
HiFi-GAN
Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis.” arXiv preprint arXiv:2010.05646 (2020).
들어가며
그동안 vocoder 모델에 GAN을 적용하려는 시도가 많이 있었지만, autoregressive 모델이나 flow-based 생성 모델보다 품질이 많이 떨어지는 것이 사실이다. 그래서 본 논문에서는 음성이 여러 주기를 가진 사인 파형의 신호가 합쳐진 결과물이라는 데 착안하여 기존 GAN 기반 vocoder의 한계점을 극복하고 efficiency와 high-fidelity 측면에서 SOTA 성능을 기록하는 HiFi-GAN을 제안한다.
핵심 요약
- AR 모델이나 flow-based 모델보다 연산량은 적고, 높은 품질의 샘플을 합성할 수 있는 GAN 기반 모델이다.
- 음성 신호가 여러 개의 사인파가 합쳐진 형태라는 것에 착안하여 discriminator를 계층적으로 구성하였다.
- GAN loss 뿐만 아니라 다른 손실 함수를 추가하여 generator의 학습을 도왔다.
모델 구조
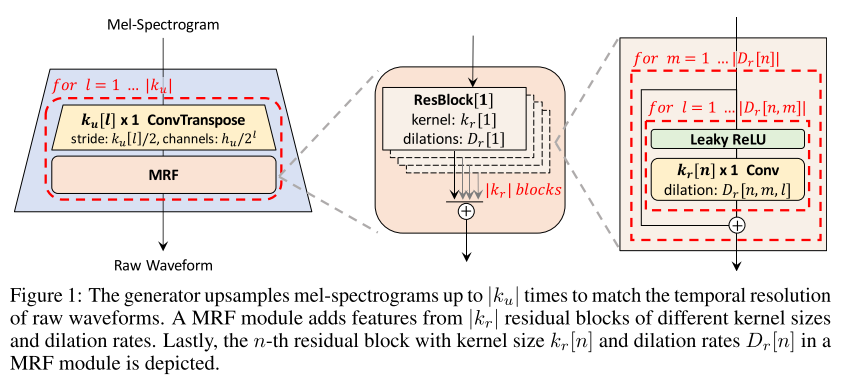
1개의 generator와 2개의 discriminator로 이루어진 구조다.
Generator
