
GST
Wang, Yuxuan, et al. “Style Tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis.” International Conference on Machine Learning. PMLR, 2018.
들어가며
합성된 음성이 사람과 유사하다는 느낌을 주기 위해서는 TTS 모델이 음성의 운율을 모델링할 수 있는 능력을 갖추는 것이 중요하다. 운율은 억양, 강세, 스타일 등의 복합적인 요소가 복합되어 만들어진다. 본 논문은 그 중에서도 스타일을 학습하여 텍스트에 상관없이 원하는 스타일로 음성을 합성할 수 있는 기술인 스타일 모델링에 대한 연구에 초점을 맞춘다. Tacotron과 jointly training 될 수 있는 global style token(GST)을 제시하여 다양한 스타일을 학습하고 표현력 있는 긴 음성을 합성할 수 있게 한다.
핵심 요약
- GST는 unsupervised 방식으로 학습되기 때문에 많은 양의 데이터에 사람이 스타일 라벨을 달아놓을 필요가 없어서 효율적이다.
- GST의 각 token이 사람이 해석 가능한 soft label을 학습하므로 음성을 원하는 스타일로 조절할 수도 있고 스타일을 전이해주는 것도 가능하다.
- GST는 잡음 제거와 다화자 음성 합성에도 쓰일 수 있다.
모델 구조
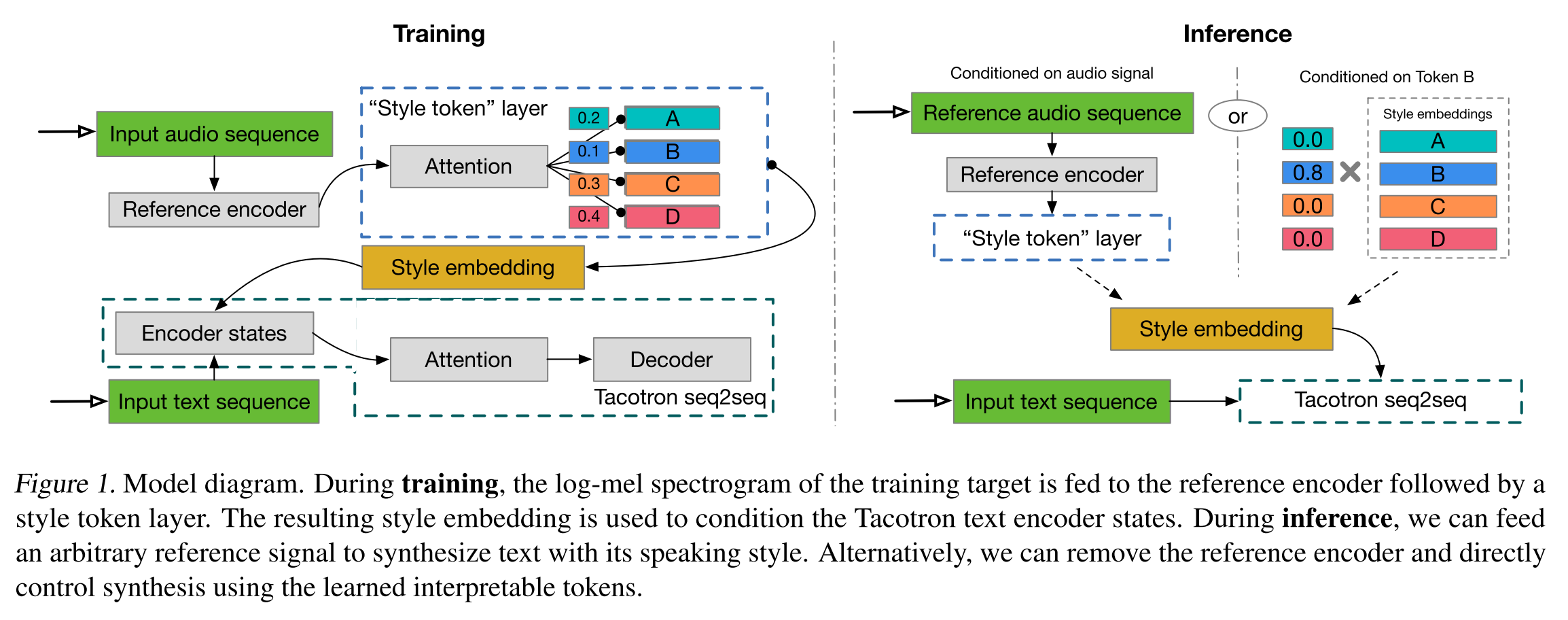
Tacotron에 reference encoder와 GST layer를 붙인 형태이다. reference encoder는 학습 시에 텍스트와 매칭되는 ground-truth 음성을 입력으로 받아서 고정된 길이의 임베딩 벡터를 만들고 GST layer에서는 이를 query 벡터로 활용하여 무작위로 초기화된 style token들과의 attention을 수행한다. 계산된 attention weight로 GST의 weighted sum을 구하여 최종 style embedding을 만들고 Tacotron의 encoder 스텝마다 hidden vector에 더해준다. 그리고 decoder에서 만들어낸 멜 스펙트로그램으로 reconstruction loss를 계산해서 학습이 진행되므로 GST layer를 학습시키기 위해서 어떤 style label도 필요가 없다.
