
Generalization Ability of MOS Prediction Networks
Cooper, Erica, et al. “Generalization ability of mos prediction networks.” arXiv preprint arXiv:2110.02635 (2021).
들어가며
합성된 음성의 MOS를 예측하는 시도가 계속 되고 있지만 MOS 데이터셋 별로 청취자들, 음성을 합성해 낸 시스템(음성 합성 모델), 음성의 특성, MOS 평가 가이드 등의 환경이 모두 다르기 때문에 본질적으로 어려울 수 밖에 없다. 그래서 어떤 MOS predictor가 같은 데이터셋 내에서 예측을 높은 정확도로 할 수 있다고 하더라도 다른 MOS 평가 결과는 거의 맞추지 못하는 일반화 실패의 문제가 생긴다.
본 논문에서는 위와 같은 MOS 예측에서의 일반화 문제를 정확히 진단하고 해결책을 찾아보고자 딥러닝 모델을 활용해 다양한 MOS 평가 데이터셋에 대한 성능을 측정한다.
핵심 요약
- MOS prediction에 맞게 fine-tuning된 wav2vec2모델은 out-of-domain 데이터에 대해서도 높은 일반화 성능을 갖고 있다.
- MOS prediction에 있어서 unseen system이 가장 어려운 unseen condition이다.
- MOS prediction을 위해 제시되었던 MOSNet은 처음부터 학습시키기 위해서는 많은 양의 데이터가 필요하지만, 적은 양의 데이터로 fine-tuning을 하는 것이 성능 면에서 훨씬 좋다.
데이터셋
크게 in-domain data와 out-of-domain data로 나뉜다.
In-domain data
저자들이 직접 과거에 진행되었던 음성 합성 챌린지나 오픈 소스를 통해서 수집한 데이터로 새롭게 청취 평가를 진행한 대규모 데이터셋으로, 대부분의 샘플이 ‘Blizzard Challenge for TTS and the Voice Conversion Challenge’에서 기원하여 BVCC라고 이름을 붙였다. BVCC는 주로 영어로 이루어진 데이터셋이다.
Out-of-domain data
새롭게 청취 평가를 진행하지 않고 외부에서 그대로 가져온 MOS 데이터셋이다. 데이터셋별로 저자들이 의도한 특징을 가지고 있으며, 이들은 추후 BVCC로 이미 학습되었거나 fine-tuned된 딥러닝 모델을 fine-tuning하는 목적으로 사용되거나 testing을 위해 쓰인다.
- ASV2019: 영어 기반. anti-spoofing을 위해 만들어진 데이터셋이다. MOS prediction과는 목적으로 하는 task가 다르기 때문에 데이터셋에 분포하는 rating의 비율이 기존 MOS 데이터셋과는 색다르다.
- BC2019: 중국어 TTS 샘플들에 대한 데이터셋이다. 즉, 이 데이터로 다른 언어로부터 오는 예측의 어려움을 평가해볼 수 있다.
- COM2018: 9개의 시스템 조합(acoustic model+vocoder model)과 일본어 샘플들에 대한 데이터로, 시스템의 변화 뿐만 아니라 언어의 영향까지 모두 포함하여 평가할 수 있다.
