
LSTM G2P
Rao, Kanishka, et al. “Grapheme-to-phoneme conversion using long short-term memory recurrent neural networks.” 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015.
들어가며
G2P 모델은 음성인식과 음성합성 시스템을 만들기 위해서 꼭 선행되어야 할 필수 요소다. 그동안 전통적인 joint-sequence 기반의 모델은 grapheme과 phoneme의 관계를 명시적으로 정해주는 정렬이 데이터로 주어져야 학습이 가능하다는 단점이 있었다. 본 논문에서는 이러한 단점을 극복할 수 있는 LSTM 모델을 제시한다.
핵심 요약
- LSTM은 grapheme의 전체적인 맥락을 고려하는 특성이 있어서 joint-sequence 기반 모델보다 유연성이 있다.
- Unidirectional LSTM보다 Bidirectional LSTM의 성능이 더 좋았다.
- Bidirectional LSTM과 n-gram 모델을 함께 결합한 경우의 성능은 SOTA를 기록했다.
모델 구조
Unidirectional model
unidirectional LSTM은 과거의 입력만을 활용해서 다음 스텝의 값을 예측하기 때문에 output delay라는 개념을 도입한다. 즉, G2P 모델의 출력인 phoneme의 sequence를 grapheme의 sequence 길이와 같도록 유지시키면서 grapheme에 해당하는 phoneme이 지정된 delay 수만큼 늦게 출력되도록 모델링을 하는 것이다. 이렇게 하면 LSTM이 입력을 받자마자 출력하는 것이 아니라 다음 여러 스텝의 입력까지 보고 출력을 결정할 수 있어서 문맥을 고려하게 만들어줄 수 있다.
아래는 여러가지 delay의 예시이다.
