 가능하다는 것을 보여줬지만 아래와 같은 문제점들을 갖고 있다.
- teacher-student distillation 파이프라인이 너무 복잡하고 학습 시간이 오래걸린다.
- teacher 모델로부터 생성된 타겟 멜은 ground truth에서 정보가 일부 손실된 데이터이다.
- teacher 모델로부터 추출된 duration 정보가 정확하지 않다.
결국 모두 teacher 모델을 사용하기 때문에 발생하는 문제이며, 이를 해결하기 위해 FastSpeech 2에서는 teacher 모델을 없애버리고 ground truth 멜과 GT duration을 입력으로 넣어준다. 그리고 하나의 문장에 대해서 다양한 발화 형태가 존재할 수 있기 때문에(one-to-many mapping problem) duration뿐만 아니라 pitch, energy와 같은 다양한 variance도 학습할 수 있도록 variance adaptor 모듈을 구성하였다.
원본 음성으로부터 각 variance 정보를 추출하기 위해 사용한 방법은 아래와 같다(각각의 방법들은 시간 날 때 자세히 들여다 보겠다).
- duration : Montreal forced alignment(MFA)
- pitch : continuous wavelet transform(CWT)
- energy : L2-norm of the amplitude of each STFT frame
별도의 보코더 모델과 결합 없이 text-to-waveform이 가능한 FastSpeech 2s도 제시하고 있는데 이는 Wavenet의 구조를 모방한 waveform 디코더를 추가적으로 붙인 형태이다. waveform 디코더는 Parallel WaveGAN에서 제시하는 것과 같이 adversarial training을 사용하여 학습시켰으며, waveform을 생성한다고 해서 멜 디코더를 없애버리는 것이 아니라 함께 사용해서 텍스트 피쳐를 추출하는 과정을 돕게 만들었다.
실험 결과
보코더는 Parallel WaveGAN을 사용하였다.
음성 합성 품질
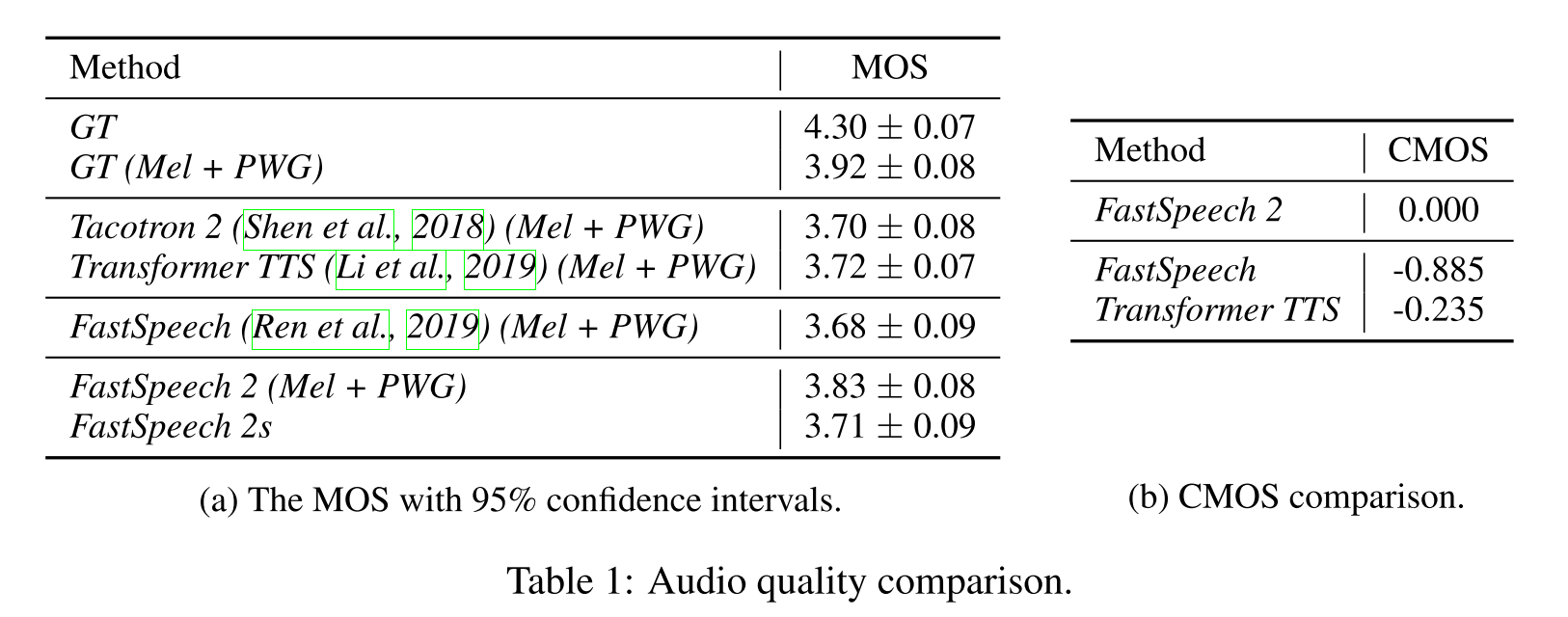
베이스라인 모델들보다 FastSpeech 2,2s의 MOS가 높은 것을 알 수 있고 CMOS를 비교해봐도 상대적으로 음질이 좋다는 것을 알 수 있다.