추론 시에는 특정 토큰으로 직접 스타일을 컨디셔닝 해주는 방식이나 전이해주고 싶은 스타일을 가진 음성을 reference encder에 통과시켜서 뽑아낸 style embedding으로 음성을 합성하는 방식 중에 선택하여 진행할 수 있다.
실험 결과
Style Selection
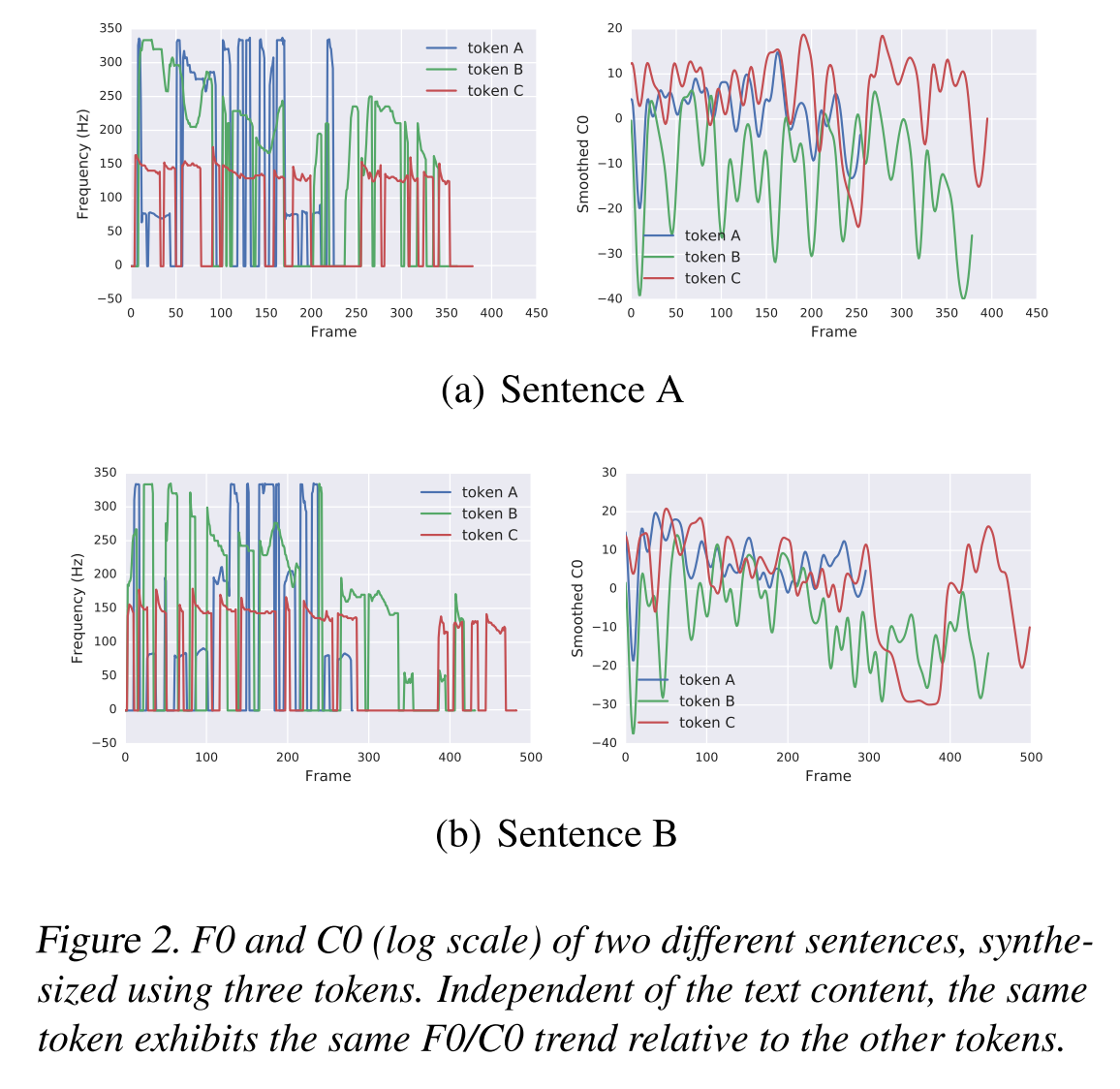
두 개의 문장에 대해서 세 개의 다른 style token을 활용하여 음성을 합성한 것이다. 같은 문장이지만 세 개의 token으로 합성한 문장의 pitch나 speaking rate가 다른 것을 확인할 수 있고, 같은 token으로 합성한 문장들은 비슷한 스타일을 가지는 것을 알 수 있다.