멜 스펙트로그램을 입력으로 받아 upsample하여 원본 음성과 temporal resolution이 맞는 sequence를 출력한다. transposed convolution과 MRF(multi-receptive field fusion)의 연속으로 이루어져 있고, MRF는 다양한 길이의 패턴을 동시에 보는 역할을 한다.
Discriminator
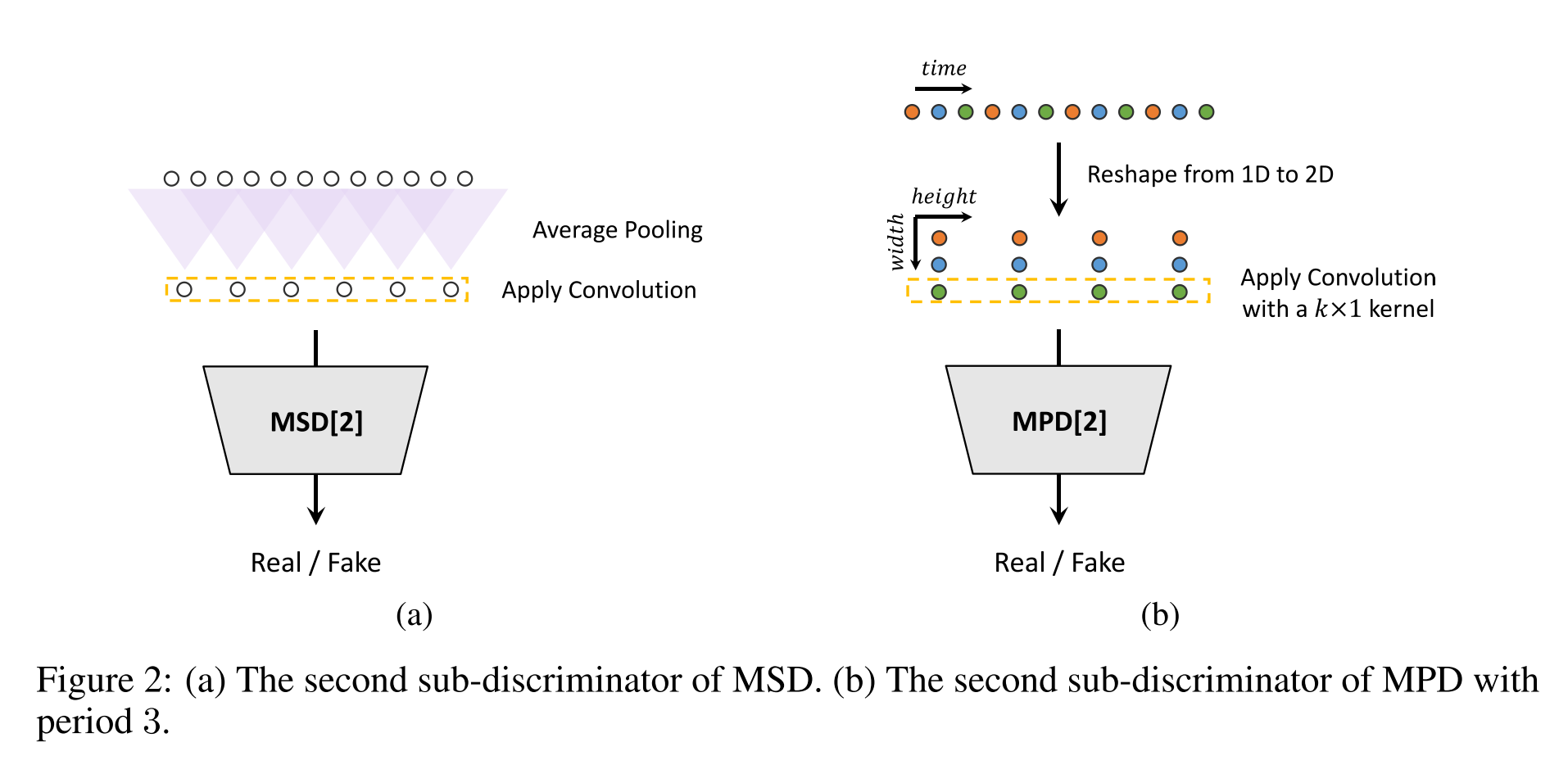
파형의 서로 떨어져 있는 샘플들의 관계를 피쳐로 만드는 MPD(Multi-Period Discriminator)와 인접한 샘플들의 관계를 피쳐로 만드는 MSD(Multi-Scale Discriminator)로 이루어져 있다.
- MPD
- 일정 간격으로 떨어진 샘플들을 2D로 정렬하여 convolution 연산을 수행한다.
- 총 5개의 sub-discriminator로 이루어져 있는데 각각의 패턴이 겹치지 않게 소수(2,3,5,7,11) 중 하나의 period를 가진다.
- MSD
- MelGAN에서 유래한 구조이다.
- raw audio, x2 average-pooled, x4 average-pooled scale에서 연산을 수행한다.
손실 함수
GAN loss
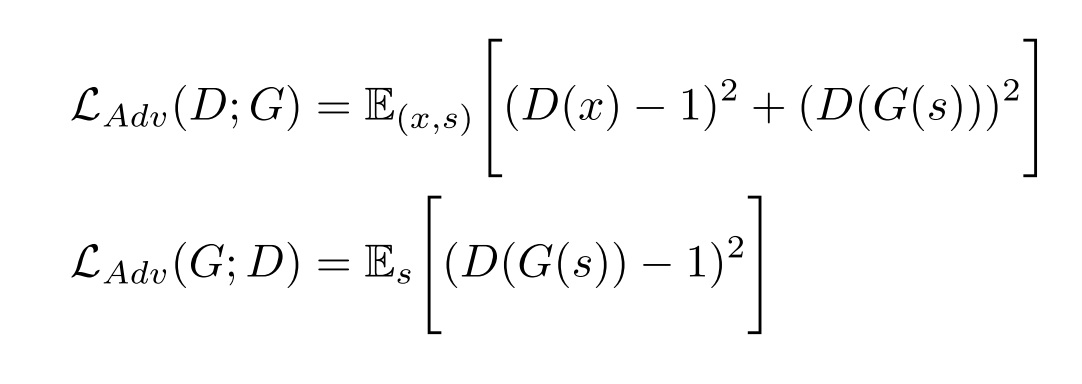
non-vanishing gradient flow를 위해서 binary cross entropy loss를 least squre로 바꾼 LS-GAN의 loss를 따른다.
