
Meta-StyleSpeech
Min, Dongchan, et al. “Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation.” arXiv preprint arXiv:2106.03153 (2021).
들어가며
개인화 음성 합성에 대한 요구가 늘어가고 있는 만큼 적은 양의 데이터로 빠르게 새로운 화자의 음성을 합성해내는 기술이 중요해졌다. 그러나 현재 존재하는 방법들은 많은 양의 데이터로 fine-tuning이 필요하거나 fine-tuning 없이 낮은 적응 품질을 보이는 경우가 대다수다.
본 논문에서는 이 문제를 해결하고자 StyleSpeech를 제안한다. StyleSpeech는 StyleGAN에서 영감을 받아 SALN(Style-Adaptive Layer Normalization)이라는 방법을 사용하여 새로운 화자의 스타일을 효율적으로 적응시킨다. 뿐만 아니라 meta learning을 접목시킨 Meta-StyleSpeech로 확장시켜서 아주 적은 양의 데이터로도 새로운 화자에 대한 적응이 가능한 모델을 제시한다.
핵심 요약
- 짧은 레퍼런스 음성으로부터 style vector를 추출하고 이를 SALN에 접목시킴으로써 효율적인 다화자 음성 합성이 가능하도록 하였다.
- 훈련 시 보지 못했던 화자에 대해서도 음성 합성이 쉽게 가능하도록 StyleSpeech에 meta learning을 붙여서 Meta-StyleSpeech로 확장하였다.
- 다화자 음성 합성이나 one-shot short-length 화자 적응과 같은 다양한 태스크에서 SOTA 성능을 기록했다.
모델 구조
StyleSpeech
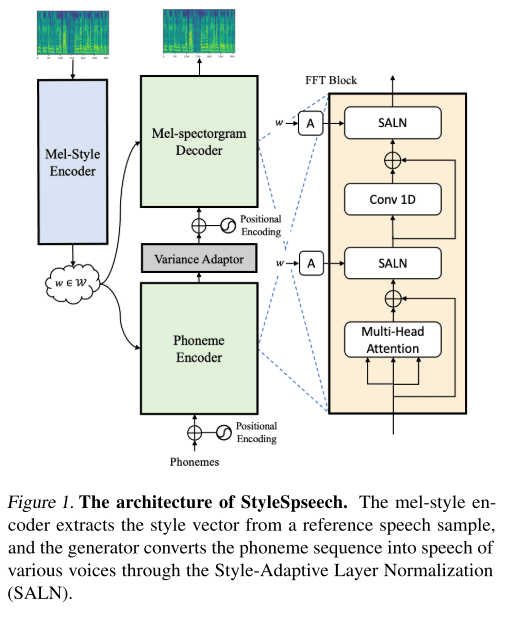
StyleSpeech는 기본적으로 FastSpeech 2에 기반한 구조를 갖고 있고 여기에 다화자의 목소리를 낼 수 있도록 Mel-Style Encoder라는 추가적인 컴포넌트가 결합된 형태를 띤다.
Mel-Style Encoder에서는 레퍼런스 음성의 멜 스펙트로그램을 입력으로 받아서 style vector를 출력하는 과정이 이루어진다. 그 안에서는 세부적으로 멜 스펙트로그램의 프레임들을 hidden sequence로 바꿔주는 Spectral processing, gated CNN으로 주어진 음성의 연속적인 정보들을 포착하는 Temporal processing, 전역적인 정보를 인코딩하기 위한 Multi-head self-attention이 차례로 수행된다.
그렇게 추출된 style vector는 generator의 Phoneme Encoder와 Mel-spectrogram Decoder에 입력으로 쓰인다. 정확히는 그 내부의 SALN에서 입력된 feature vector를 normalizing하는 과정에서 곱하고(scaling) 더해주는(shifting) gain과 bias를 계산할 때 이용된다. 그리고 gain과 bias는 style vector를 affine layer에 통과시킴으로써 구해진다.
Meta-StyleSpeech
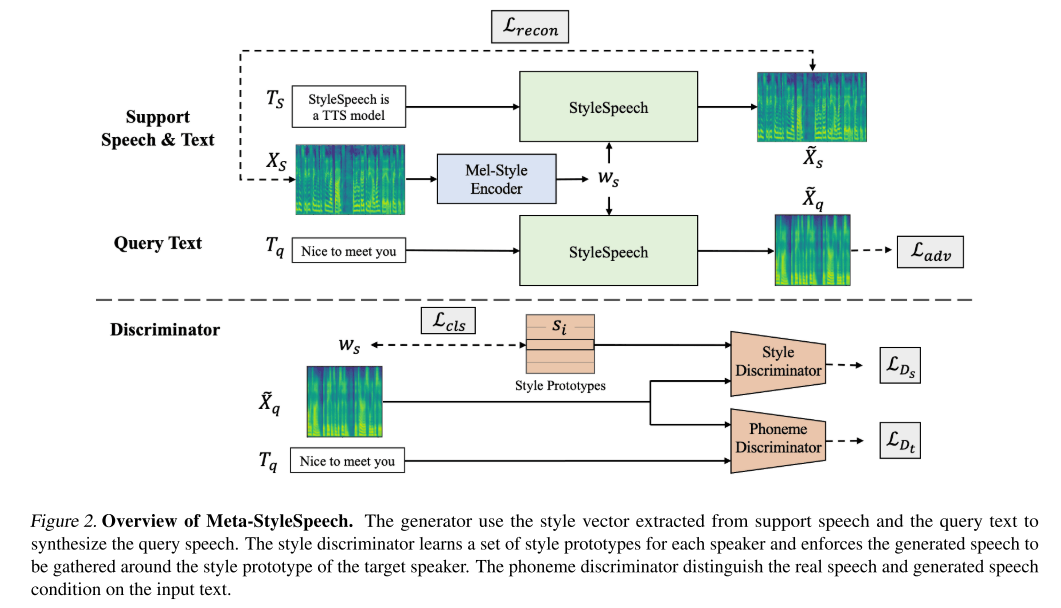
StyleSpeech가 새로운 화자에 대해서 음성을 합성할 수 있는 능력을 갖고 있지만, 적은 샘플의 오디오로 새로운 화자의 음성을 합성해내는 것은 여전히 어려운 일이다. 특히, 그 샘플의 길이가 짧을 때는 더더욱 힘들다.