Style Scaling
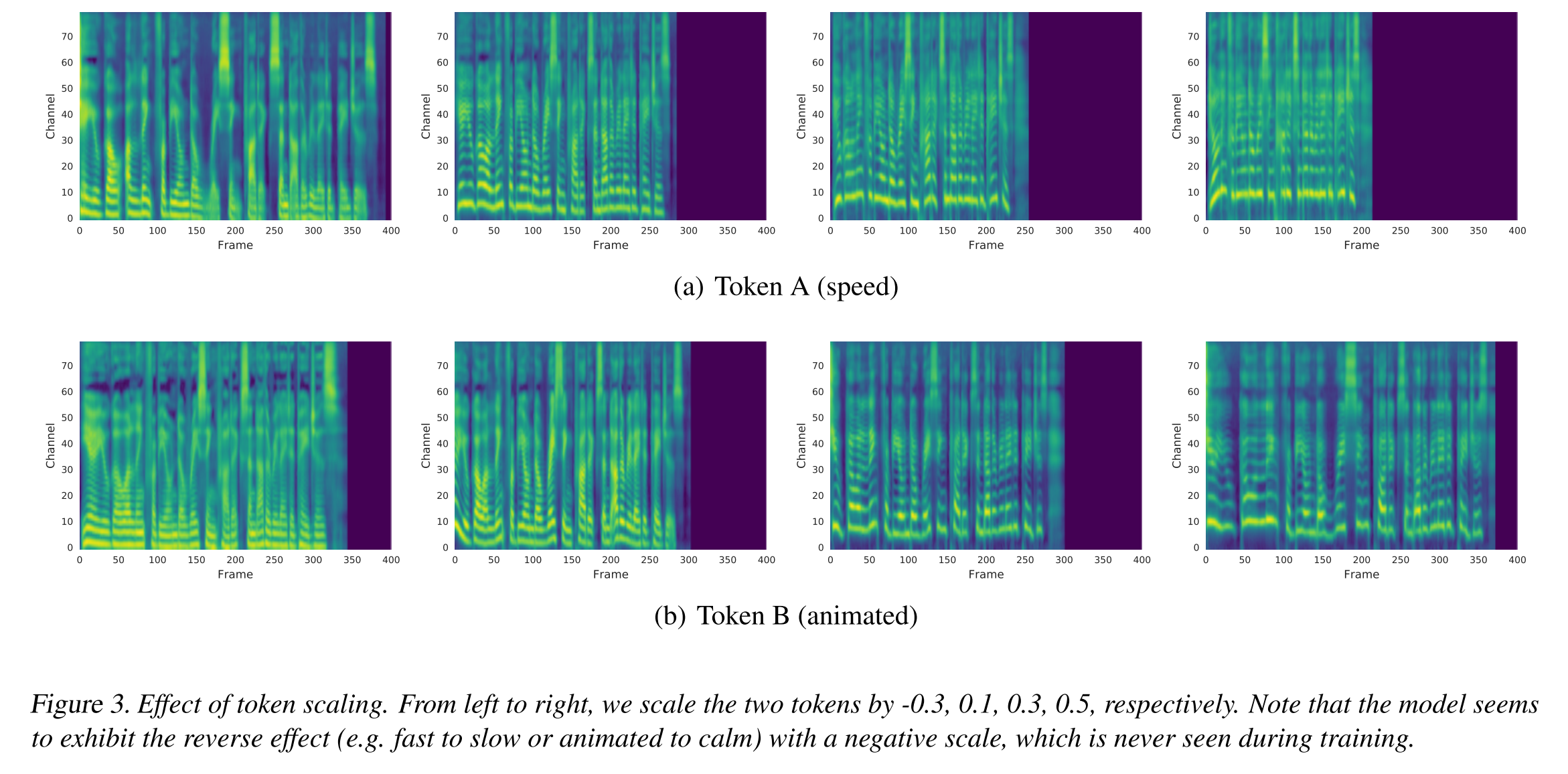
스타일을 조절하는 또 다른 방식으로 스케일링이 있다. style embedding에 스칼라 값을 곱하여 인코더에 주입해준 결과 그림 3과 같이 속도가 조절되거나 pitch의 변화가 조절되는 효과가 나타났다. 여기서 흥미로운 점은 음수가 곱해졌을 때 속도가 느려지거나 차분한 음성으로 변하는 효과가 나타났는데 모델이 학습할 때는 softmax 값을 scaling 값으로 갖기 때문에 음수는 보지 못했음에도 불구하고 스케일링을 음수 범위까지 학습하였다.
Style Sampling
추론 시에 token별 어텐션을 통해 최종 style embedding이 샘플링 되는데 이때 softmax의 temperature를 조절하여 샘플링되는 스타일의 다양성을 조절해볼 수 있다.
Text-side Style Control/Morphing
기본적으로 같은 style embedding이 모든 스텝의 input에 적용되지만, 이를 변형하여 각 스텝간 스타일 차이를 줄 수도 있다. 예를 들어, input text의 초반부는 빠르게 읽다가 중반부는 낮은 pitch로 읽고 후반부는 다시 빠르게 읽는 음성을 만들 수 있다.
Style Transfer
style transfer에는 두 가지 방식이 존재한다. 레퍼런스 음성과 매치되는 텍스트를 입력으로 사용하는 parallel 방식과 레퍼런스 음성과는 다른 임의의 텍스트를 입력으로 사용하는 non-parallel 방식이 있다.