데이터셋 특징 및 분포
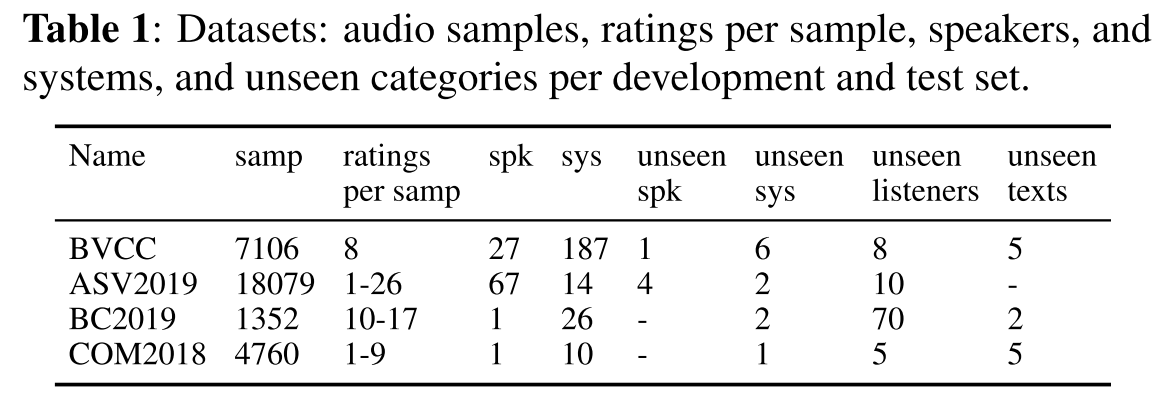
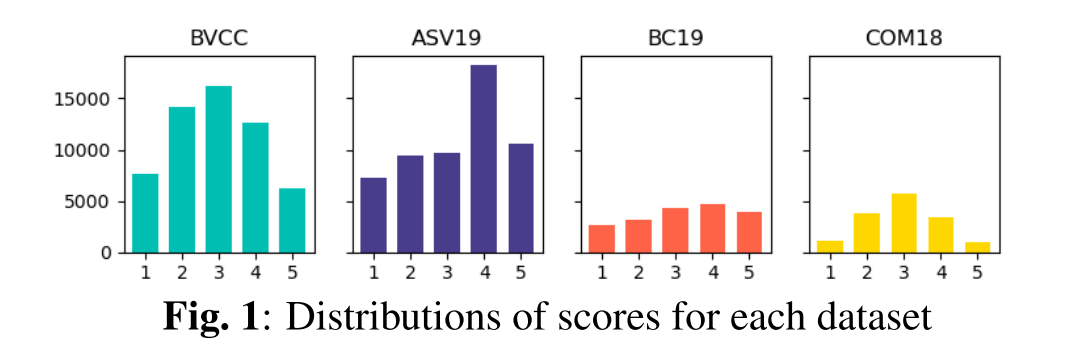
평가 모델
평가 모델로는 MOSNet, wav2vec2, HuBERT를 사용한다.
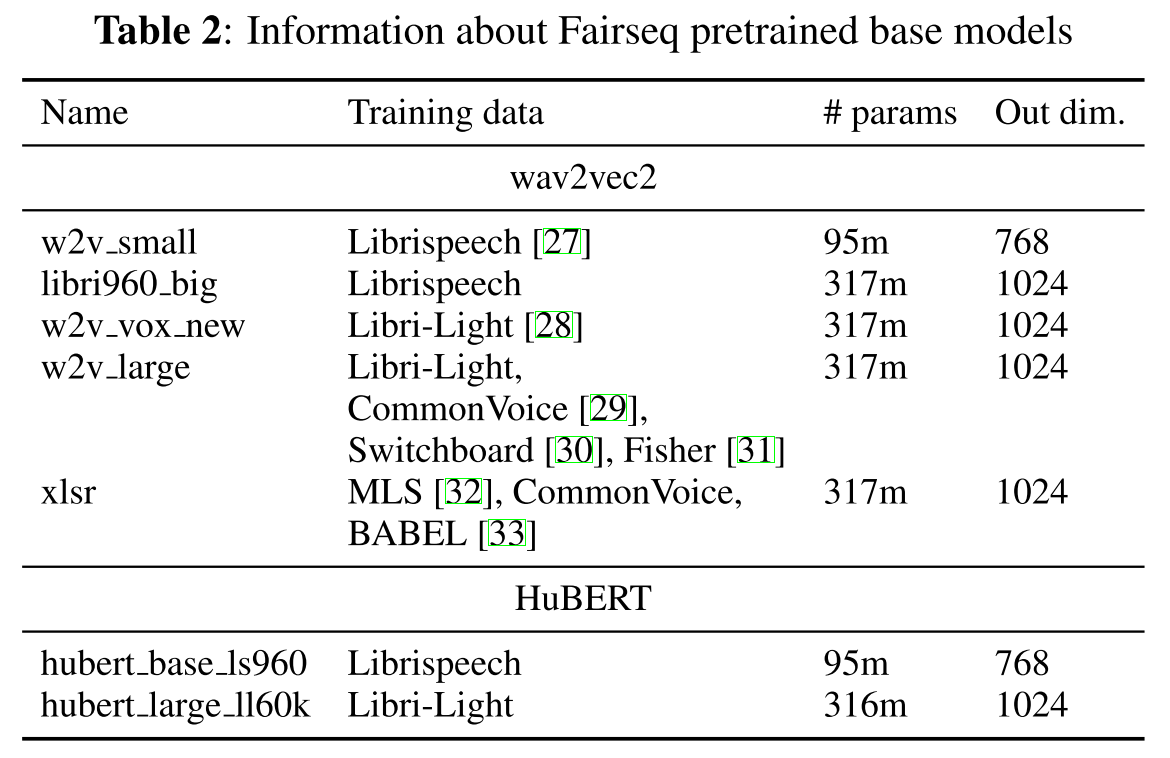
wav2vec2, HuBERT 모델의 pretrained 모델을 가져다가 사용하며, 세부적인 정보는 표2에 나타나 있는 바와 같다.
실험 결과
In-domain data에 대한 평가
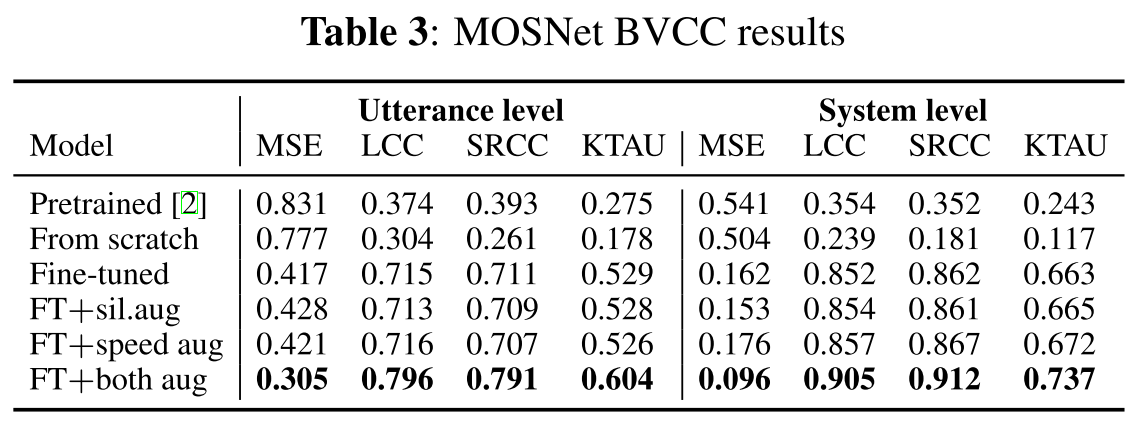
MOSNet은 BVCC로 scratch부터 학습한 모델이 pre-trained(VCC2018)를 사용했을 때보다 성능이 더 안 좋은 것을 알 수 있다. 이는 pre-training에 쓰인 VCC2018의 training set이 훨씬 크기 때문이고 따라서 MOSNet은 많은 양의 데이터로 학습해야 한다는 것을 알 수 있다. 하지만 pre-trained모델을 fine-tuning 한 경우를 보면 성능이 크게 좋아지기 때문에 scratch 보다는 이 방법을 택해야 한다. 그리고 음성 데이터의 속도를 느리게 혹은 빠르게 변화를 주거나 silence를 추가적으로 주입해주는 augmentation 방식도 적용해보았을 때, 두 방법을 모두 적용하여 학습시킨 모델의 성능이 utterance, system level에서 가장 높았다.
