
MBNet
Leng, Yichong, et al. “MBNET: MOS Prediction for Synthesized Speech with Mean-Bias Network.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
들어가며
음성 합성 결과를 평가할 때 주관적인 평가 방식으로 Mean Opinion Score(MOS)를 사용하는 것이 일반적인 관행으로 여겨지고 있다. MOS는 여러 명의 청취자들을 섭외하고 그들에게 주어진 음성에 1~5점 사이의 점수를 부여하도록 한 후, 평균 점수를 음성의 품질로 간주하는 방식인데 사람을 모으고 평가 결과를 모으는 과정에 많은 시간과 노력이 투입된다. 이런 문제를 인지하고 MOS를 예측할 수 있는 모델을 만들려는 시도들이 있었는데 이 과정에서 문장 단위(utterance level)의 평균 점수만 타겟으로 생각하고 개인의 평가 점수는 훈련 데이터로 쓰이지 않았다. 그런데 문장 단위의 MOS는 개인들의 선호에 의해 편향되는 경우가 많다. 왜냐하면 사람마다 품질에 대한 평가 기준이 다르고 한 음성에 대해 평가를 하는 사람은 전체 집단 내에서 랜덤으로 정해지기 때문이다.
그래서 본 논문에서는 그동안 버려지던 개인의 평가 점수를 최대한으로 활용한 debiasing process를 네트워크에 추가하여 MBNet을 설계하고 MOS를 예측하며, 다양한 실험 결과로 유의미한 학습이 이뤄졌음을 증명한다.
핵심 요약
- 한 음성의 mean MOS를 맞출 수 있는 MeanNet과 개인의 bias를 예측할 수 있는 BiasNet으로 모델을 구성했다.
- BiasNet은 데이터셋 내 개인들의 평가 점수를 최대한 활용할 뿐만 아니라 각 평가에서 개인의 선호를 잡아내는 역할을 한다.
- 베이스라인과 비슷한 양의 파라미터를 가진 모델로 MOS를 더 정확하게 예측할 수 있다.
모델 구조
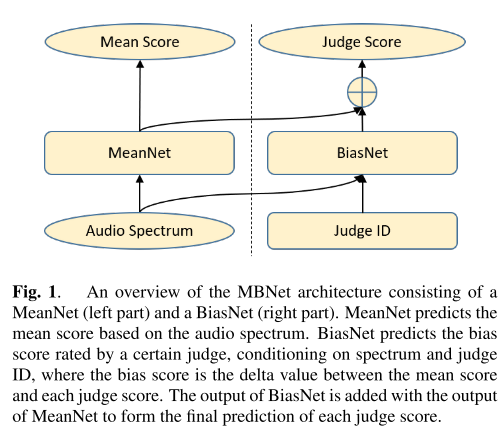
모델 구조는 꽤 단순하다. mean score를 예측하는 MeanNet과 judge score와 mean score의 차이를 예측하는 BiasNet이 모델의 핵심이다. 이때 MeanNet은 linear spectrogram을 입력으로 받아서 mean score를 출력하도록 구성되어 있고, BiasNet은 spectrogram과 judge ID를 입력으로 받은 뒤 만들어 낸 feature와 MeanNet의 feature를 합쳐서 최종 judge score를 예측하도록 훈련된다.
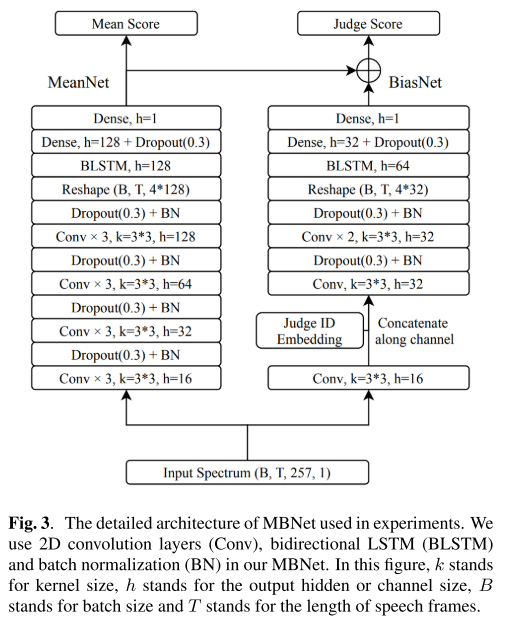
더 구체적으로 살펴보면 그림 3과 같이 생겼는데, convolution layer와 bidirectional LSTM, batch normalization의 조합으로 이루어진 형태라는 것을 알 수 있다.
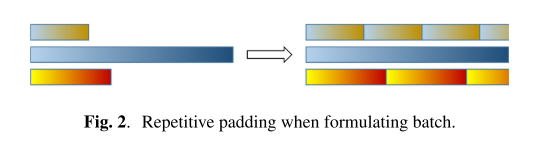
batch normalization을 진행할 때는 mean, variance 계산을 안정적으로 유지하기 위해서(batch축 방향으로 feature들의 mean, variance를 구하는 계산이 이루어지므로) 각 오디오의 길이를 zero padding이 아니라 repetitive padding으로 맞춰주었다(repetitive padding을 한다고 해서 원래 음성의 MOS는 변하지 않는다는 사실에 착안!).
손실 함수
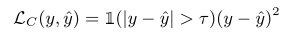
clipped mean squared error(CMSE)를 모델의 loss로 사용한다. 즉, 예측 값과 정답 사이의 차이가 작을 때는 정답이라고 간주하고 loss를 0으로 만들어주는 방식이다. 이런 방식을 사용하는 이유는 MOS의 특성을 생각해보면 이해할 수 있다. 같은 사람이 서로 다른 오디오에 같은 점수를 매겼다고 할 때, 두 오디오의 품질은 비슷한 것이지 정확히 동일한 것은 아니기 때문에 모델이 MOS를 예측할 때도 값을 정확하게 예측하는 것은 오히려 정확한 예측이 아닐 수 있는 것이다. 따라서 threshold 내의 차이는 용인해 줄 수 있는 CMSE를 사용한다.