- parallel style transfer
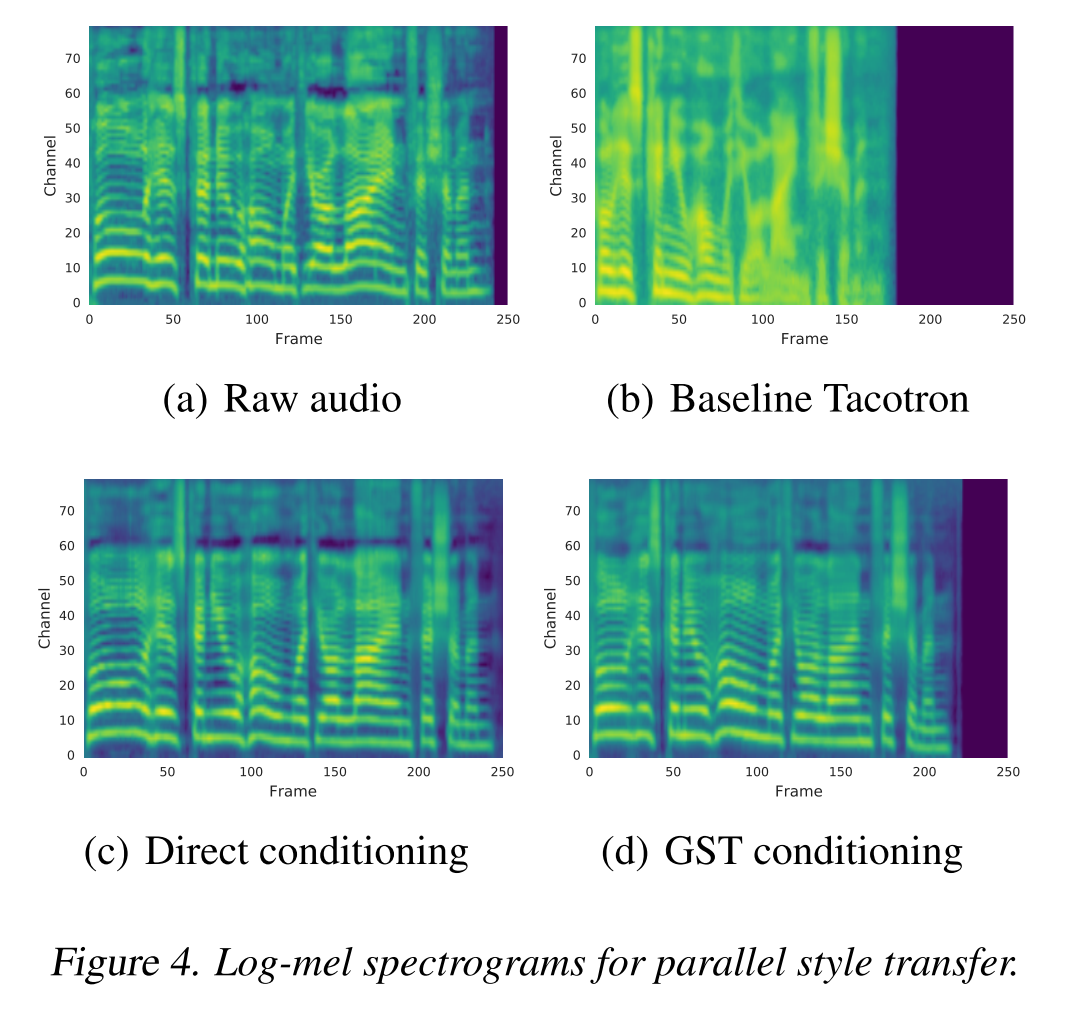
GST conditioning으로 parallel하게 만들어낸 source text의 멜 스펙트로그램을 baseline tacotron과 (text encoder를 reference embedding으로) direct conditioning으로부터 나온 결과와 비교해 보았다. tacotron은 레퍼런스 음성의 운율을 잘 잡아내지 못하는 모습을 보이고, direct conditioning은 거의 유사하게 잡아낸다. 그리고 GST conditioning의 결과는 그 중간 쯤에 위치하며 레퍼런스 음성의 style을 닮은 음성을 합성하는 것을 알 수 있다.
