
Grad-TTS
Popov, Vadim, et al. “Grad-tts: A diffusion probabilistic model for text-to-speech.” arXiv preprint arXiv:2105.06337 (2021).
들어가며
요즘 분야를 가릴 것 없이 diffusion probabilistic model을 이용한 generative model이 인기다. stochastic calculus에 기반한 이 모델링 방법은 유연한 추론을 허용해주기 때문에 복잡한 데이터 분포를 모델링 하는 데 큰 잠재력을 가진다. 이를 TTS에 적용해보고자 하는 것이 Grad-TTS의 취지이다. 기본적으로 인코더-디코더 구조를 가지고 있으며 인코더에서 예측한 noise를 score-based 디코더를 사용해서 멜 스펙트로그램으로 점차 변형시켜 나가는 과정을 통해 음성을 합성한다.
핵심 요약
- Glow-TTS의 Monotonic Alignment Search(MAS)를 활용한 인코더 구조를 사용하고 score-based 디코더를 통해 멜 스펙트로그램을 생성한다.
- 인코더로부터 나온 출력을 파라미터로 사용하여 만들어낸 gaussian noise를 reverse diffusion 과정을 거쳐서 멜 스펙트로그램으로 복원하는 원리를 사용한다.
- reverse diffusion의 iteration을 통해 생성되는 멜 스펙트로그램의 품질과 추론 속도 사이 trade-off를 조절할 수 있다.
모델 구조
Diffusion probabilistic modelling
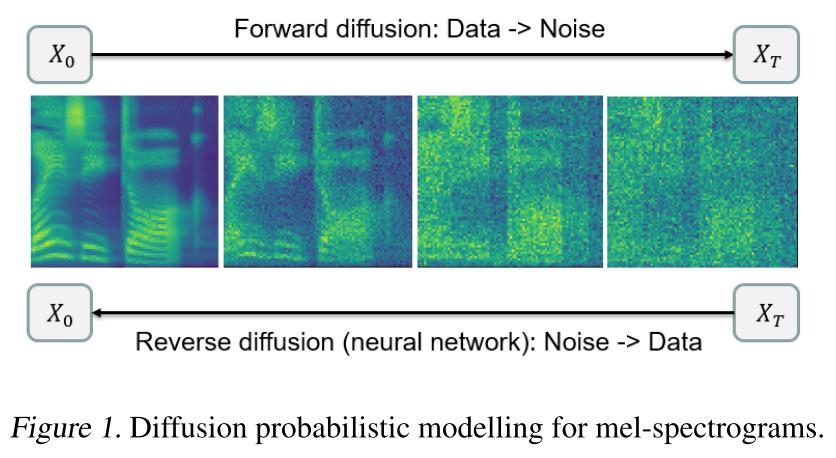
수학자들의 연구를 통해 diffusion 과정은 아래와 같이 stochastic differential equation(SDE)로 표현될 수 있다.
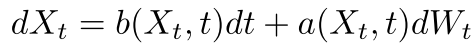
이때, 어떤 데이터를 gaussian noise로 변형시키는 forward diffusion인 n차원의 stochastic process Xt은 아래와 같이 나타낼 수 있다.
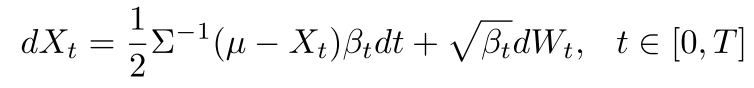
그리고 역과정인 reverse diffusion은 아래처럼 표현되며,
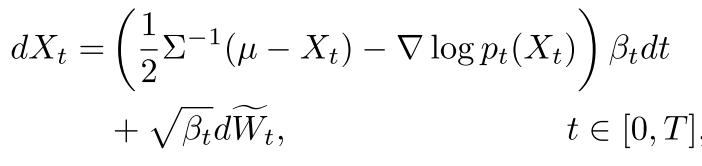
이를 SDE 대신 ODE로 표현할 수 있다는 것이 증명되었다.
