
Glow-TTS
Kim, Jaehyeon, et al. “Glow-TTS: A generative flow for text-to-speech via monotonic alignment search.” arXiv preprint arXiv:2005.11129 (2020).
들어가며
자기회귀 TTS 모델은 높은 음성 합성 품질에도 불구하고 실시간 서비스에 적용하기에 무리가 있다. 출력 길이에 따라서 추론 시간이 선형적으로 증가하기 때문에 바람직하지 않은 지연이 발생하고 이는 TTS 시스템 내의 여러 파이프라인에 악영향을 끼칠 수 있다. 또한 대부분의 자기회귀 TTS 모델은 특수한 경우에 강건성이 부족한 모습을 보이는데 일례로, 입력 문자열이 반복되는 문자를 포함하고 있으면 어텐션에 치명적인 오류가 생긴다.
이런 문제점을 극복하기 위해 FastSpeech와 같은 병렬 TTS 모델이 제안되었지만 사전 학습된 자기회귀 TTS 모델로부터 어텐션 맵을 추출해서 사용하기 때문에 모델의 성능이 이러한 외부의 정렬기(aligner)에 많이 의존한다는 단점이 있다.
따라서 본 연구에서는 외부 정렬기의 필요성을 없애고 모델 자체적으로 어텐션 정렬을 학습할 수 있는 flow 기반의 생성 모델을 제안한다.
핵심 요약
- flow와 dynamic programming의 특성을 결합하여 문장-음성(의 잠재적 표현) 사이의 가장 적합한 monotonic 정렬을 찾아낸다. 본 논문에서는 이 방법을 Monotonic Alignment Search(MAS)라고 명명하였다.
- 기존 TTS 모델에서 텍스트 길이가 증가함에 따라 추론 시간과 오류가 증가하는 문제를 해결하였다.
- 억양, 피치, 속도, 화자 등을 조절하여 다양한 음성을 합성할 수 있는 모델이다.
학습 및 추론 절차
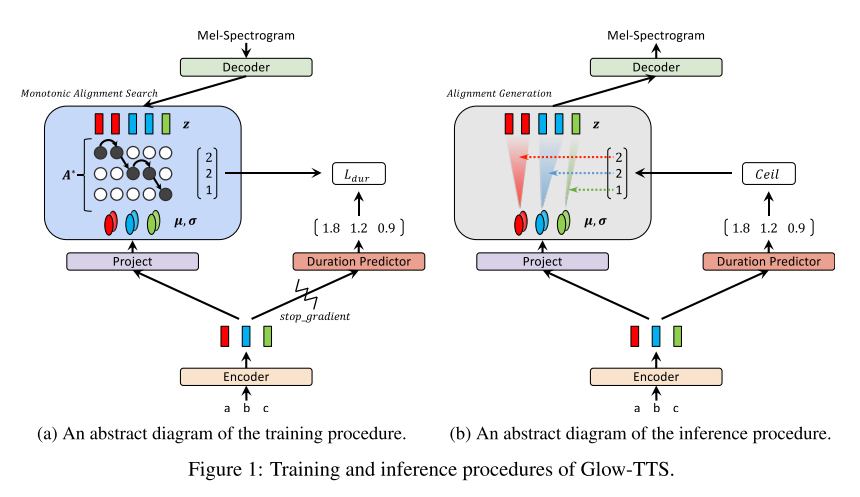
학습의 최종 목적은 학습 데이터의 로그 우도를 최대화 시키는 파라미터 Theta와 정렬 함수 A를 찾는 것이다.
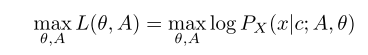
그러나 전역 최적해를 찾는 것은 계산적으로 불가능에 가깝기 때문에 목적 함수를 두 개의 하위 문제로 나누어서 해결하는 방식을 제안한다. (dynamic programming 활용)
-
(정렬 업데이트) 현재 파라미터에 대해서 적합한 정렬 A*를 찾는다.