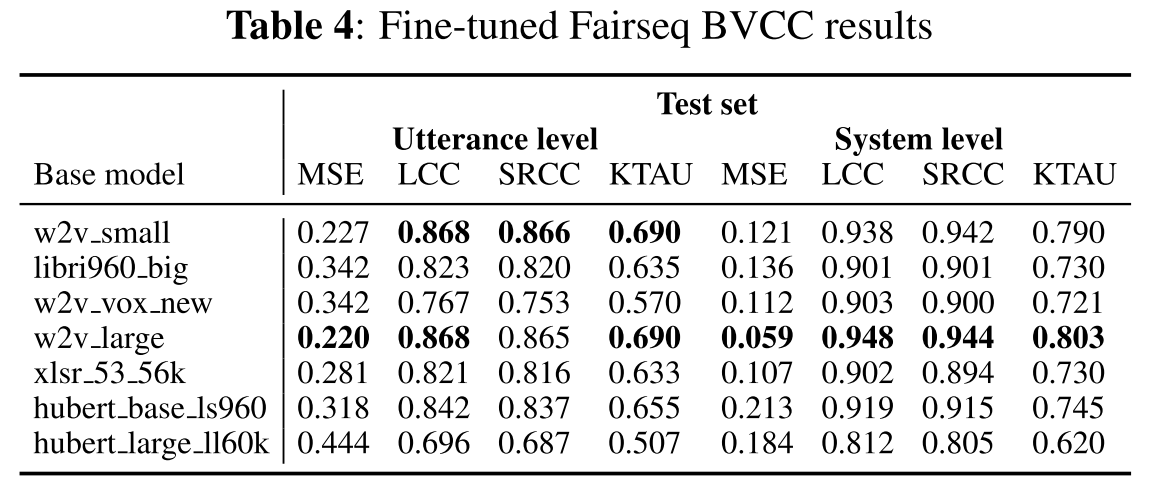
그동안 fine-tuned speech self-supervised-learning-based(SSL) 모델들이 다양한 downstream task에서도 높은 성능을 보여주었기 때문에 비슷한 기대를 하면서 wav2vec2와 HuBERT에 대해서도 실험하였다. BVCC의 training set으로 fine-tuning을 한 후 평가한 결과가 표4와 같다. HuBERT가 거의 모든 task에서 더 높은 성능을 보였던 기존의 연구들과는 달리 wav2vec2 모델의 성능이 좋은 경우도 몇몇 보인다.