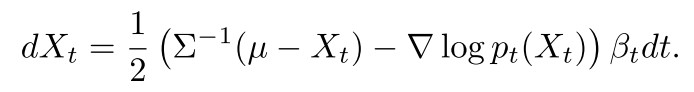
forward와 reverse diffusion 식에서 forward kolmogorov equation을 구해보면 동일하다는 점을 통해, 두 과정에서 pdf의 진화과정이 일치함을 알 수 있다. 따라서 만약 우리가 noisy 데이터 log-density의 gradient를 뉴럴 넷으로 추정할 수 있으면 noisy 데이터에서 샘플링한 값을 통해 원래 데이터의 분포를 모델링할 수 있다.
Inference
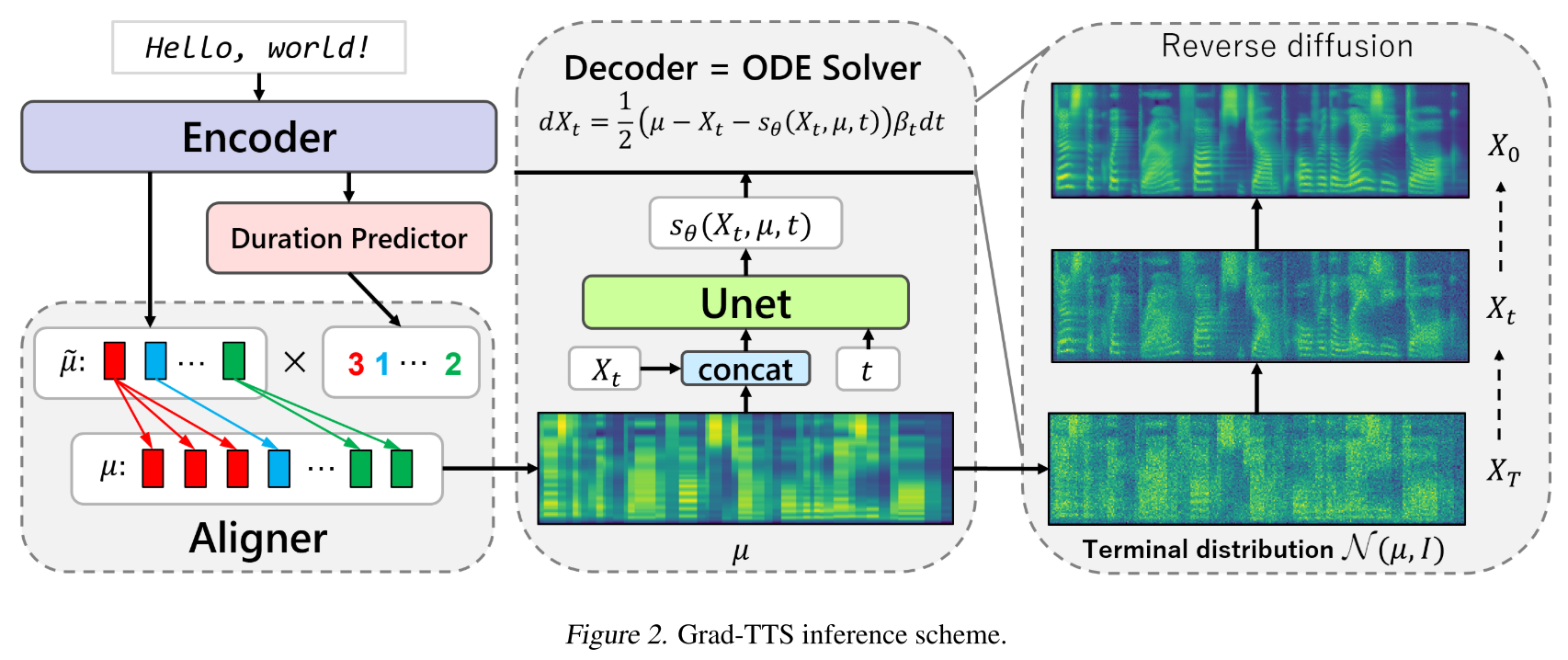
Glow-TTS에서 인코더 부분을 가져와서 MAS를 통해 text와 정렬된 시퀀스를 출력한다. 그리고 이 시퀀스를 평균으로 가지는 gaussian noise를 만들어 reverse diffusion 과정을 진행한다. 자세히는 위의 그림처럼 인코더의 출력을 noise인 Xt와 합치고 U-net을 통과시켜 score matching을 진행한다.