Mel-Spectrogram loss
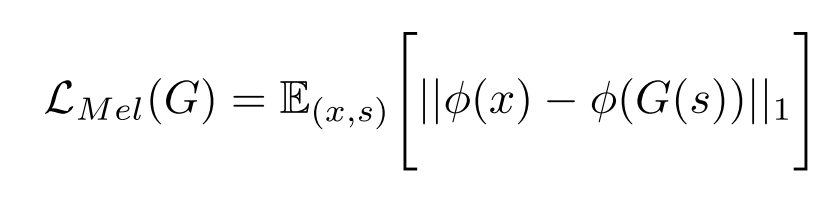
generator가 실제와 유사한 waveform을 만들도록 유도하고 adversarial 훈련 방식을 빠르게 안정화시키기 위하여 mel-spectrogram loss를 적용한다.
Feature Matching loss
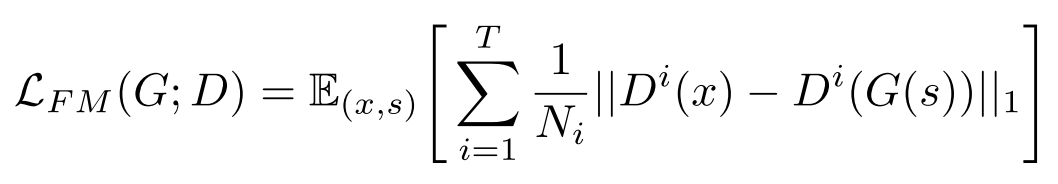
실제 waveform과 generator가 생성한 waveform이 decoder에 입력되었을 때 decoder 각 층에서 추출되는 feature의 차이를 loss로 계산한다.
Final loss