- non-parallel style transfer
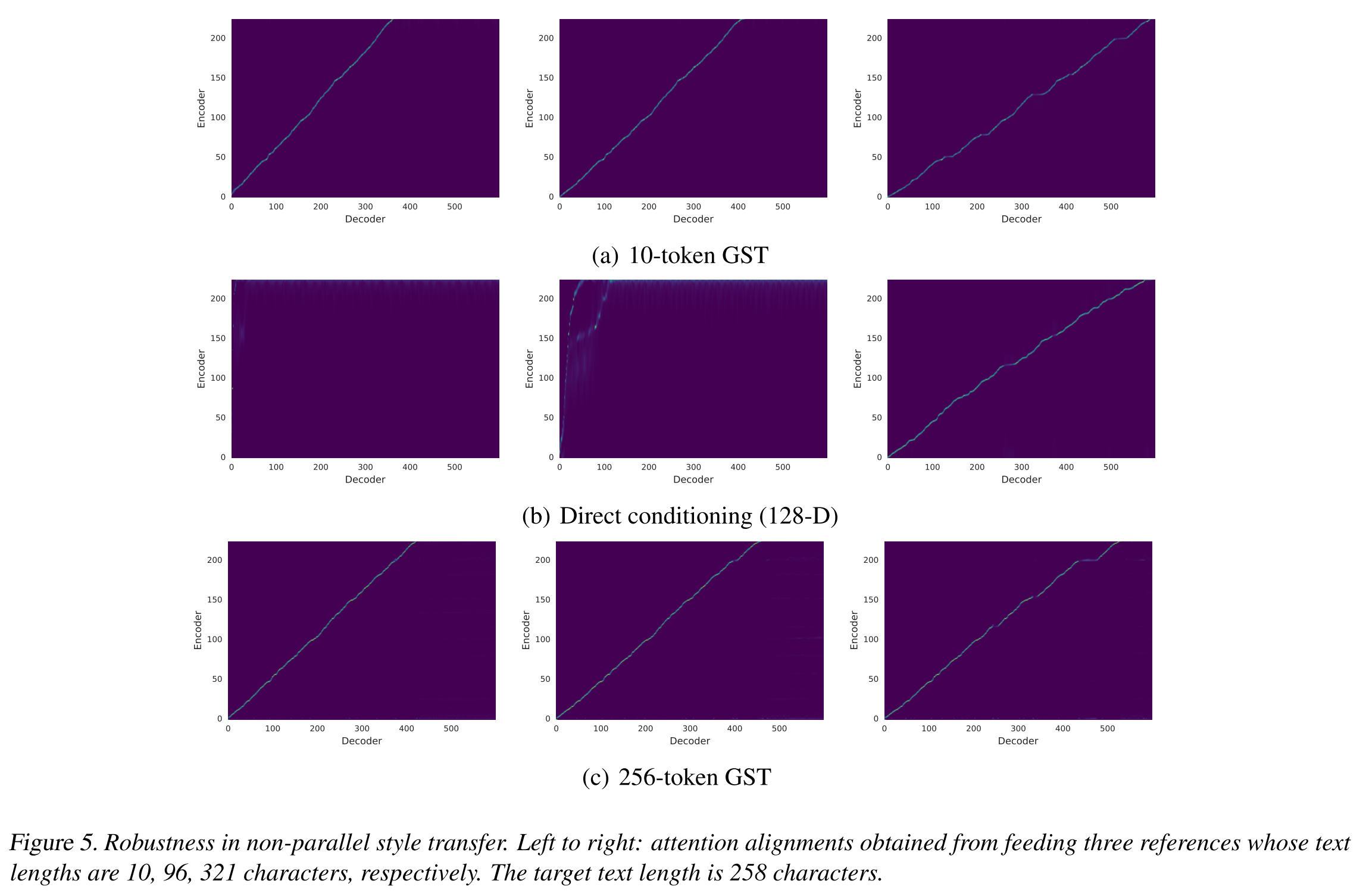
같은 긴 문장을 합성할 때 레퍼런스 음성의 길이에 따라 GST가 스타일을 복제해내는 능력이 달라지는지 테스트해보았다. 위의 그림5는 direct conditioning과 GST token의 개수를 10, 256개로 조절한 경우에 3개의 레퍼런스 음성에 따른 attention alignment를 보여준다. 10-token GST의 경우 모든 음성에 대해 robust한 결과를 보여주고, direct conditioning은 짦은 레퍼런스 음성을 사용한 경우에는 alignment를 학습하지 못하는 결과를 보여준다. 아마도 이 경우엔 레퍼런스의 스타일을 배우는 것이 아니라 레퍼런스 음성과 아주 똑같은 시간 간격 안에 합성음을 압축시키려고 시도하기 때문인 것으로 추측된다. 반면에, 256-token GST는 direct conditioning의 임베딩 차원보다 더 큰 수의 token을 가지고 모델링을 하는 데도 tacotron의 attention alignment 학습을 안정적으로 유지하는 것을 볼 수 있다.
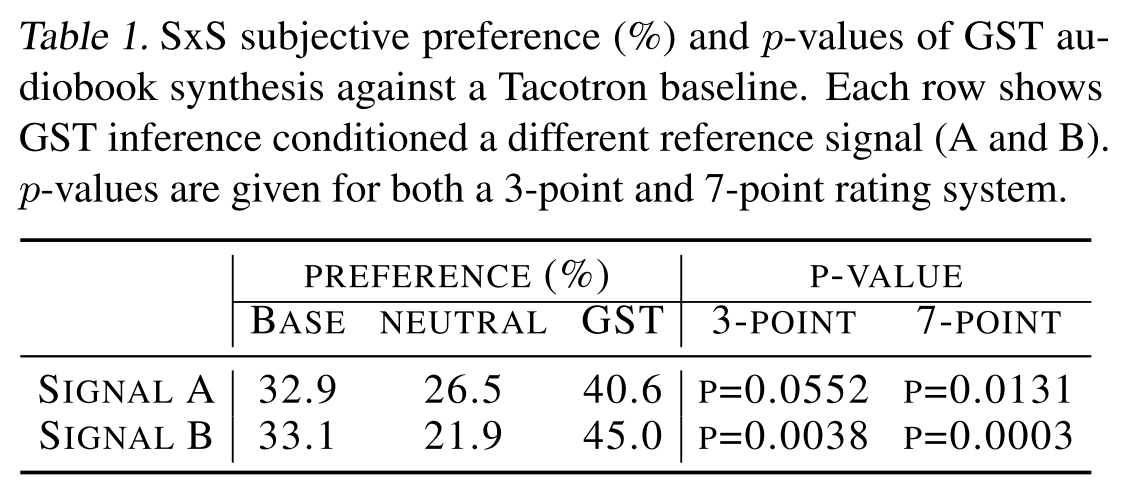
그리고 non-parallel하게 합성한 GST의 음성과 baseline tacotron의 음성으로 side-by-side 테스트를 진행해 봤을 때 GST의 preference가 더 높으므로 GST가 좀 더 robust하게 다양한 스타일의 음성을 합성해내는 능력이 있다고 할 수 있다.