Training
Grad-TTS 학습의 목적은 인코더의 출력 시퀀스와 타겟 시퀀스 사이의 거리가 최소화되도록 하는 것이다. 직관적으로 생각해 봤을 때 이미 처음의 noise가 타겟과 가까운 상태라면 디코딩 과정은 더욱 쉽게 학습될 수 있다. 이로부터 정의되는 인코더 손실 함수는 아래와 같다.
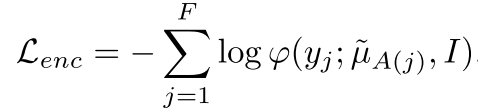
인코더 손실 함수는 인코더의 파라미터와 alignment 함수에 대해서 최적화되어야 하는데 한 번에 학습시키는 것이 어렵기 때문에 두 단계로 나누어 학습을 진행한다. 먼저, 인코더 파라미터를 고정시킨 채 최적의 alignment를 찾고 그 다음엔 alignment를 고정시킨 상태로 인코더 파라미터를 업데이트하는 방식이다. 학습 시에는 alignment를 MAS로 계산하지만 추론 시에는 사용할 수 없으므로 duration predictor를 통해 duration을 구해야 하고 아래와 같은 손실 함수를 통해 학습시킨다.
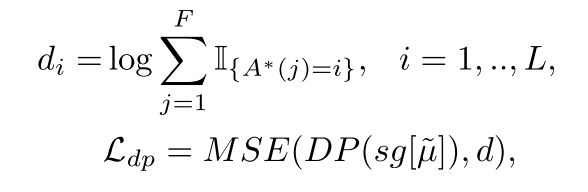
마지막으로 diffusion loss는 다음과 같이 계산된다.
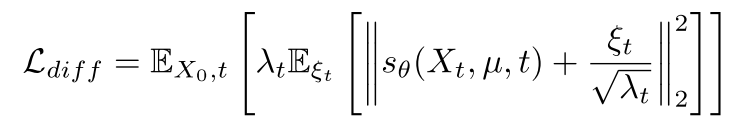
실험 결과
Baseline 비교
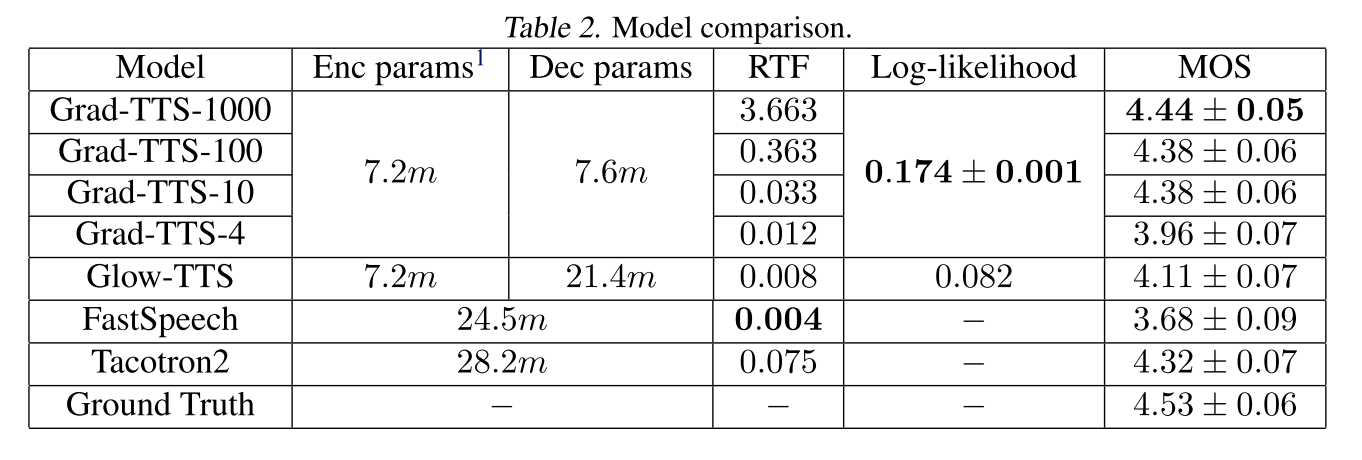
iteration 10만 사용해도 Grad-TTS가 Glow-TTS보다 합성 품질이 좋은 것을 알 수 있고 1000까지 사용하면 autoregressive 모델인 Tacotron2을 능가하면서 GT와 가장 가까운 품질을 보여준다.