훈련 및 추론 시간
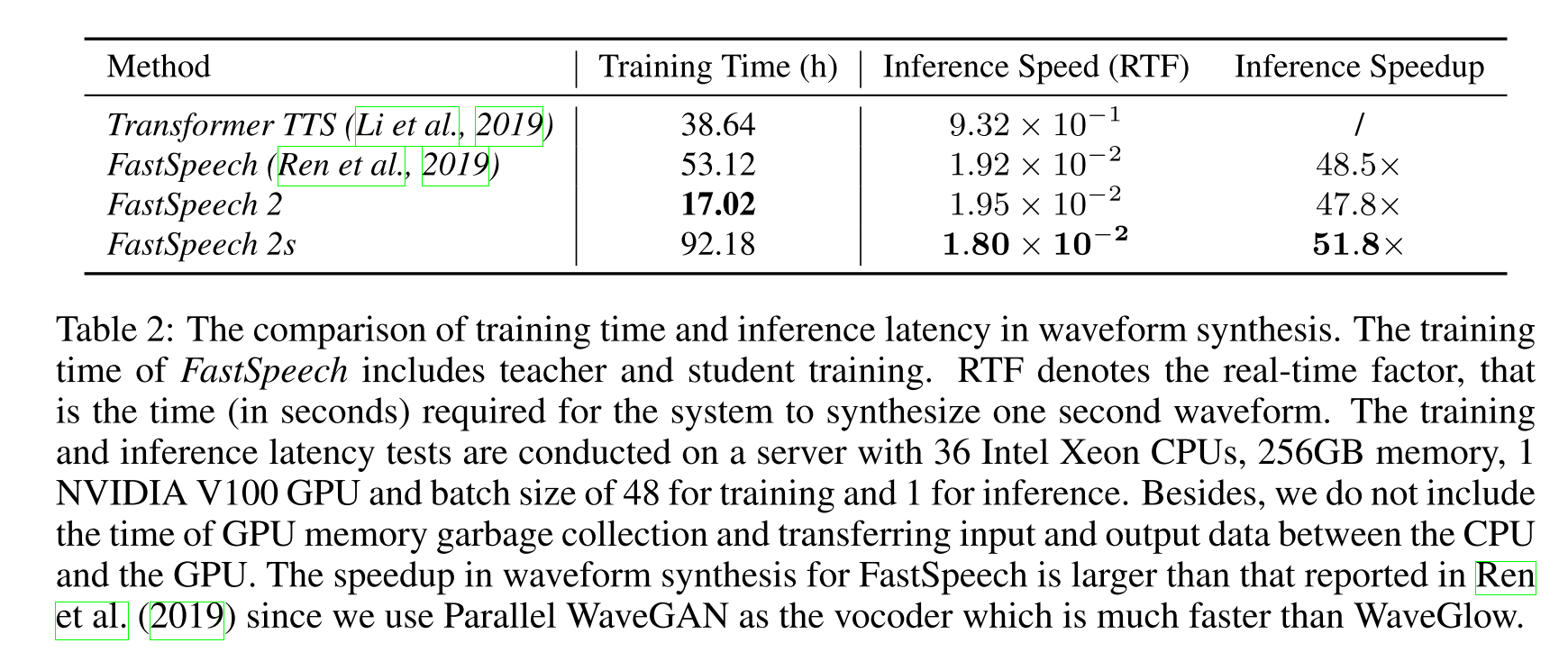
FastSpeech 2는 훈련 시간을 크게 단축시켰고, FastSpeech 2s는 추론 시간에서 이점이 있음을 확인할 수 있다.