CMSE를 사용한 최종 loss는 위와 같다. 여기서 MeanNet과 BiasNet의 밸런스를 맞추기 위한 하이퍼파라미터 lambda는 4로 설정하여 상대적으로 더 학습이 어려운 BiasNet에 포커스를 맞췄다고 한다.
실험 결과
모든 실험 세팅에 대해서 랜덤시드를 바꿔가면서 10번의 실험을 반복하였고, MSE, spearmans rank correlation coefficient(SRCC), linear correlation coefficient(LCC)를 metric으로 사용한다.
한 음성 합성 모델의 평균적인 성능을 나타내 주는 system-level MOS의 순위를 비교하는 것이 가장 중요하므로, system-level SRCC를 중요한 metric으로 여긴다.
베이스라인 비교

베이스라인으로 MOSNet을 정해서 utterance-level과 system-level MOS에 대해서 성능을 비교한다. 두가지 데이터셋에 대해서 모두 MBNet이 높은 성능을 기록했다.
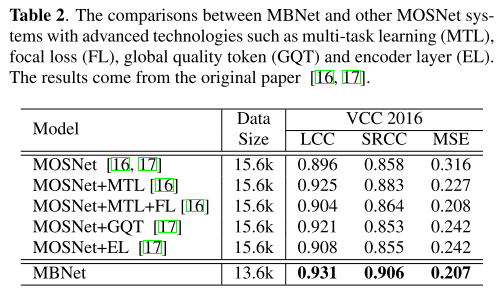
그동안 MOSNet에 여러 테크닉을 결합한 모델들이 많이 제시되었는데 그들과 MBNet을 비교해도 MBNet이 높은 성능을 보여주고, 앞으로 MBNet에 비슷한 테크닉들이 결합된다면 추가적인 성능 향상을 기대해볼 수도 있다.
Ablation Study
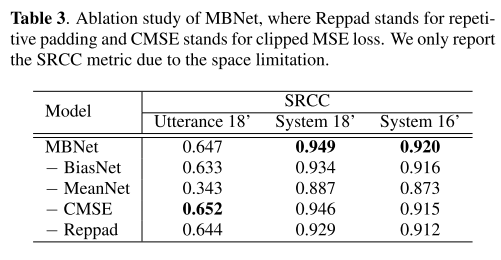
네트워크 구조와 손실함수, 패딩 방식을 바꿔가면서 ablation study를 진행했다. 한 경우를 빼고 original 방식이 가장 높은 성능을 보여준다. 특히, BiasNet만 사용할 경우 성능이 크게 하락하는 것을 보아 bias 정보는 mean과 합쳐졌을 때 유의미한 역할을 한다고 판단된다.
BiasNet 분석
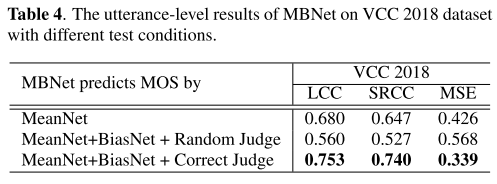
BiasNet이 각 평가자의 bias를 잘 학습했다면 실제로 주어진 오디오에 할당되었던 평가자들이 매칭되었을 때 가장 좋은 MOS 예측 성능이 기록되어야 할 것이다. 이를 확인하기 위해 위처럼 Random Judge, Correct Judge 세팅으로 성능을 비교해봤는데 Random Judge를 배정할 경우 성능이 크게 저하되었다. 따라서 BiasNet이 저자들이 의도한대로 bias를 잘 학습하였다.
의견
- 딥러닝을 활용한 음성 합성 연구를 살펴보면서 항상 아쉬웠던 부분이 주관적인 MOS를 사용하기 때문에 모델을 학습할 때 적당한 지점에서 타협을 봐야하고, 다른 모델과 비교하려면 다시 같은 청취자들을 대상으로 MOS 테스트를 진행해야한다는 점이었다. 하지만 이렇게 MOS를 예측할 수 있는 네트워크가 신뢰성을 갖게 되면 추후 최적의 모델을 선정하는 과정이 단순화될 수 있겠다는 희망을 가져본다.
- MOS 예측을 regression의 접근이 아니라 classification 문제로 접근한다면 어떤 장단점이 있을지 생각해보면 좋겠다.




Leave a comment