Ablation Study
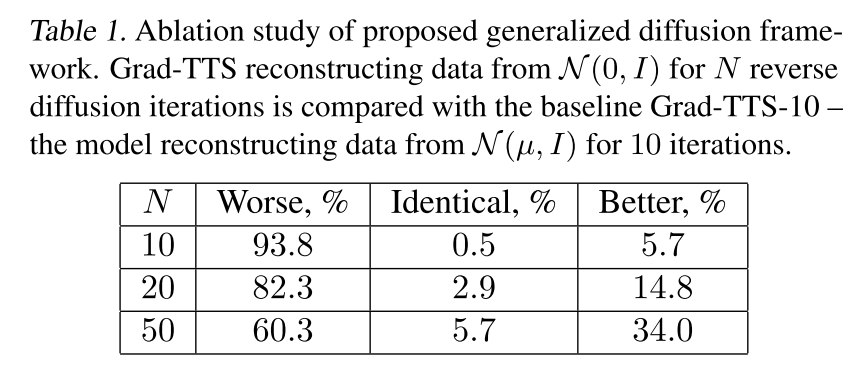
인코더 출력을 파라미터로 사용하여 noise를 출력하는 경우에 iteration 10을 사용한 모델을 Grad-TTS-10이라고 할 때, 일반적인 평균 0인 gaussian noise를 사용하는 경우와 차이가 있는지 비교하였다. iteration을 50까지 늘려도 Grad-TTS-10보다 품질이 떨어진다고 응답한 경우가 많았으므로, 처음의 noise를 인코더 출력으로부터 계산하는 것이 효과적인 방법이라고 판단된다.
Error Analysis
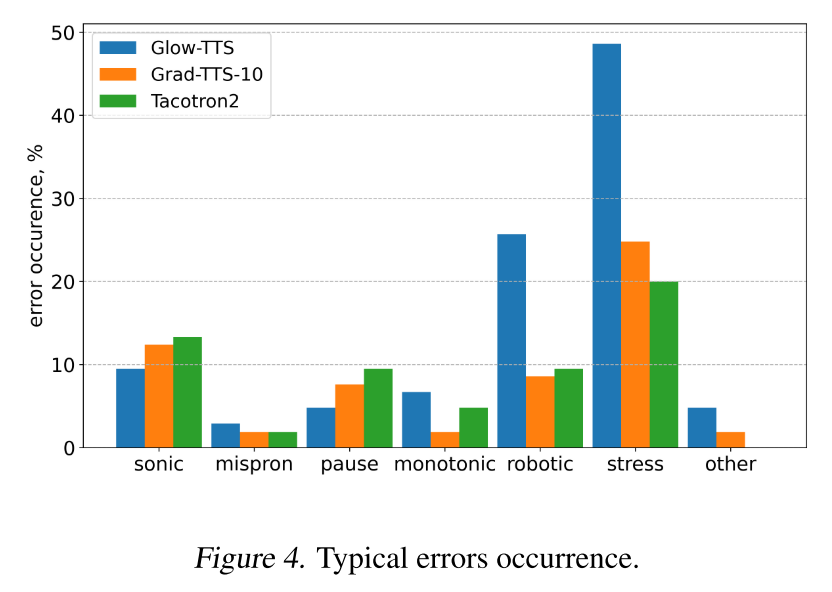
모델별로 어떤 에러들이 많이 발생하는지 비교했다. 전반적으로 Grad-TTS가 Glow-TTS의 에러를 개선한 것으로 보이며, 특히 이상한 강세를 주거나(stress error), 로봇처럼 딱딱하게 읽는(robotic error) 현상이 현저하게 개선되었다.