Speech Synthesis with Unlabeled Noisy Data
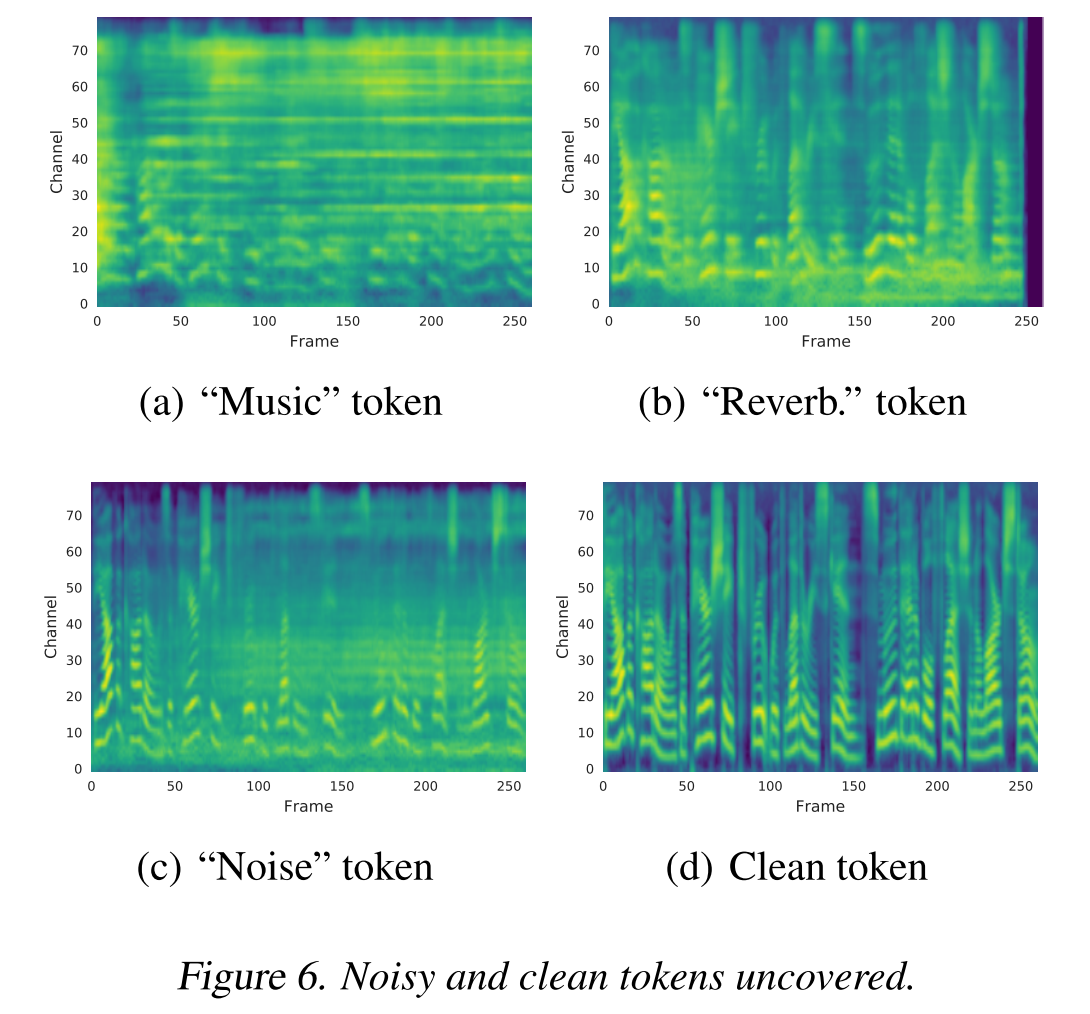
training set에 artificial noisy data를 섞어서 학습시켰을 때 신기하게도 그림 6과 같이 각 token에는 각기 다른 특징의 noise들이 흡수되는 것을 알 수 있다.
