
MelGAN
Kumar, Kundan, et al. “Melgan: Generative adversarial networks for conditional waveform synthesis.” arXiv preprint arXiv:1910.06711 (2019).
들어가며
GAN으로 raw waveform의 실제 같은 sample들을 생성해내는 것은 어렵다는 기존 연구가 있는데 MelGAN은 이에 반하여 높은 품질의 음성을 GAN으로 합성해낼 수 있다는 것을 보인다. 이 모델은 non-autoregressive하고 fully convolutional하며, 다른 경쟁 모델들보다 파라미터 수가 적어서 효율적이라는 장점을 갖고 있다고 하는데 어떤 부분들이 이를 위해서 고안되었는지 살펴 보자.
핵심 요약
- MelGAN은 추가적인 증류(distillation)방식이나 지각 손실(perceptual loss)을 사용하지 않고 고품질의 TTS가 가능하다.
- 음악 번역, 음성 합성, 비조건부 음악 합성 실험에서 모두 회귀 모델에 버금가는 우수한 결과를 보인다.
- 멜 스펙트로그램 역변환 연산이 기존의 Wavenet 기반 모델들보다 훨씬 빠르다.
모델 구조
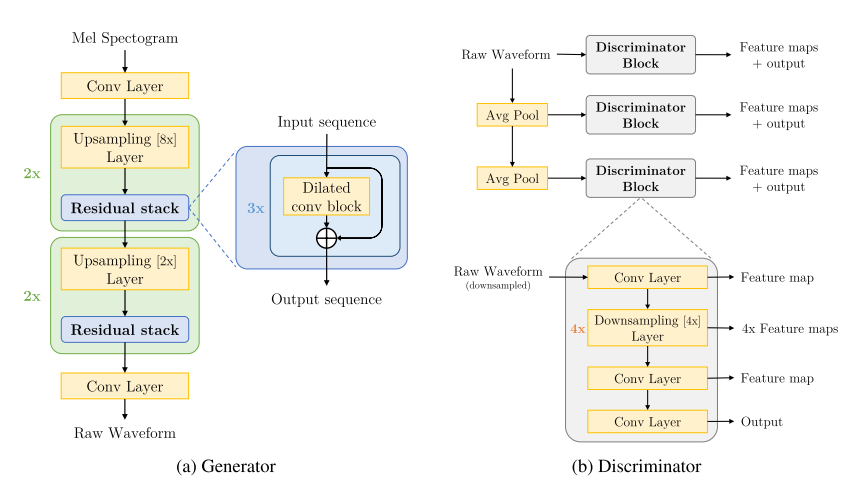
- 생성자
- 멜 스펙트로그램을 입력으로 받아서 원 파형(raw waveform)을 출력하는 네트워크이다.
- 1d conv와 residual stack의 조합으로 이루어져 있다.
- 전통적인 GAN과 다르게 노이즈 벡터를 입력으로 함께 사용하지 않았다. 기존의 다른 연구들도 조건부로 입력되는 정보가 매우 강력하다면 노이즈 입력은 중요하지 않다는 결과를 보여준다고 한다.
- 네트워크의 각 층별로 가중치 정규화(weight normalization)를 적용하였고, 이는 다른 정규화 방식들보다 좋은 성능을 보였다.
- 판별자
- 3개의 다른 스케일을 가진 블록을 결합한 다중 스케일 구조이다. (D1=오디오 스케일, D2=다운샘플 2배 스케일, D3=다운샘플 4배 스케일)
- 각 스케일의 판별자에서 구해진 특성 맵은 추후 feature matching 손실을 구하는 데 쓰인다.
- Window-based objective
- 이미지 연구에서 제시된 PatchGAN의 아이디어를 차용한 것이다.
- 기존의 GAN 판별자는 오디오 시퀀스 전체의 확률분포를 보고 가짜인지 진짜인지 분류하는 것을 학습했다면, MelGAN의 다중 스케일 판별자는 작은 오디오 덩어리의 분포 사이에서 분류하는 방법을 학습한다.
- 필수적인 고주파수 구조를 잘 잡아내고, 파라미터 수가 적으면서 빠르게 실행할 수 있으며 다양한 길이의 오디오 시퀀스에 적용될 수 있어서 이 방식을 채택했다고 한다.
- 생성자처럼 가중치 정규화를 적용했다.
- 3개의 다른 스케일을 가진 블록을 결합한 다중 스케일 구조이다. (D1=오디오 스케일, D2=다운샘플 2배 스케일, D3=다운샘플 4배 스케일)
손실 함수
-
기본적인 GAN 손실 함수에 hinge loss를 결합하였다.
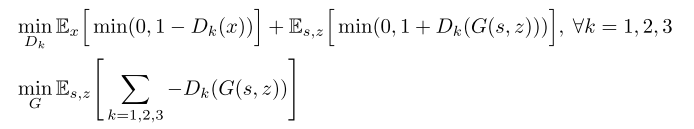
- 판별자의 손실을 구하는 식에서 기댓값을 구하는 부분에 max가 쓰여야 하는데 min이라고 잘못 적혀 있다.
-
그리고 생성자의 경우 Feature Matching 손실 함수를 추가해주었다. Feature Matching은 실제 데이터와 가짜 데이터에 대한 판별자 특성 맵의 차이를 계산하는 것으로 L1 거리를 통해 정의된다.
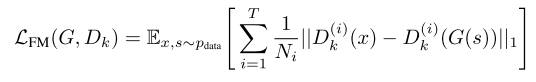
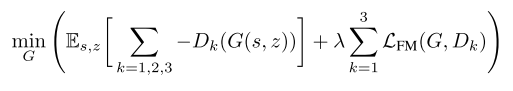
의견
- 저자들도 언급하고 있듯이 단순한 Parallel 구조를 가진 모델이지만, 커널 사이즈와 스트라이드를 잘 조절하여 잡음이 거의 없도록 최적화를 잘 시킨 점에서 훌륭한 연구이다.




Leave a comment