
Haoyi Zhou et al., Informer: Beyond Efficient Transformer for Long Sequence Time-Series, 2020
들어가며
실세계에서 시계열 예측은 전력 수요 예측과 같이 장기간의 미래를 예측하는 문제 상황에 자주 직면하게 된다. 긴 시퀀스 예측은 모델의 높은 capacity를 요구하기 때문에 최근에 트랜스포머 모델이 시계열 예측에 많이 적용되기 시작했으며 높은 정확도를 보여주고 있다. 그러나 트랜스포머 모델에도 여러 한계점이 존재하는데 예측해야 하는 시계열의 길이 증가에 따른 시간 복잡도와 메모리 사용량 증가가 바로 그것이고, 인코더-디코더 구조 상의 한계점도 존재한다. Informer는 위의 문제들을 해결하기 위해 새로운 어텐션 메커니즘과 변형된 디코더 구조를 적용했다고 하는데 구체적으로 살펴보도록 하자.
핵심 요약
- Long Sequence Time-Series Forecasting(LSTF) 문제에서 예측 성능을 향상시켰고, 트랜스포머류의 모델들이 긴 시퀀스의 입력과 출력의 의존도를 잘 잡아내는 것을 입증했다.
- ProbSparse self-attention 메커니즘을 제시해서 time complexity와 memory usage를 모두 $O(LlogL)$ 수준으로 감소시켰다.
- Self-attention Distilling 과정을 통해 지배적인 어텐션 스코어들을 걸러냈고 이를 통해 total space complexity를 $O((2-\epsilon)LlogL)$ 수준으로 줄였다.
- Generative Style Decoder를 적용해서 inference 시에 한번의 forward step으로 오차의 누적 없이 긴 시퀀스의 시계열을 예측하도록 하였다.
문제 정의
단기간의 시계열 예측은 가까운 미래만을 보여주지만, 장기간의 시계열 예측은 더 나은 정책을 수립하고 안전한 투자를 하도록 도와줄 수 있다. 예를 들어, 변전소의 시간별 온도를 예측하는 문제에서 12 points(0.5 days)를 다루는 것이 short-term period 예측이라면 LSTF 문제에서는 480 points(20 days)를 다룬다.
어텐션 메커니즘

ProbSparse가 time complexity와 memory usage를 줄일 수 있는 비결은 위와 같이 지배적인 Top-u개의 query들을 추출하고 이들만을 어텐션 계산에 사용하기 떄문이다. Top-u개를 추출하기 위해서는 query의 sparsity를 측정할 측도가 필요한데 위와 같이 KL divergence 기반의 근사식을 사용하였다.