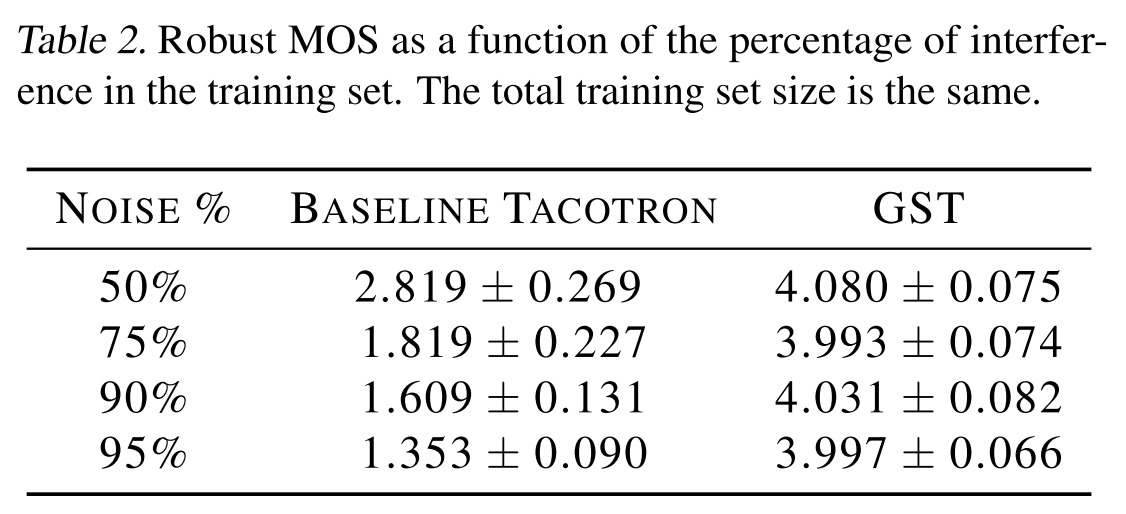
GST가 noise와 clean token을 구분해서 배울 수 있는 것을 알았으므로 clean token만을 conditioning으로 주면 깨끗한 음성을 합성할 수 있을 것이다. 이런 아이디어를 가지고 baseline tacotron과 MOS를 비교했을 때 표 2와 같이 GST는 noise 음성의 비율에 따라 크게 변하지 않고 높은 성능을 기록하는 반면, baseline tacotron은 noise를 분별해내는 능력이 없기 때문에 매우 저조한 MOS를 기록하는 것을 알 수 있다.
Speech Synthesis with Multi-Speaker Data
다화자 음성 데이터로 학습한 GST 모델은 각 token에 화자의 특성을 배울 수도 있다.
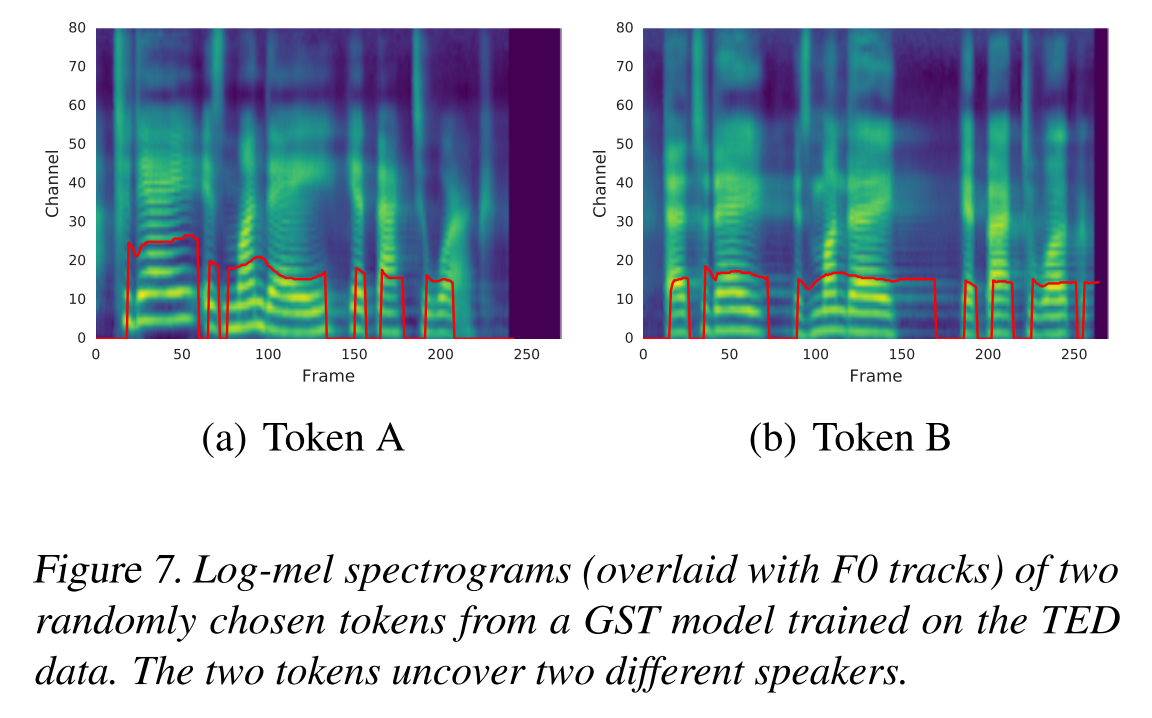
그림 7은 두 개의 token으로 합성한 같은 문장의 멜 스펙트로그램을 보여주는데 두 음성의 스타일이 확연히 다른 것이 보이고 그 둘은 training set에 있었던 특정 화자의 스타일이다.
