
LDNet
Huang, Wen-Chin, et al. “LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech.” arXiv preprint arXiv:2110.09103 (2021).
들어가며
음성 합성 결과의 MOS를 예측하는 가장 직관적인 방법은 청취평가 데이터셋을 활용해 모델을 훈련시키는 것이다. 그런데 그동안 이루어진 연구들은 훈련 데이터셋에서 mean score만을 타겟으로 삼아서 모델을 학습시켰다. 이럴 경우 데이터 부족(샘플 별 레이팅 수가 많지 않음)에 의한 문제가 발생하기 때문에 평가자들의 레이팅 정보를 모두 활용하여 mean score를 구하는 것이 바람직하다.
본 논문에서는 Listener Dependent(LD) score를 구하여 이로부터 mean score를 계산하는 LDNet을 제안하고, 모델 구조와 inference 방식에 변화를 주면서 비교 실험하여 최적의 세팅을 알아낸다.
핵심 요약
- MBNet의 맹점을 짚어서 모델 구조를 개선하고 이로부터 성능 향상을 이루어냈다.
- 파라미터 수가 적어서 light-weight한 모델이고 제안하는 기법들이 모두 새로운 기법들과 결합될 수 있는 유연한 특징을 가지고 있다.
- 가상의 mean listener를 활용해 mean score를 구하는 것이 음성 합성 모델의 mean score를 예측하는 데 큰 기여를 하였다.
모델 구조
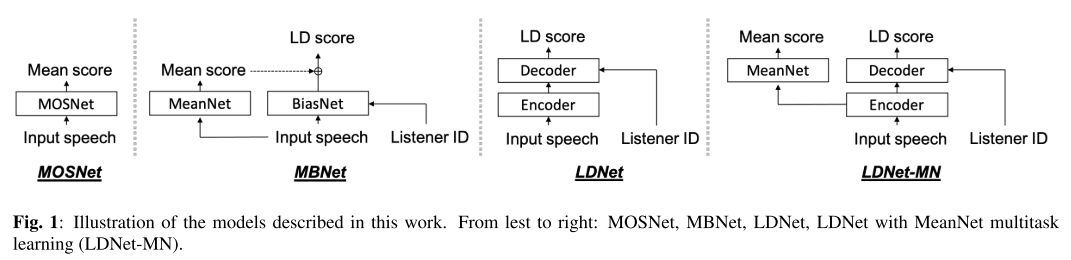
기존의 MOSNet은 speech로부터 바로 mean score를 예측하는 구조, MBNet은 MeanNet과 BiasNet이 각각 mean score와 LD score를 예측하는 구조였다. 그런데 MBNet은 inference할 때, mean score를 예측하기 위해서 BiasNet은 버리고 MeanNet만 사용하게 되므로 결국 MOSNet과 같이 동작하게 되고 이를 본 논문에서는 ‘MeanNet inference’라고 통칭한다. 어쨌든 MBNet에서 BiasNet은 regularization의 역할만 하게 되므로 BiasNet의 연산은 비효율적으로 크게 이루어지고 있음을 지적할 수 있다.
또 MBNet이 갖는 단점으로는 MeanNet과 BiasNet이 서로 다른 정보를 인코딩하도록 유도되었지만, 어느 정도는 공통된 정보를 품고 있어야 한다는 것이다. 왜냐하면 음성의 품질을 평가할 때 평가자들 사이에서도 공유되는 어떤 공통적인 기준은 있을 것이기 때문이다.
그러므로 LDNet은 그림 1과 같이 인코더-디코더 구조를 통해 MeanNet, BiasNet으로 나눠졌던 구조를 다시 합쳤고 인코더는 speech 정보를, 디코더는 Listener ID를 직접 받게 함으로써 인코더에서는 listener-independent 정보를 추출하게 하고 디코더에서는 listener-dependent 정보를 추출하게끔 유도하였다. 여기서 저자들은 만약 listener dependent 정보(preference)가 mean score의 shift(MBNet에서 bias라고 언급했던) 를 더해주는 정도의 역할만 하는 것이라면, 인코더의 표현 능력이 강력하다는 가정하에 디코더는 단순하게 설계해도 괜찮을 것이라고 주장한다. LDNet에서 mean score를 구하기 위해서는 모든 청취자들의 LD score 평균을 통해 구하는 방식인 all listener inference를 사용한다.
LDNet-MN은 LDNet에 MeanNet을 붙인 형태인데 mean score를 구하는 방식을 비교하고자 설계되었다. 즉, 이때는 all listener inference를 사용하지 않고 MeanNet inference를 수행하는데 학습시 MeanNet에 입력으로 들어가는 피쳐가 speech가 아닌 인코더의 출력이라는 점이 MBNet과 차별화되어 있다. 그리고 MBNet에서 mean loss는 MeanNet에만 영향을 주지만, LDNet-MN에서 mean loss에 대한 gradient는 인코더까지 흐르기 때문에 인코더는 좀 더 완벽한 listener-independent 정보를 학습할 수 있게 된다.
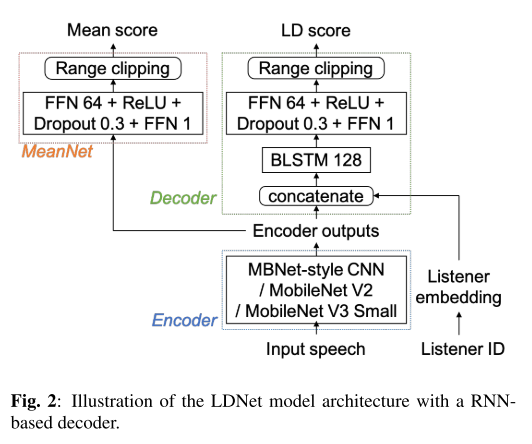
인코더는 3개의 후보(MBNet에서 참고한 CNN layer, MobileNet V2, MobileNet V3 Small layer)에 대해서 모두 시도해보았고, 디코더와 MeanNet에는 feed-forward network(FFN)과 BLSTM 기반의 RNN을 사용해보았다고 한다.