모델 구조
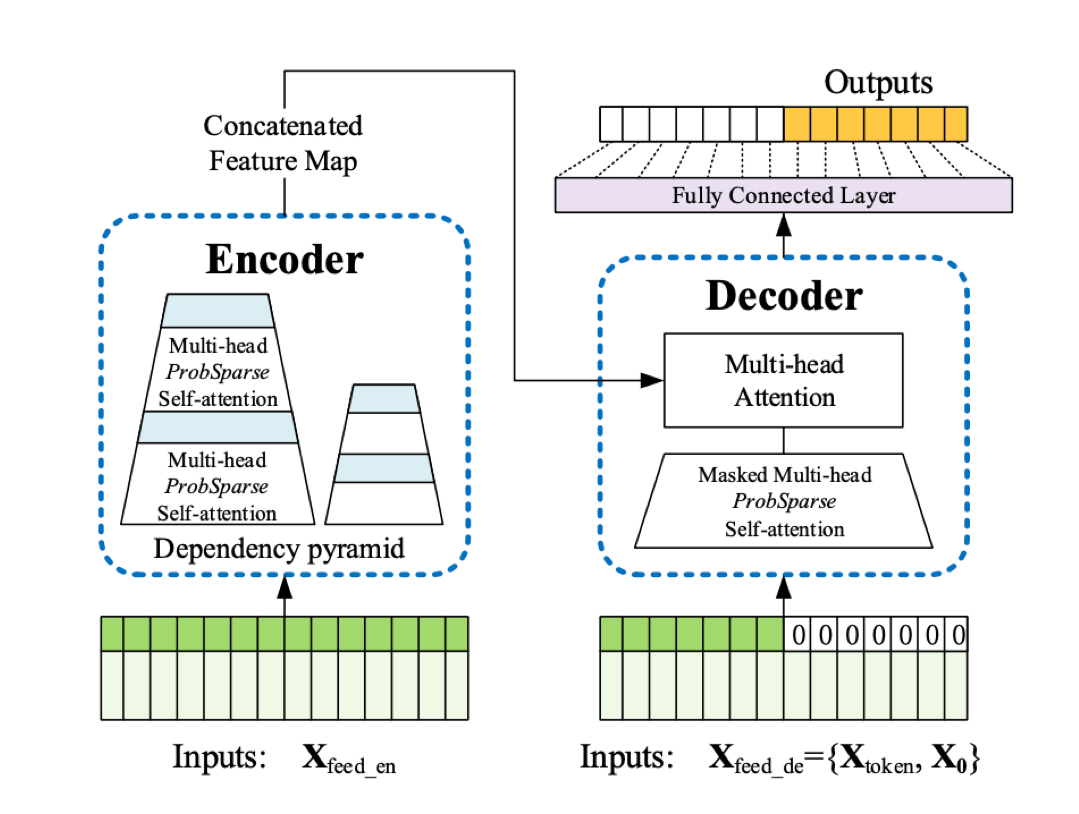
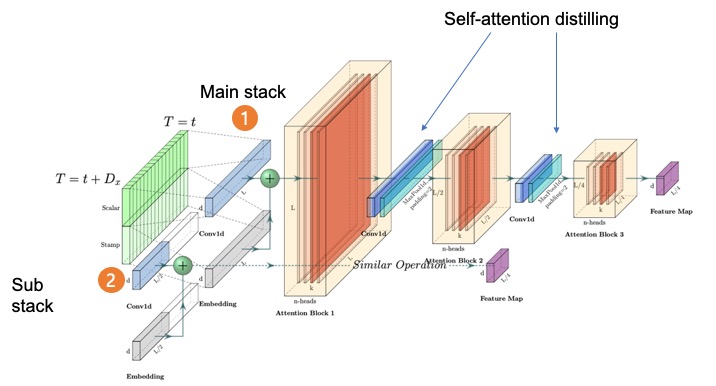
기본적으로 인코더-디코더 구조를 따르는 트랜스포머 모델이다. 눈여겨 볼 점은 self-attention에 ProbSparse attention이 적용되었고 인코더에 사다리꼴 형태로 표현된 self-attention distilling이 적용되어 지배적인 어텐션 값들을 추출하며 동시에 네트워크의 사이즈를 크게 줄였다는 것이다. 그리고 복제한 layer stacking을 통해 모델의 강건함도 함께 가져가고 있다.
오른쪽의 디코더에서는 마찬가지로 ProbSparse attention이 적용되었고 generative style로 시계열을 예측하고 있는 것을 볼 수 있다. Generative inference에 쓰이는 start token은 NLP에서처럼 정해주는 것이 아니고, input sequence에서 샘플링을 하여 입력으로 넣어준다.
예측 성능
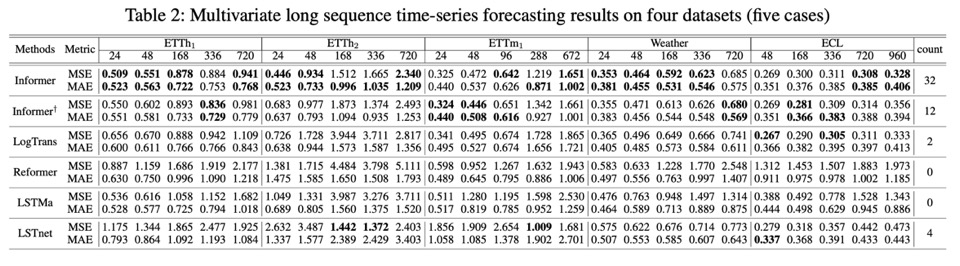
Informer가 짧은 시계열 예측뿐만 아니라 긴 시계열 예측까지 베이스라인 모델들보다 우수한 성능을 보이는 것을 알 수 있다. 그리고 ProbSparse attention Informer(첫번째 줄)와 Canonical attention Informer(두번째 줄)를 비교해봤을 때 best score를 낸 횟수가 전자가 더 많으므로 ProbSparse attention이 예측 성능을 높이는 데 기여하고 있음을 확인할 수 있다.
결론
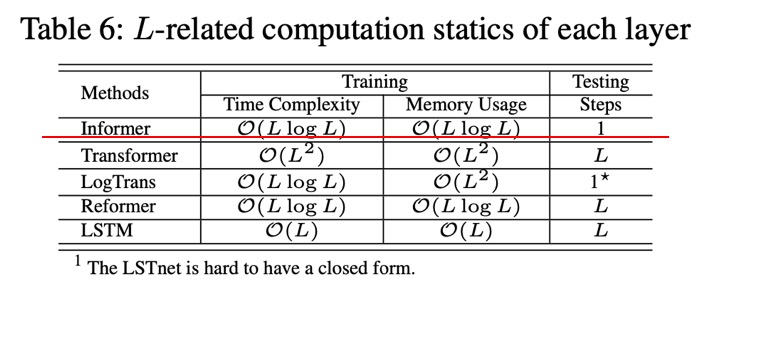
ProbSparse attention과 self-attention distilling을 통해 기존 Transformer의 연산량이 기하급수적으로 증가하는 단점을 극복했으며, generative decoder로 전통적인 encoder-decoder 구조의 오차가 누적되는 단점을 극복하였다. 그러나 input sequence가 짧을 때는 일반적인 self-attention의 성능이 더 높은 것으로 보아 Informer는 긴 sequence에 특화되어 있다는 생각이 들었고, 본 논문에서 활용한 데이터셋들은 모두 주기성이 강한 특징이 있어서 금융 데이터와 같이 non-stationary한 시계열 데이터에 적용해보기에는 무리가 있을 것 같다.




Leave a comment