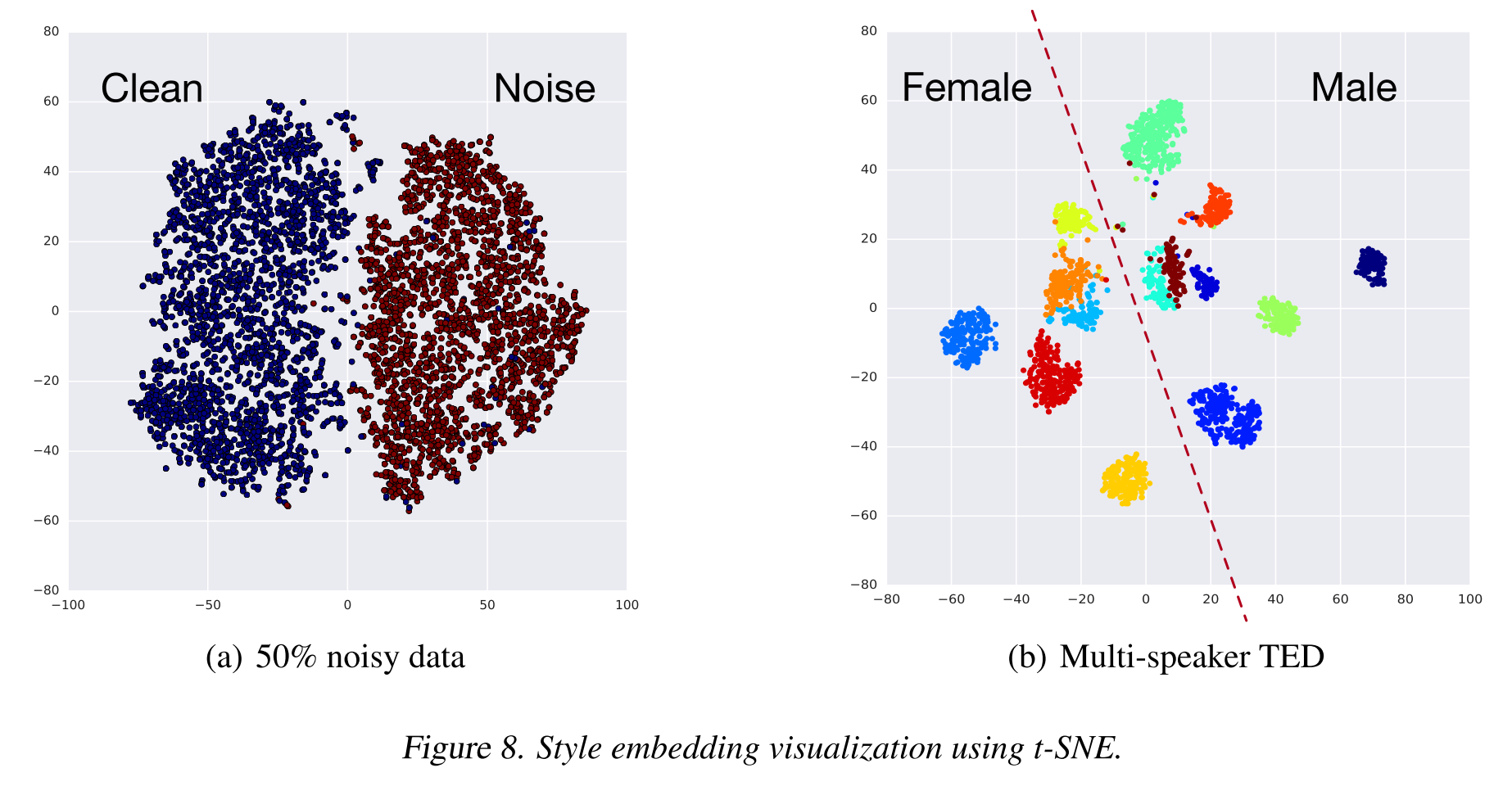
t-SNE로 noisy, multi-speaker 각 데이터셋으로 학습한 모델의 style embedding을 시각화 했을 때 정말로 각 token 별로 구별되는 특징을 학습해서 군집화가 잘 이루어져 있는 것을 볼 수 있다. 저자들은 GST의 능력을 활용해 noise classification과 speaker classification이 가능하다고 보고 추가 실험을 진행했다.

표 4를 통해 GST가 99.2%의 높은 정확도로 noise가 섞인 음성을 분류할 수 있고 화자도 speaker verification을 위해 설계된 i-vector method보다 높은 정확도로 분류해내는 것을 알 수 있다.
의견
- 본 논문에서 Tacotron을 약간 수정하여 만든 baseline이 Tacotron 논문에서 나왔던 MOS보다 높은 MOS를 기록했기 때문에 더 강력한 baseline이라고 주장하는 것은 근거가 부족하다. 같은 eval set을 쓴 경우이긴 하지만 MOS에 영향을 미치는 요소는 그 외에도 다양하다.
- GST layer의 token 개수를 어떻게 설정하는지가 모델의 성능과 활용 가능성에 큰 영향을 미치는 만큼 이에 대한 기준이 마련되어야 할 것이다.
- 결국 스타일이 명확히 구분될만한 음성 데이터셋을 갖추는 것이 매우 중요해 보인다.
- polyphone disambiguation 문제도 GST를 이용해 풀어보면 어떨까?
- reference를 mel frame으로 하고 mel frame별 style을 발음으로 정의하여 style token을 학습할 수 있으려나…




Leave a comment