위의 loss들을 합치면 결국 아래처럼 generator와 discriminator의 목적 함수를 정리할 수 있다.
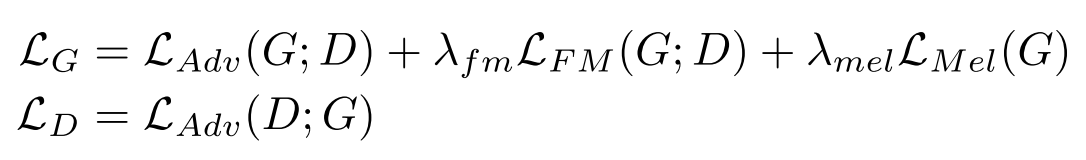
K개의 sub-discriminator들을 고려한 최종 손실 함수는 아래와 같이 표현할 수 있다.
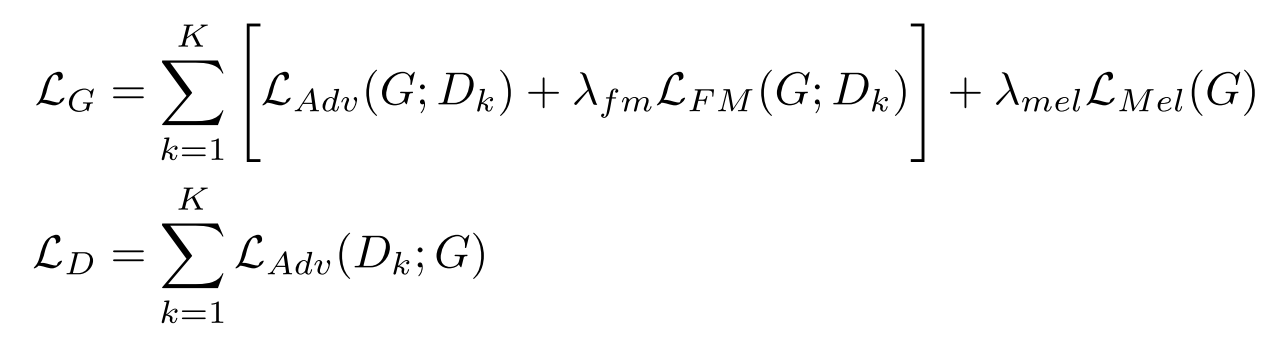
실험 결과
음성 합성 품질과 속도
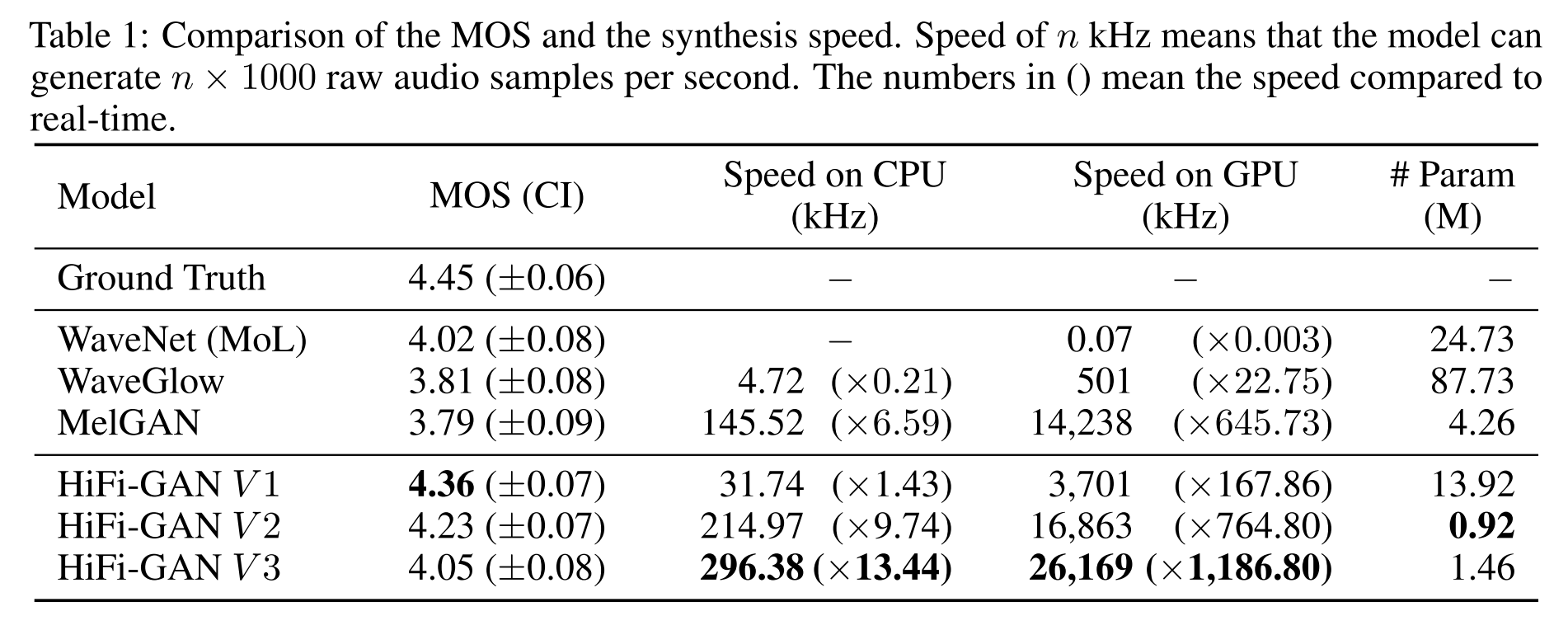
HiFi-GAN을 모델 사이즈를 줄여가며 V1, V2, V3로 나누어서 실험해봤는데 모두 베이스라인보다 높은 성능을 보였고 V3는 CPU에서도 빠른 모델이기 때문에 on-device에 쓰일 수 있다는 장점이 있다.
