
Imaginary Voice (Face-TTS)
Lee, Jiyoung, Joon Son Chung, and Soo-Whan Chung. “Imaginary Voice: Face-Styled Diffusion Model for Text-to-Speech.” ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
들어가며
이번에 소개할 논문은 안면의 특성과 목소리의 상관관계를 학습해 얼굴 이미지와 어울리는 목소리를 생성하는 제로샷 음성합성 연구이다. 인간이라면 자연스럽게 다른 사람의 얼굴을 보고 목소리를 상상할 수 있는 것에 착안하여 수행된 본 연구는 TTS에서 얼굴 이미지를 컨디션 정보로 활용하는 첫 번째 시도이다. 제안하는 Face-TTS 모델에서 안면 특성이라는 생체인식 정보가 이미지 한 장에서 바로 뽑히기 때문에 학습 시 듣거나 보지 못했던(unheard and unseen) 화자에 대해서 별도의 미세 조정(fine tuning)을 진행하지 않아도 된다는 장점이 있다. 안면 특성을 활용하기 위하여 어떤 모델링 기법을 사용하였는지 한 번 파헤쳐보자.
핵심 요약
- Grad-TTS와 cross-modal biometric model을 함께 학습시키는 방법을 제안한다.
- 생성된 음성과 실제 음성 간 차이를 줄이기 위해 speaker feature binding loss를 제안한다.
- 실제 인물 뿐만 아니라 가상 인물의 이미지로도 꽤 그럴싸한 음성이 생성된다.
모델 구조
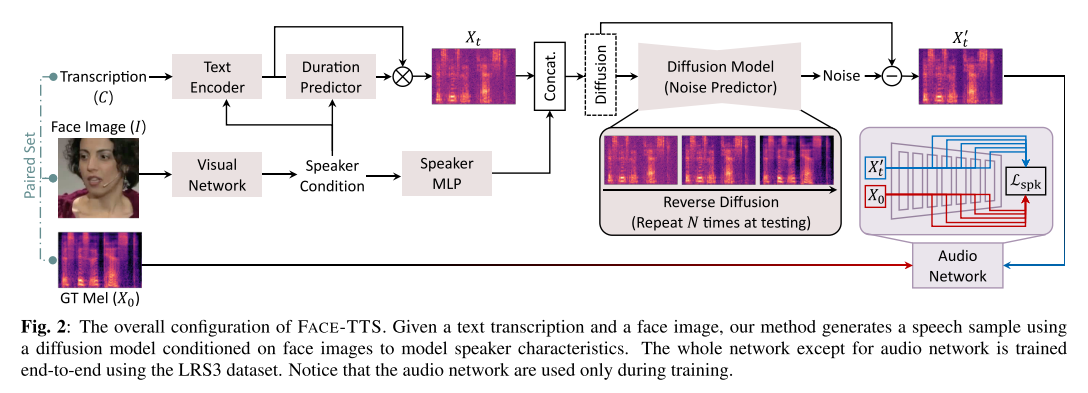
Grad-TTS에 화자의 음성에서 화자의 특징을 뽑아내는 audio network, 그리고 얼굴 이미지에서 화자 정보를 뽑아내도록 유도되는 visual network를 추가한 구조이다. audio network와 visual network는 5,994명의 화자로 이루어진 VoxCeleb2 데이터셋을 이용해 사전 학습되었고, 추후 2,007명의 화자로 이루어진 LRS3 데이터셋을 이용해 전체 네트워크의 일부로써 미세 조정된다. Vocoder로는 사전 학습된 HiFi-GAN을 사용하였다.
목적 함수
Speaker Feature Binding Loss
다화자 음성합성 모델에서 화자의 다양한 특징들을 학습시키기 위해서는 일반적으로 충분한 길이의 음성이 녹음되어야 하는데, 이 문제를 완화하기 위해 speaker feature binding loss를 제안한다. 저자들은 이 loss를 사용해서 비교적 짧은 음성들을 가지고도 얼굴-음성 간 관계를 잘 학습할 수 있었다고 한다. 대중적으로 쓰이는 LibriTTS가 화자별 음성 평균 길이 550s의 음성을 가지고 있는 반면에 LRS3는 짧은 화자별 평균 길이 34s를 가진다.
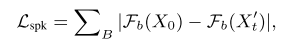
구체적으로 타겟 화자의 음성과 생성된 음성을 audio network에 통과시켜 뽑은 컨볼루션 레이어 별 피쳐들의 차이를 합산한 L1 loss (HiFi-GAN에서 사용하는 feature matching loss와 유사)이다. 첫 번째와 두 번째 레이어는 제외했고, 해당 loss로 audio network가 업데이트되지 않게 freeze하였다. 이 loss는 생성된 음성과 실제 음성에서 추출된 화자 관련 임베딩의 분포가 비슷하게 만들어지도록 유도하는 역할을 한다.
최종 목적 함수