Out-of-domain data에 대한 평가
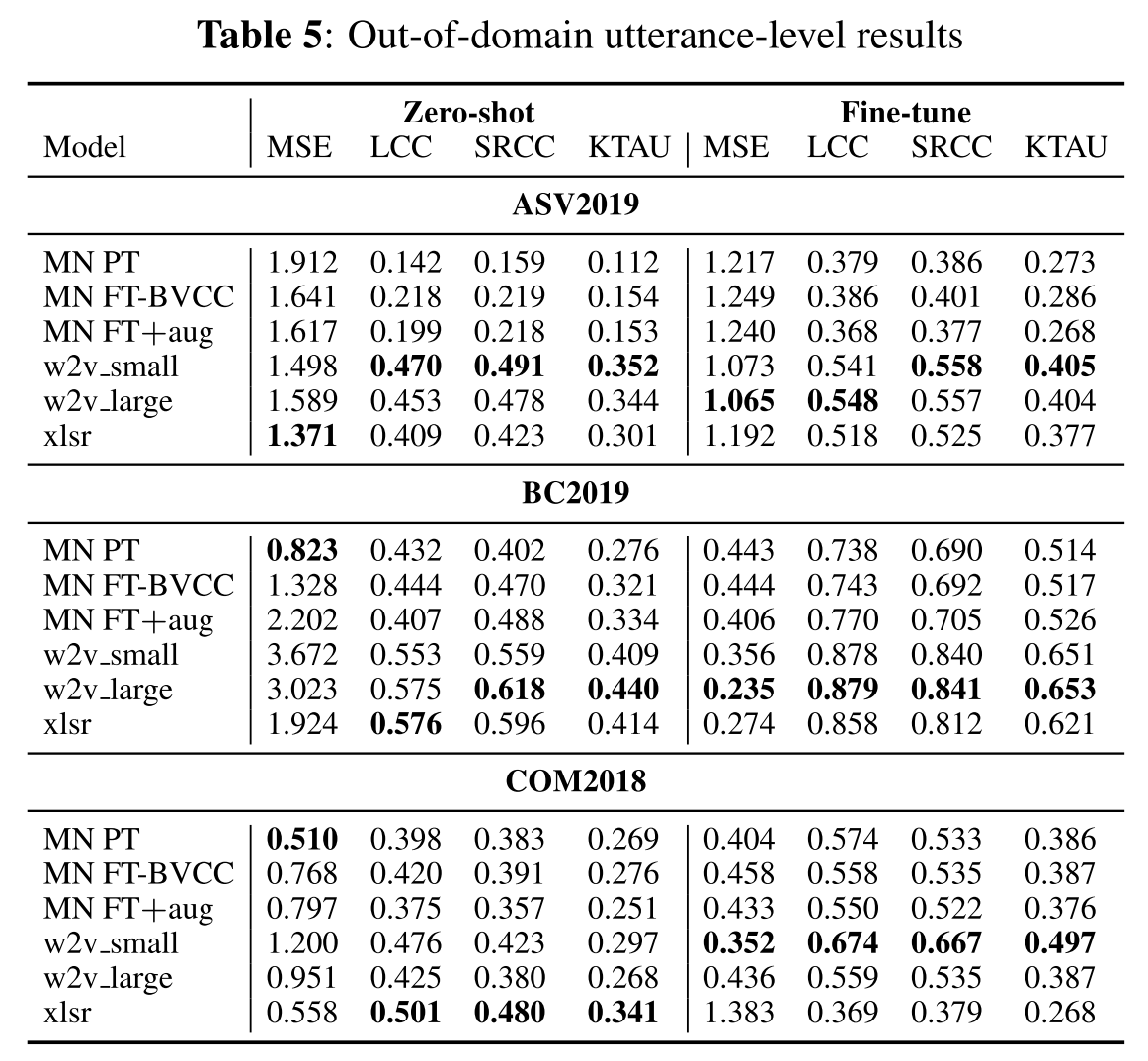
out-of-domain에 대해서 평가할 때는 MOSNet(MN)과 wav2vec2모델의 일부를 선정하여 진행했다.
일단 역시 기대했던대로 zero-shot 예측은 어렵지만, fine-tune을 할 경우 모든 모델의 성능이 향상된다. 그리고 거의 모든 데이터셋과 예측 방식(zero-shot이냐 fine-tune이냐)에 대해서 wav2vec2 모델의 성능이 가장 좋으므로 이 모델의 일반화 성능이 가장 좋다고 할 수 있다.