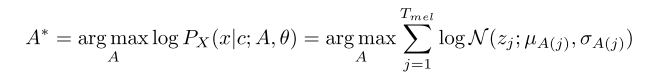
-
(파라미터 업데이트) 정렬 A*와 파라미터에 대한 로그 우도를 최대화 시키도록 파라미터를 업데이트한다.
학습 단계
- 학습 단계에서 MAS를 통해 적절한 monotonic alignment를 찾아내고 경사 하강법을 통해 파라미터를 업데이트한다.
- duration predictor: 추론 단계에서는 탐색 없이 적절한 정렬을 추정하기 위해 duration predictor도 학습 단계에서 함께 학습을 시키는데 손실은 로그 스케일에서의 MSE로 계산한다. 그리고 인코딩된 벡터와 duration predictor 사이의 그래디언트를 끊음으로써 duration predictor의 입력이 최종 목적함수인 최대우도 계산에 영향을 끼치지 않도록 설정하였다. 즉, 인코딩을 진행하는 인코더의 파라미터가 duration을 예측하는 성능에 의해서 업데이트되지 않고 오로지 최대우도를 만들기 위한 방향으로만 업데이트가 되도록 유도한 것이다.
추론 단계
- 추론 단계에서는 사전 분포의 통계량과 duration predictor로부터 구해진 구간 길이 정보를 활용해 사전 분포에서 잠재 변수를 샘플링한다.
- 그리고 flow 기반의 디코더를 통해 병렬적으로 멜 스펙트로그램이 합성된다.
Monotonic Alignment Search (MAS)

- 사람이 텍스트를 읽을 때 단어들을 순서대로 건너뛰지 않고 읽는 것에 착안하여 monotonic하고 non-skipping 정렬을 따르는 멜 스펙트로그램을 생성하도록 만든 탐색 방법이다.
- 사전 분포의 통계량과 잠재 변수의 인덱스 범위가 각각 주어졌을 때, 최대 로그 우도를 계산하여 Q라는 행렬로 저장하고 이를 역행하면서 적합한 정렬 A*를 찾는다.
- MAS의 시간복잡도는 O(T_text * T_mel)이고, CPU만으로도 충분한 계산이다.
- 추론 단계에서는 MAS를 사용하지 않는다.
모델 구조
인코더와 Duration Predictor
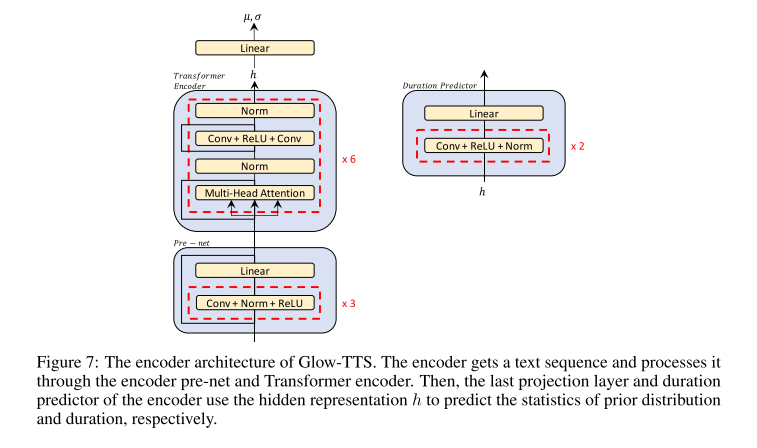
인코더는 Transformer TTS의 인코더를 약간 변형시킨 구조이다. positional encoding 대신에 relative position representation을 사용한 것과 pre-net에 residual connection을 추가한 것이 차이점이다.
duration predictor는 FastSpeech의 duration predictor 구조와 동일하며, 두 개의 Conv layer와 한 개의 Linear layer로 이루어져 있다.