Ablation Study
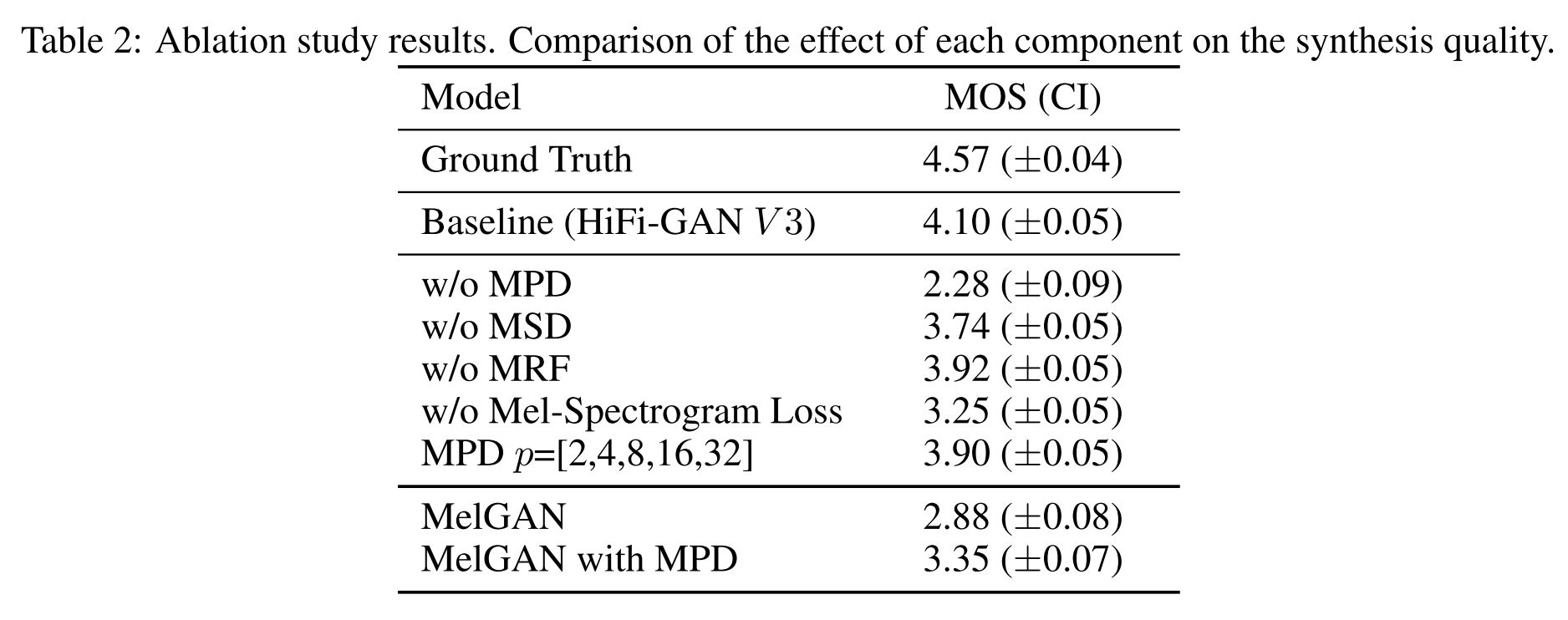
HiFi-GAN V3를 베이스라인으로 ablation study를 진행해봤을 때, 모델의 구성요소를 하나씩 제거하면 성능이 크게 하락함을 관찰할 수 있다.
Generalization to unseen speakers
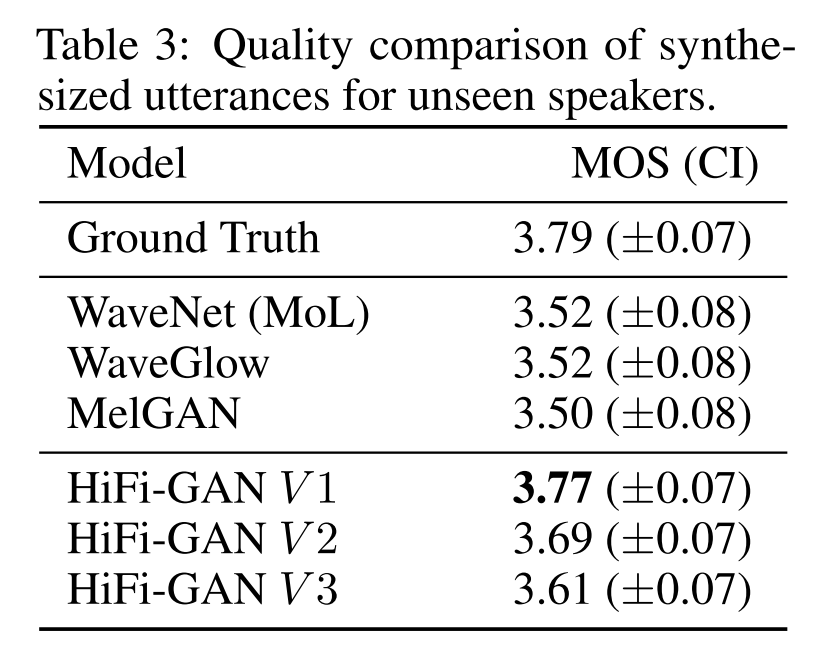
HiFI-GAN은 학습 시 보지 못했던 unseen speaker에 대해서도 일반화 성능이 가장 좋은 것을 알 수 있다.