Grad-TTS에서 쓰이던 loss들과 speaker feature binding loss를 가중 합한 형태를 띈다.
실험 결과
오디오 품질 평가
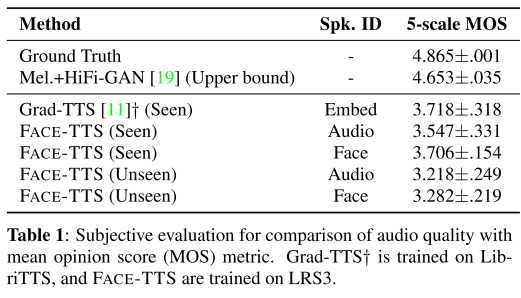
Face-TTS가 seen과 unseen 화자 모두에 대해서 양호한(MOS 3이상) 합성 결과를 보여준다. 그리고 얼굴 이미지를 컨디션으로 줬을 때 음성을 사용했을 때보다 높은 MOS가 기록됐는데 저자들은 음성 정보가 녹음 환경에 따라 달라질 수 있는 반면에 얼굴 이미지는 강건한 표현력을 가지기 때문이라고 해석한다.
화자 인식 평가

화자의 이미지와 생성된 음성을 가지고 AB, ABX 테스트를 진행했을 때 60%에 근접한 정답률이 기록됐다. 즉, 생성된 음성이 화자의 안면 특성을 잘 반영해냈다고 풀이된다.

LRS3 데이터셋으로 학습한 Grad-TTS와 비교했을 때 speaker identification matching accuracy가 월등히 높게 나왔다. Grad-TTS는 seen 화자로 평가하고, Face-TTS는 unseen 화자로 평가했음에도 불구하고 accuracy가 높은 것으로 보아 Face-TTS가 안면 특성에서 유의미한 화자의 목소리 정보를 추출한다고 해석할 수 있다.
가상 음성 생성 평가

Stable Diffusion 모델로 생성한 가상 인물의 이미지를 가지고도 어울리는 음성을 생성할 수 있는지 실험하였다. 실제 얼굴 이미지를 사용한 경우에 비해서는 성능이 떨어지지만 평균적으로 좋다는 평(3=Good)을 받았기 때문에 가상 인물의 목소리를 만드는 용도로도 충분히 활용 가능하다.
의견
- 사전학습된 cross-modal biometric 모델이 아무리 적은 학습률이라 할지라도 새로운 데이터셋에 의해 미세 조정되면서 visual feature와 audio feature 간 괴리가 커질 것 같은데 이를 막기 위한 loss가 함께 추가되어야 하지 않은지 의구심이 든다.
- 본문과 그림3 캡션에 적힌 AB, ABX test 세팅 설명들 간에 불일치가 있어서 약간의 혼란이 있었다.
- Grad-TTS가 LRS3으로 학습을 진행해도 꽤 괜찮은 인식 성능을 보여준다고 적혀있는데 표1에는 수치로 적혀있지 않아서 Face-TTS와 직접적인 비교가 용이하지 않은 것이 아쉽다. 그래도 더 큰 데이터셋으로 학습한 Grad-TTS가 재현해낼 수 있는 음성의 품질(MOS 3.718)에 Face-TTS가 근접하는 수치(MOS 3.706)를 보여주는 것은 괄목할만한 성과라고 생각한다.




Leave a comment