- zero-delay
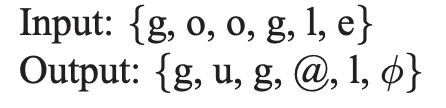
- fixed-delay (2)
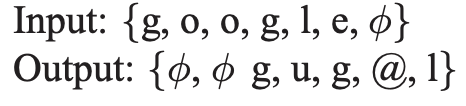
- full-delay
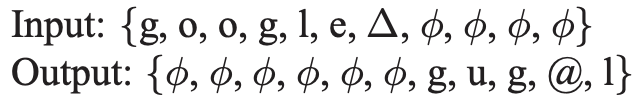
Bidirectional model
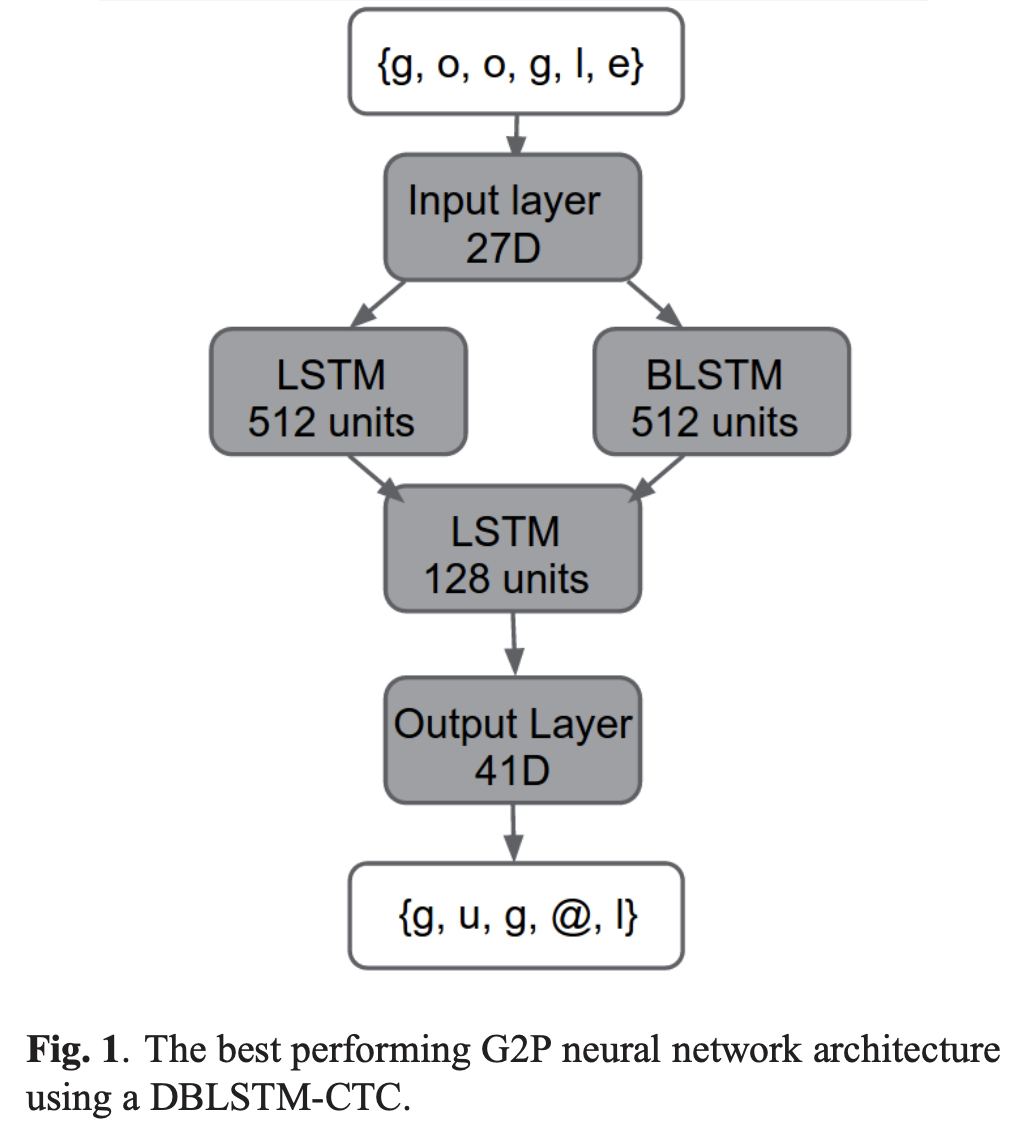
히든 레이어를 여러개 가진 DBLSTM에 connectionist temporal classification(CTC)을 출력층으로 가진 모델이다. CTC는 40개 phoneme에 1개의 blank를 더하여 총 41개의 label을 예측해야 하므로 41 unit을 가진 softmax layer로 이루어져 있다.
그리고 DBLSTM-CTC에 joint n-gram 모델을 결합시켜보기도 한다. LSTM은 word level의 변환을 수행하고, n-gram은 grapheme level에서 변환을 수행한다는 차이점이 있지만 두 모델을 결합시켰을 때 시너지가 날 수 있는지 확인하기 위함이다.
실험 결과
US 영어 기준으로 소문자와 apostrophe를 포함한 27개의 grapheme과 XSampa phoneset에 기반한 40개의 phoneme을 사용한다.
아래의 실험 결과들은 모두 CMU pronunciation dictiionary를 이용한 G2P 성능들을 나타낸다.
Output delay 효과
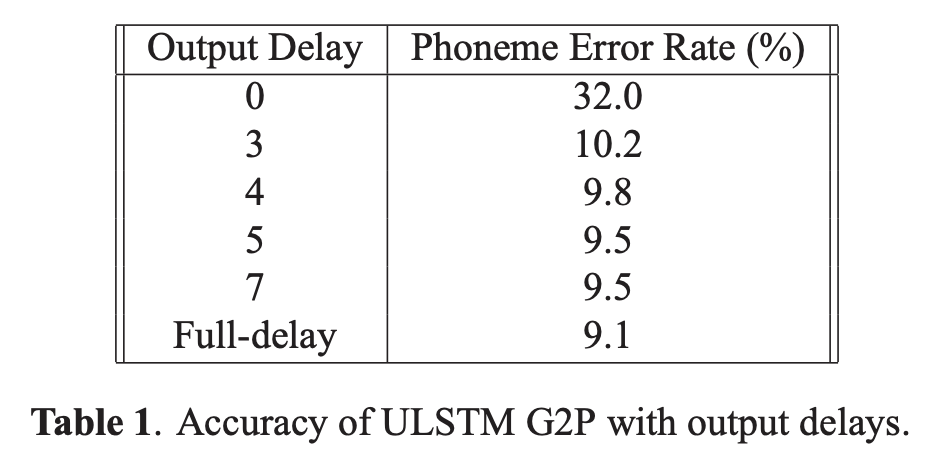
먼저 ULSTM에서 사용했던 output delay의 효과를 살펴보자. 표 1에서 나타나는 것과 같이 delay의 수가 커질수록 error rate가 줄어드는 효과가 있다. 즉, G2P를 수행하는 데 있어서 미래의 문맥까지 고려하는 것이 중요함을 알 수 있다.