End-to-End Speech Synthesis
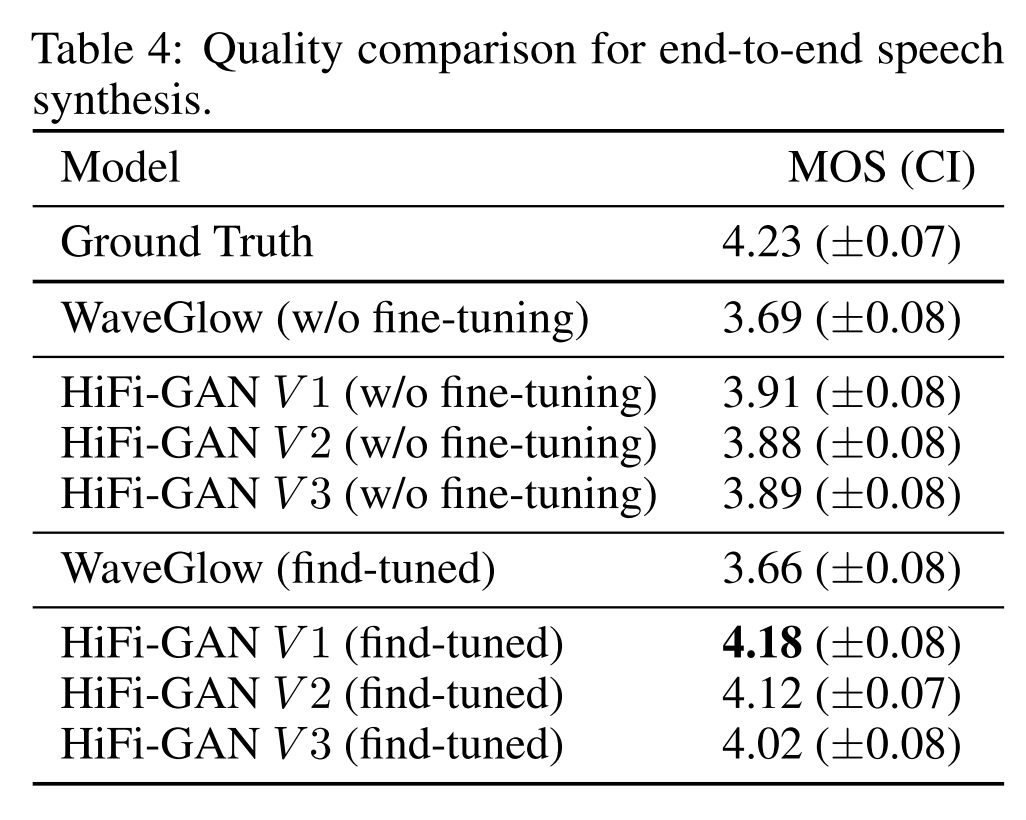
Acoustic model로 Tacotron 2를 사용하고 vocoder로 WaveGlow를 사용한 경우와 HiFi-GAN을 사용한 경우로 나누어 end-to-end 비교실험을 진행했다. WaveGlow는 teacher forcing 모드로 fine-tuning을 해도 음성의 품질이 나아지지 않은 반면, HiFi-GAN은 모든 버전에 대해서 품질이 나아졌다. 따라서 HiFi-GAN은 fine-tuning을 결합한 end-to-end TTS 세팅에서도 잘 적용될 수 있음을 보였다.