디코더
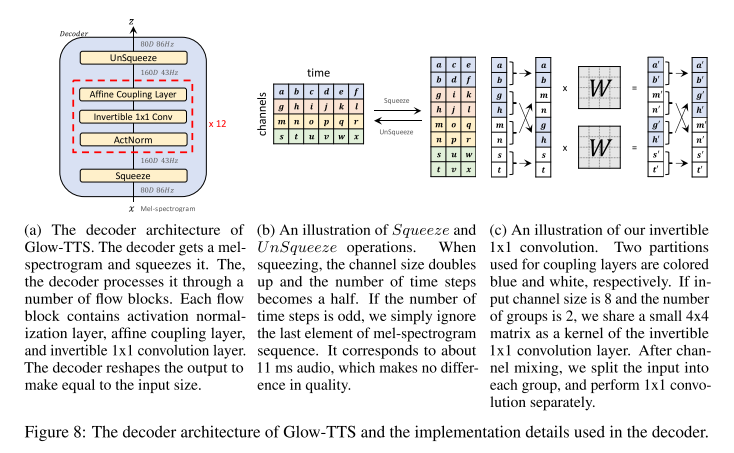
디코더는 Glow-TTS에서 가장 중요한 부분으로써 학습 시에는 멜 스펙트로그램을 잠재적 표현으로 효율적으로 변환시켜야 하고, 추론 시에는 사전 분포를 멜 스펙트로그램으로 변환시킬 수 있는 구조여야 한다. 그래서 이 디코더는 forward와 inverse 변환이 병렬로 가능한 flow 구조를 채택하고 있으며 이들이 연속적으로 쌓여 있는 구조를 가진다. flow 내부의 affine coupling layer는 WaveGlow의 구조에서 local conditioning을 제외한 형태라고 한다.
실험 결과
모든 실험에서 입력 토큰으로 phoneme을 사용했으며, 보코더는 WaveGlow를 사용했다. 그리고 학습 시 사전 분포의 표준 편차는 간단하게 1로 고정시켰다.
오디오 품질
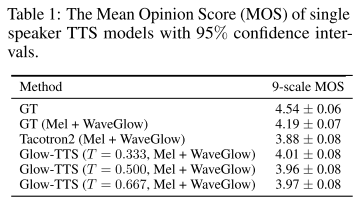
사전 분포의 표준 편차를 변화시켜 가며 실험해 봤을 때 tacotron2보다 Glow-TTS가 항상 높은 MOS를 보였다.
샘플링 속도와 강건성
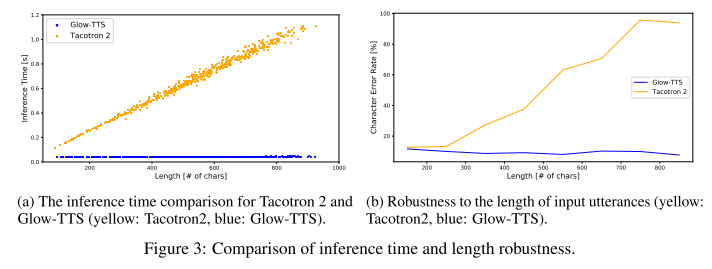
Glow-TTS는 입력 텍스트의 길이에 상관 없이 추론 시간이 일정한 반면, tacotron2는 선형적으로 증가하므로 Glow-TTS의 샘플링 속도가 훨씬 빠른 것을 알 수 있다. 그리고 입력 텍스트 길이에 따른 CER을 보았을 때도 Glow-TTS는 항상 낮은 에러율을 보여주기 때문에 강건성을 가졌다고 말할 수 있다.
다양성과 조절 가능성
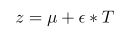
사전 분포에서 샘플링된 잠재적 표현은 위와 같이 표현될 수 있는데, 여기서 epsilon과 T를 각각 조절하면 아래와 같이 intonation과 pitch를 조절할 수 있음을 보인다.