베이스라인 비교
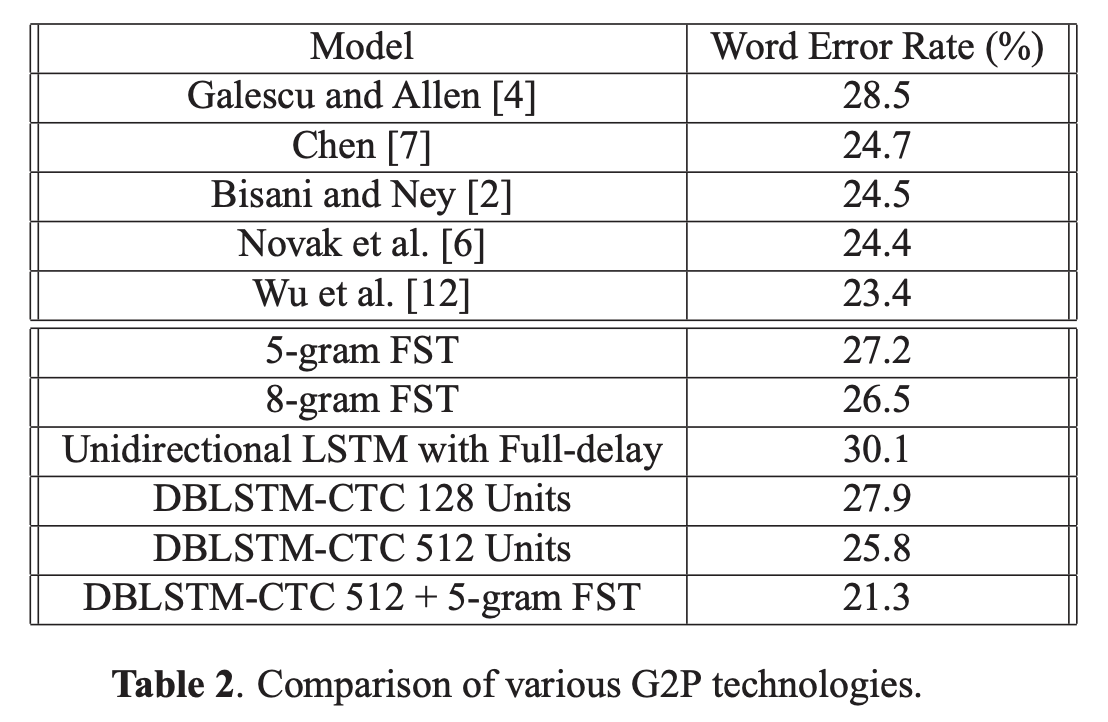
베이스라인 모델들과 비교했을 때 unidirectional model은 WER이 높은 수준이지만 DBLSTM-CTC는 n-gram model과 유사한 수준을 보이기도 하며, DBLSTM-CTC와 n-gram을 결합한 경우에는 가장 좋은 성능을 보여준다.
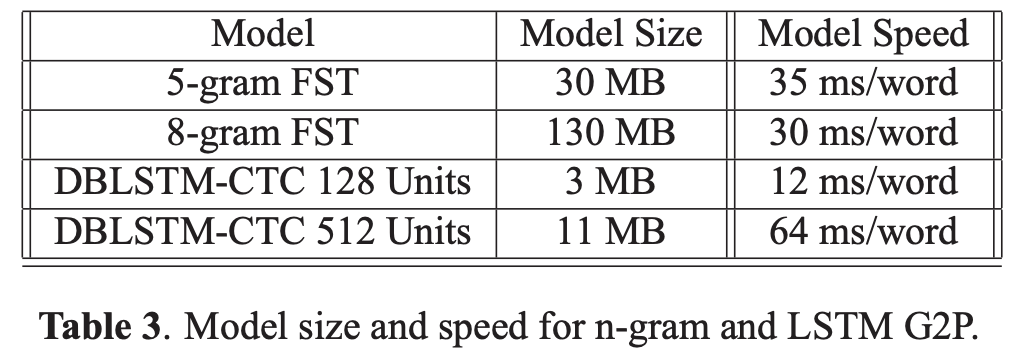
모델의 크기와 속도를 함께 고려한다면 본 논문에서 제시하는 DBLSTM-CTC 128 unit은 5-gram 모델 크기의 1/10 수준이고 속도도 3배정도 빠른데 성능이 거의 동일하므로 실용적으로 큰 메리트가 있음을 알 수 있다.
의견
- G2P도 기계번역처럼 문맥에 맞는 발음을 만들어내는 것이 중요하기 때문에 이러한 sequence 처리에 특화된 LSTM을 두 경우로 나누어서 체계적으로 접목시켜 본 것이 좋았다.




Leave a comment