LDNet-ML은 새로운 구조는 아니지만 mean score를 구할 때, mean listener를 활용하여 구한다. 모델 학습 시 트레이닝 셋에서 샘플별 평균 점수에 맵핑되는 가상의 인물 mean listener를 만들고 추후 inference에서 mean score는 mean listener의 ID를 입력하여 그 결과로 나온 LD score를 mean score로 간주하는 inference 방식이다.
실험 결과
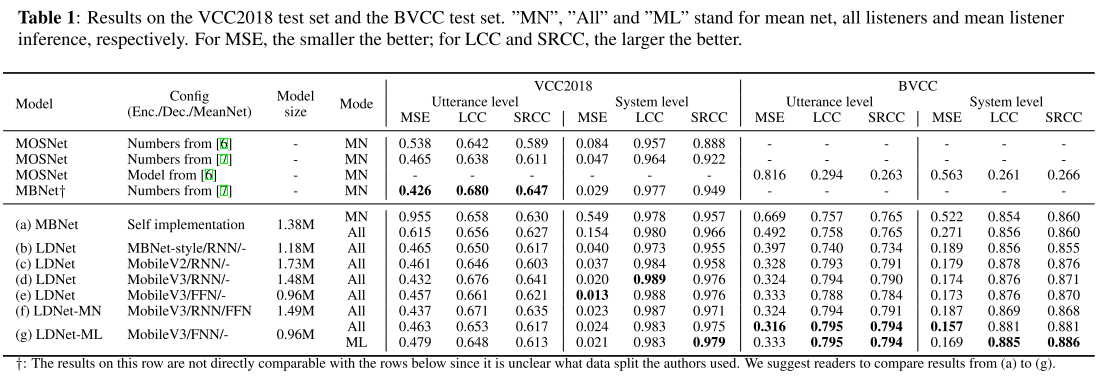
all listener inference의 장점
표1의 (a)를 보면 mean net inference와 all listener inference의 세팅을 바꿨을 때 성능 차이를 관찰할 수 있다. MSE는 utterance, system level 모두에 대해서 all listener inference를 사용했을 때 크게 감소하는 것을 볼 수 있고, LCC나 SRCC는 약간의 향상이 있는 것을 볼 수 있다. 즉, all listener inference를 사용하면 예측의 분산을 줄일 수 있고, 여러 음성 합성 모델들간의 우위 관계 등을 더 잘 포착할 수 있다는 뜻이다.
인코더 디자인의 영향
표1의 (b)-(d)에서 인코더를 바꿈에 따라 나타나는 효과를 볼 수 있는데 Mobile V3를 사용할 때 모델 파라미터가 가장 적은데도 불구하고 가장 좋거나 다른 인코더와 비슷한 성능이 나오므로 인코더 구조는 Mobile V3로 고정하고 다음 실험들을 진행한다.
디코더 디자인의 영향
RNN을 사용하던 디코더를 단순하게 FFN으로 바꿔보았을 때, 비슷한 성능을 내면서 모델 사이즈는 64% 감소, 학습 속도는 25% 향상의 효과가 나타났다. 이는 앞에서 저자들이 말했던 ‘인코더가 충분히 강력하다면 디코더는 단순하게 설계해도 괜찮을 것이다‘라는 가설에 대한 증명이라고 볼 수 있다.
LDNet-MN의 유효성 검증
(f)는 (d)에서 FFN의 mean net을 더한 구조로 실험한 결과다. mean score을 예측하는 네트워크가 추가됨으로써 성능 향상이 기대되었지만, 실제로는 성능이 약간 하락했고 mean net의 구조를 RNN 기반으로 변경해도 같은 결과가 나타났다.
LDNet-ML의 유효성 검증
mean listener를 활용해 mean score inference를 하는 LDNet-ML의 유효성도 평가해 보았다.
먼저 (e)와 (g)에서 all listener inference를 사용했을 때, VCC2018에서는 약간의 성능 감소가 관찰되지만 BVCC에서는 성능이 크게 향상된다. 그리고 이제 mean listener inference로 mode를 바꿔주게 되면, system level SRCC가 두 데이터셋에 대해서 더 향상된다. 음성 합성 모델들간의 우위를 매기기 위해서는 system level SRCC가 가장 중요하기 때문에 LDNet-ML이 LDNet-MN보다 mean score를 훨씬 유용하게 활용하는 방식이라고 판단된다.
의견
- 모델 구조를 최대한 단순하게 만들려는 시도와 listener-dependent 피쳐와 listener-independent 피쳐를 모델이 구분하여 배우도록 디자인한 아이디어가 논리적이고 참신하다.
- 표 1에서 (e)와 (g)의 All 세팅 사이 차이점이 불분명하게 서술되었다고 생각하는데 아마도 (g)에서 all listener inference를 진행할 때는 트레이닝 셋에 추가해준 mean listener의 LD score까지 예측하여 다 더한 후, mean score를 계산한 것 같다.
- 샘플 별 레이팅이 많을수록(mean score가 신뢰성을 가질수록) 추가적인 성능 향상이 기대되는 모델이라 앞으로 self-supervised learning이나 data augmentation 기법이 함께 접목된다면 큰 시너지가 날 수 있겠다.




Leave a comment