Inference Speed
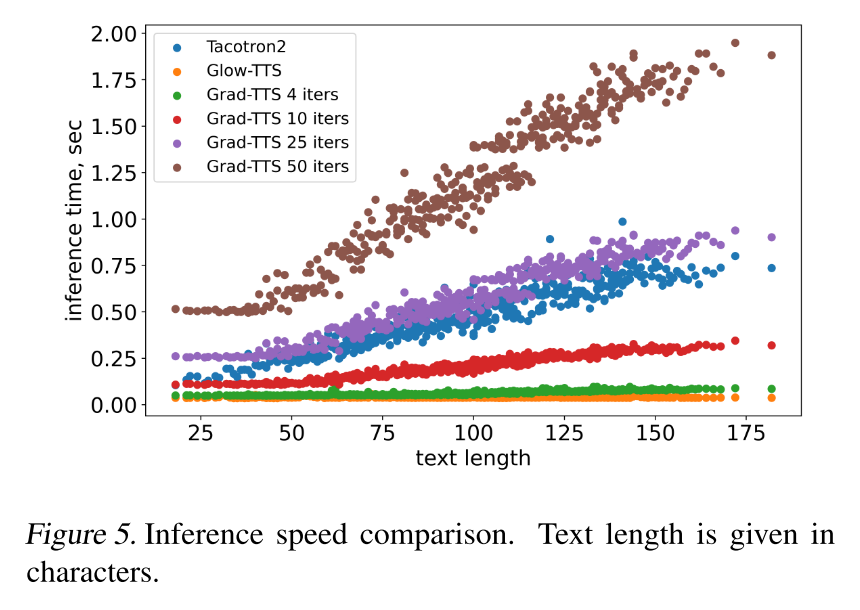
입력 텍스트 길이가 길어질수록 Grad-TTS는 총 iteration 횟수가 배가 되기 때문에 추론 속도가 느려질 수 밖에 없다. 그렇지만 iteration 10을 사용하면 만족할만한 품질로 Tacotron2와 Glow-TTS 사이의 속도로 추론을 진행할 수 있다.
End-to-End TTS
간단하게 E2E TTS가 가능한지도 테스트했다고 한다. 디코더에서 U-Net 구조를 WaveGrad로 대체하면 되는데 충분히 들어줄만한 품질의 오디오를 생성할 수는 있었지만, 두 단계로 진행한 결과와 비교할만한 수준은 되지 못해서 이 모델을 논문에 자세히 언급하지는 않는다.
의견
- WaveGrad를 디코더에 사용할 경우 어떻게 음성의 품질을 높일 수 있을지 고민해봐야겠다.
- 추론 속도가 Glow-TTS에 비해 좀 뒤쳐지기는 하지만 발화의 자연스러움이 개선되었기 때문에 서비스에 적용하기 괜찮은 모델이라고 생각한다.
- DPM을 TTS에 적용한 첫 모델이라 인상적이고, 앞으로 비슷한 연구들이 진행되면서 주류로 자리잡을 수 있을지 기대가 된다.




Leave a comment