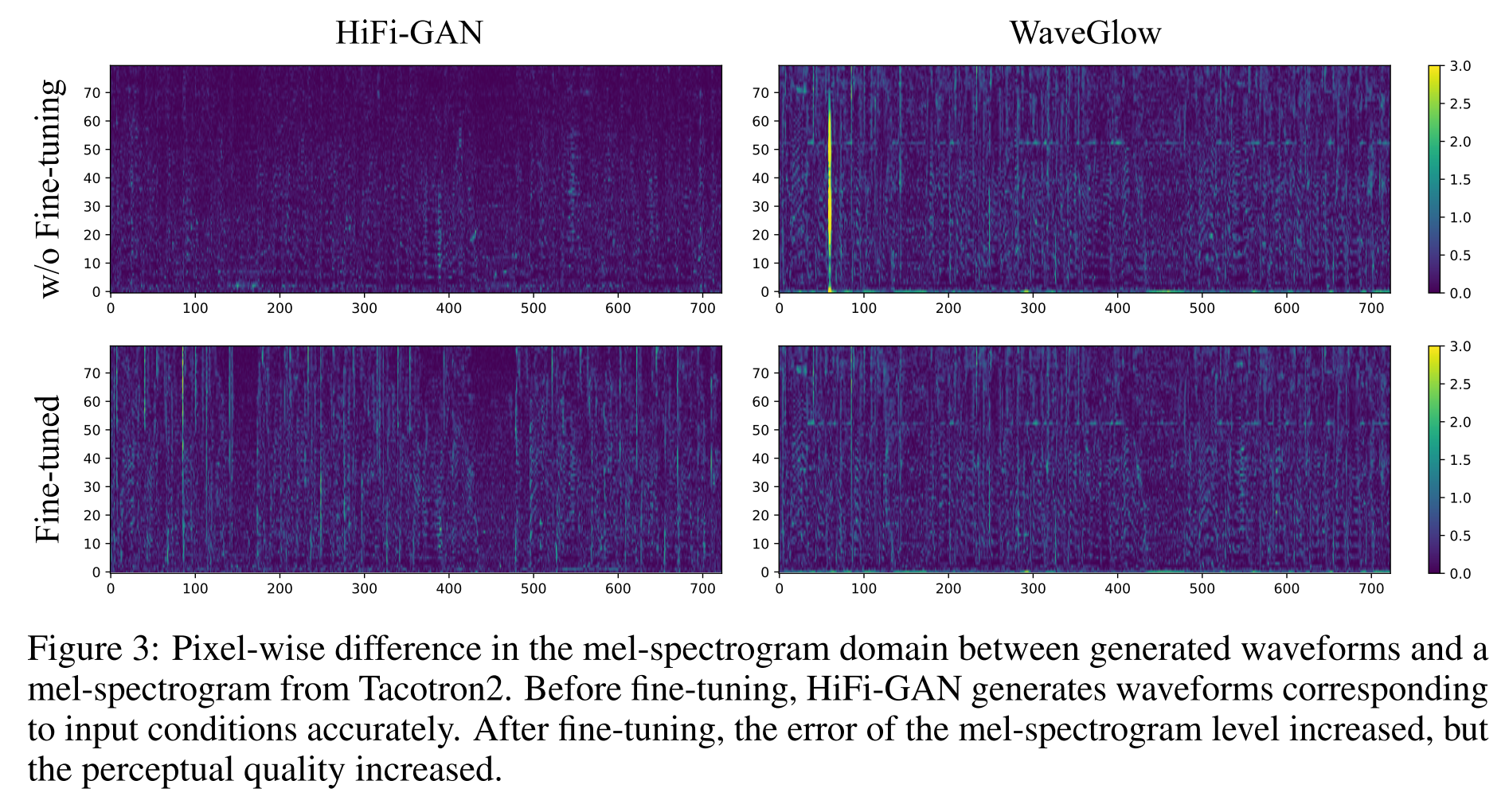
각 보코더를 통해 생성된 파형과 Tacotron 2에서 생성된 멜스펙트로그램의 차이를 픽셀 단위로 관찰해보면 그림 3과 같다. HiFi-GAN은 fine-tuning 전에 큰 차이를 보이지 않지만, fine-tuning 후에는 많은 차이를 보이면서 음성의 품질은 더 나아지는 결과를 보인다. 즉, Tacotron 2의 출력인 멜 스펙트로그램이 이미 noisy한 것이며, fine-tuning을 거친 HiFi-GAN은 이를 잘 제거하여 음성의 품질을 높여준다고 볼 수 있다.
의견
- on-device에서 사용가능한데도 실제 음성처럼 깨끗한 출력을 낼 수 있는 보코더 모델이라 놀랍고 보코더의 끝판왕이 아닌가 하는 생각이 든다.
- Acoustic model과 Vocoder model의 발전을 살펴 보면 결국 sub-structure를 이용하여 sequence의 다양한 scale에 대해 연산하는 것으로 성능을 향상시키는데 시계열 데이터로 모델링을 하려면 어쩔 수 없는 부분인가 싶다.

Leave a comment