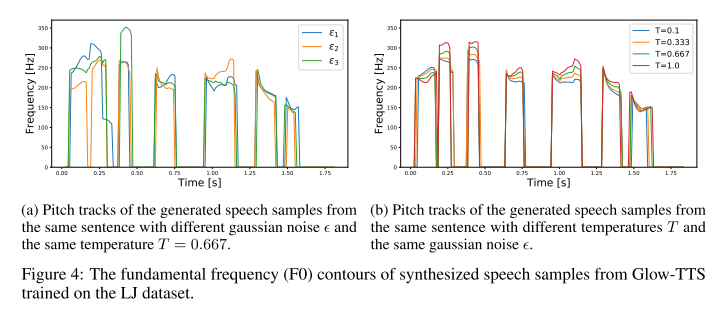
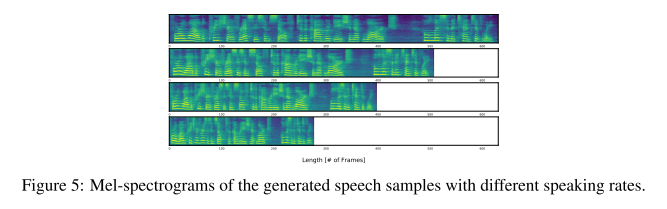
그리고 duration predictor에서 예측한 결과에 스칼라 값을 곱해주면 발화 속도까지 함께 조절할 수 있다.
다화자 TTS
-
오디오 품질
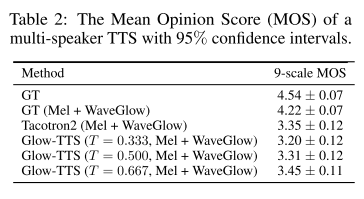
50명의 화자에 대해서 인당 하나의 문장을 무작위로 샘플링하여 TTS를 진행했을 때, Glow-TTS에서 합성한 음성의 MOS가 가장 높았으므로 Glow-TTS가 다화자 TTS도 잘한다고 생각할 수 있다.
-
화자 의존 발화 길이
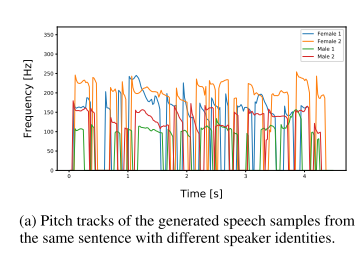
같은 문장이어도 입력해준 화자 정보에 따라서 pitch track이 다른 양상을 보이는 것으로 보아 모델이 화자에 따라 발화 길이가 다른 것을 학습했다고 볼 수 있다.
-
음성 변환
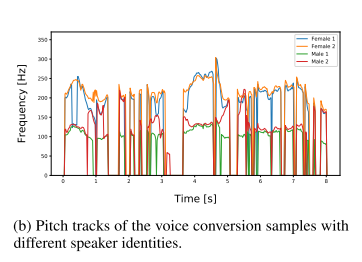
화자 정보는 디코더에 컨디셔닝 정보로 활용될 뿐, 모델의 인코더에 화자 정보를 주입해주지는 않기 때문에 모델이 학습한 사전 분포는 화자 정보와 독립적인 것이다. 이를 달리 말하면 Glow-TTS는 음성에서 잠재적 표현인 z와 화자 정보를 분리시키도록(disentangle) 학습된다. 그리고 실제로 분리되어 학습됐는지 확인하기 위해서 같은 멜 스펙트로그램에 대해서 올바른 화자 정보와 다른 화자 정보를 주입해주었을 때 pitch track을 보면 비슷한 트렌드를 보이지만 다른 pitch를 나타낸다. 따라서 의도한대로 학습되었고, 이를 음성 변환 모델로써 사용할 수도 있음을 시사한다.
의견
- 발음 실수는 없지만 날카로운 잡음이 섞여 있어서 여전히 실용적으로 활용하기는 어렵겠다고 생각했으나, 저자들이 최근에 보코더를 HiFi-GAN으로 수정한 뒤에 합성한 음성은 깨끗한 느낌을 주어 실용적으로 활용하기 좋은 TTS 모델이라 판단된다.
- 모델을 설계할 때는 Transformer TTS, FastSpeech와 같은 다양한 TTS 모델들의 구조를 가져다 썼는데 음성 합성 품질을 비교할 때는 Tacotron2하고만 비교한 것이 약간 아쉽다.

Leave a comment