Variance 정보의 효과 분석
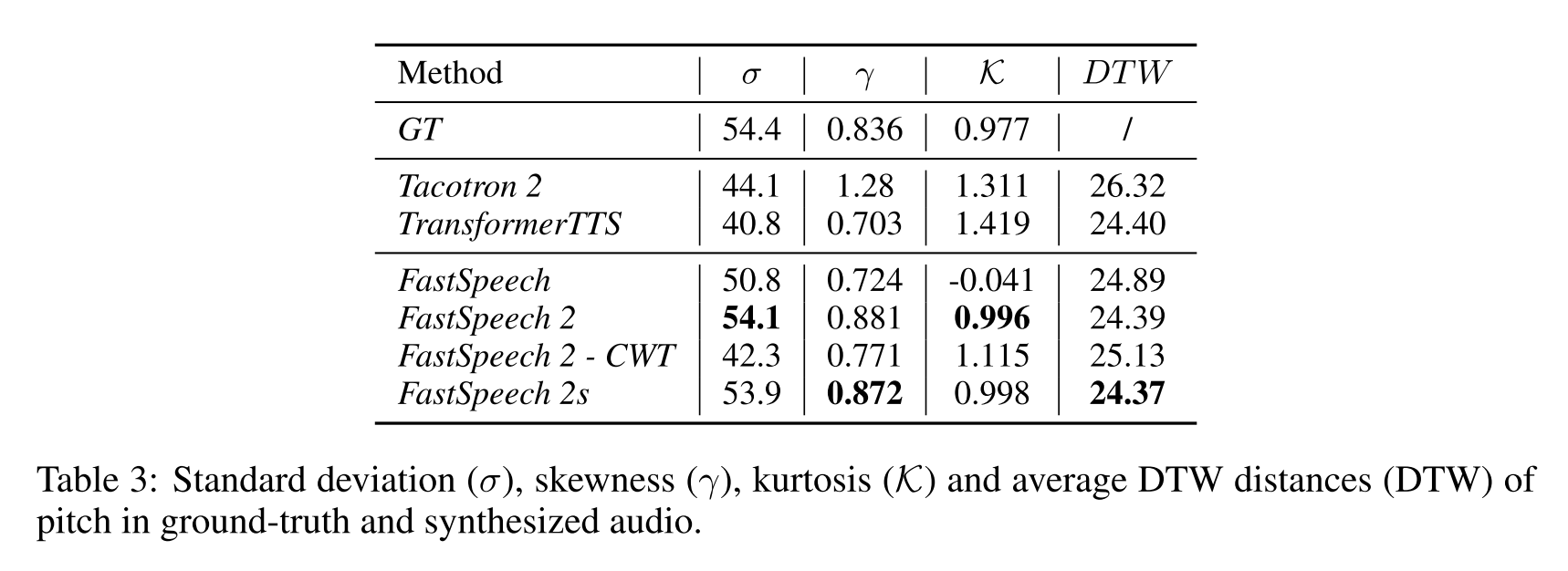
합성한 음성의 pitch와 GT pitch를 비교했을 때 FastSpeech 2,2s에서 가장 비슷한 pitch가 합성됨을 알 수 있다.

energy에 대한 분석을 해봤을 때도 FastSpeech보다 실제 energy에 가깝게 음성을 합성한다.

teacher model을 사용한 경우보다 MFA로 duration을 추출한 경우가 duration이 더 정확하고 품질 좋은 음성을 합성한다.
의견
- autoregressive 모델에 비해 추론 시간 뿐만 아니라 학습 시간까지 크게 단축된 모델이라 의의가 있고, 추가적인 variance들을 conditioning 해주어 음질을 높이려는 시도가 좋았다.
- ground truth 멜을 써서 학습시켜보는 것이 가장 직관적일텐데 왜 FastSpeech에서 teacher 모델을 먼저 사용해봤는지는 의문이다.

Leave a comment