Unseen category에 대한 분석
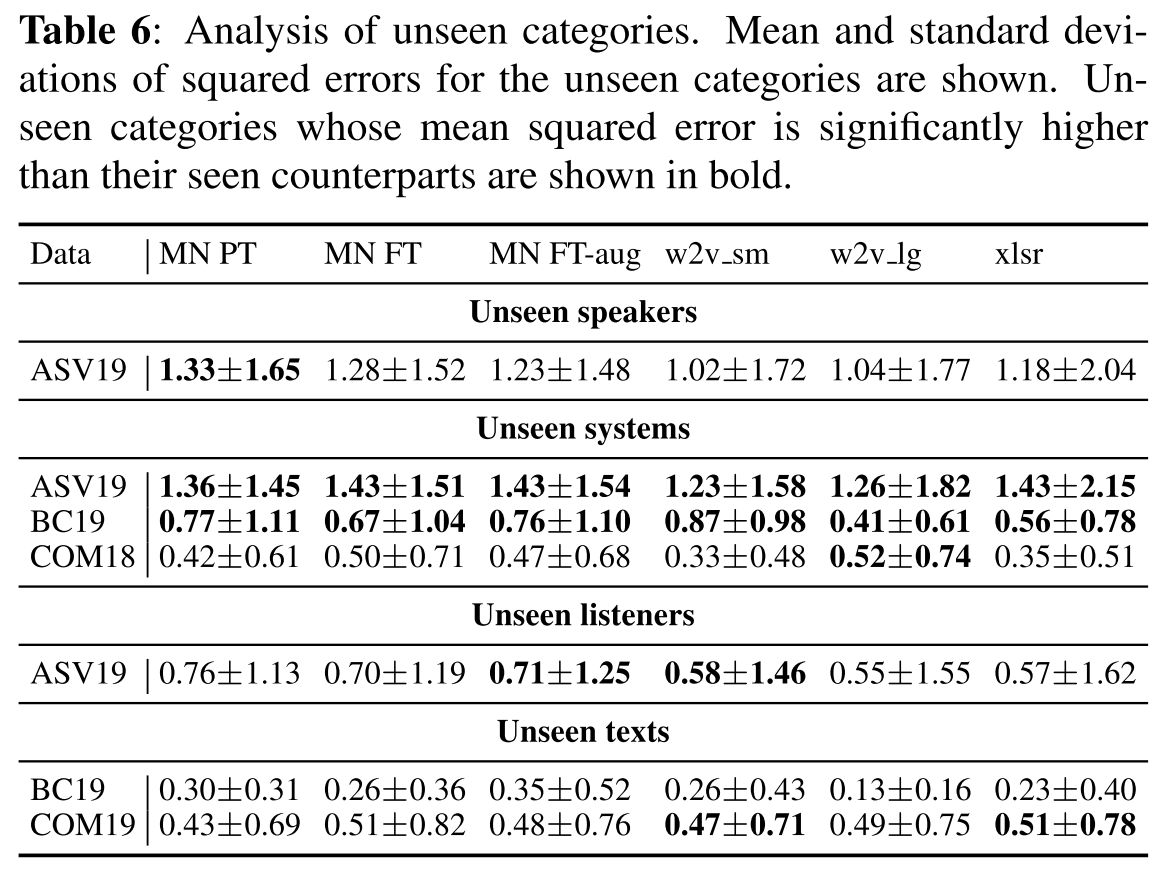
표 6은 unseen category 별로 각 모델의 MOS prediction에 대한 squared error의 평균을 나타낸 것이고, seen category에 대한 결과와 unseen category에 대한 결과가 양측 T-검정을 통해 유의미한 차이를 가진다는 결과가 나오면 bold로 표시하였다.
위의 표를 해석해보면, unseen system을 모든 모델이 예측하기 힘들어했는데 어떻게 보면 우리가 MOS predictor를 사용해야 하는 대부분의 경우가 다른 음성 합성 모델에 대해서 훈련된 MOS predictor를 현재 새롭게 개발하고 있는 모델에 대해서 적용해야 하는 것이므로 가장 필요한 경우에 대해서 어려움이 현저히 크게 나타났다고 볼 수 있다.
unseen text, speaker, listener에 대한 예측은 대부분의 모델이 seen의 경우와 비슷하게 하고 있는 것을 보아 학습이 어려운 부분은 아니라고 판단된다.
의견
- 동일한 저자들이 같은 시기에 연구하던 LDNet이라는 MOS predictor가 있는데 그것도 함께 실험해보았으면 좋았을 것 같다.
- MOS 예측 결과에 대한 심도 있는 고찰이 인상 깊고, 실험을 잘 설계하는 것만으로도 좋은 논문을 쓸 수 있다는 것을 배울 수 있었다.
- SSL 기반의 speech model들을 다양한 task에 적용해보는 경험을 해봐야겠다.
- 같은 모델에 한해서는 MOS 예측 성능을 어느 정도 신뢰할 수 있을거라는 결론을 갖고 앞으로 TTS 모델 verification에 사용해봐도 괜찮겠다.




Leave a comment