그래서 저자들이 생각해낸 방법은 meta learning을 적용하는 것이다. 상황을 새로운 화자에 대해서 오직 하나의 음성 샘플 밖에 얻을 수 없는 경우(one-shot learning)라고 가정한 다음에 이를 episodic meta learning으로 해결하고자 한다. 각 episode마다 하나의 support(speech, text 쌍) 샘플을 추출하고 해당 타겟 화자의 query text를 추출한다. 이때 학습의 목적은 support speech에서 추출된 style vector와 query text로부터 generator가 생성한 query speech를 실제 타겟 화자가 말한 것처럼 만드는 것이다. 이 경우에는 실제 정답 멜 스펙트로그램이 없으므로 추가적인 2개의 discriminator들을 이용하여 generator를 적대적으로 학습시키는 방식을 사용한다.
- style discriminator
- 생성된 speech가 타겟 화자의 목소리로 생성된 것인지 판별하는 discriminator
- style prototype을 이용해 training set에 속하는 화자들의 특성을 저장함
- phoneme discriminator
- querty text와 speech를 입력으로 받아서 실제 음성인지 아닌지 판별하는 discriminator
학습 방식
StyleSpeech
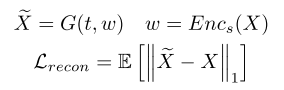
generator를 통해 합성된 멜 스펙트로그램과 실제 멜 스펙트로그램의 L1 distance로 정의되는 reconstruction loss를 최소화하면서 모델을 훈련시킨다.
Meta-StyleSpeech
- style discriminator는 아래와 같이 classfication loss를 줄이는 쪽으로 학습하며 그로부터 style prototype이 각 화자의 고유한 특징을 가지게 된다. 타겟 화자의 style prototype과 생성된 speech의 내적을 통해 scalar 값을 만들고 이로부터 discriminator loss를 계산한다. 생성된 speech가 discriminator의 출력 값을 1(실제 음성이라 판단)로 만들려면 style prototype과의 내적이 1과 가까워야 한다. 즉, 어떤 잠재 공간 상의 style prototype과 가까운 곳에서 생성된 음성이 얻어져야 함을 의미하고 이는 generator가 하나의 짧은 샘플로부터 타겟 화자의 공통적인 스타일을 따르는 음성을 합성하는 법을 배우게 된다는 것을 의미한다.
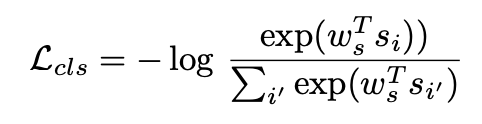
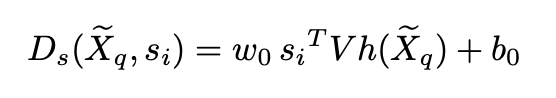
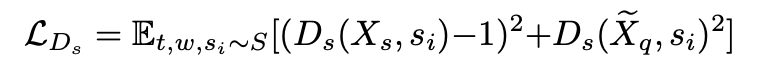
- phoneme discriminator는 support speech와 text를 입력으로 받았을 때는 1이라 예측하고, 생성된 query speech와 text를 입력으로 받으면 0이라고 예측해야 하므로 loss는 아래와 같이 구성되어 학습된다.
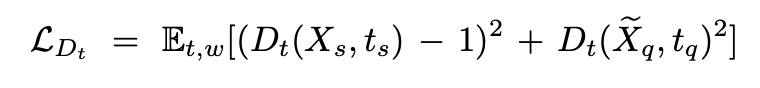
- 최종적으로 (1)generator와 mel-style encoder update, (2)discriminator 업데이트를 번갈아가면서 episodic meta learning을 수행한다. 이때 알파는 10으로 설정한다.
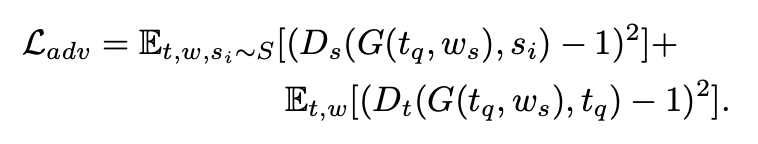
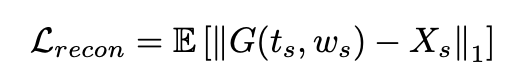
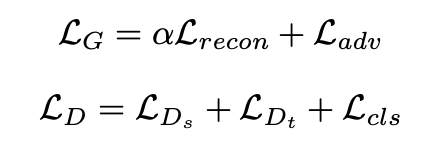
실험 결과
학습된 화자들에 대한 음성 합성
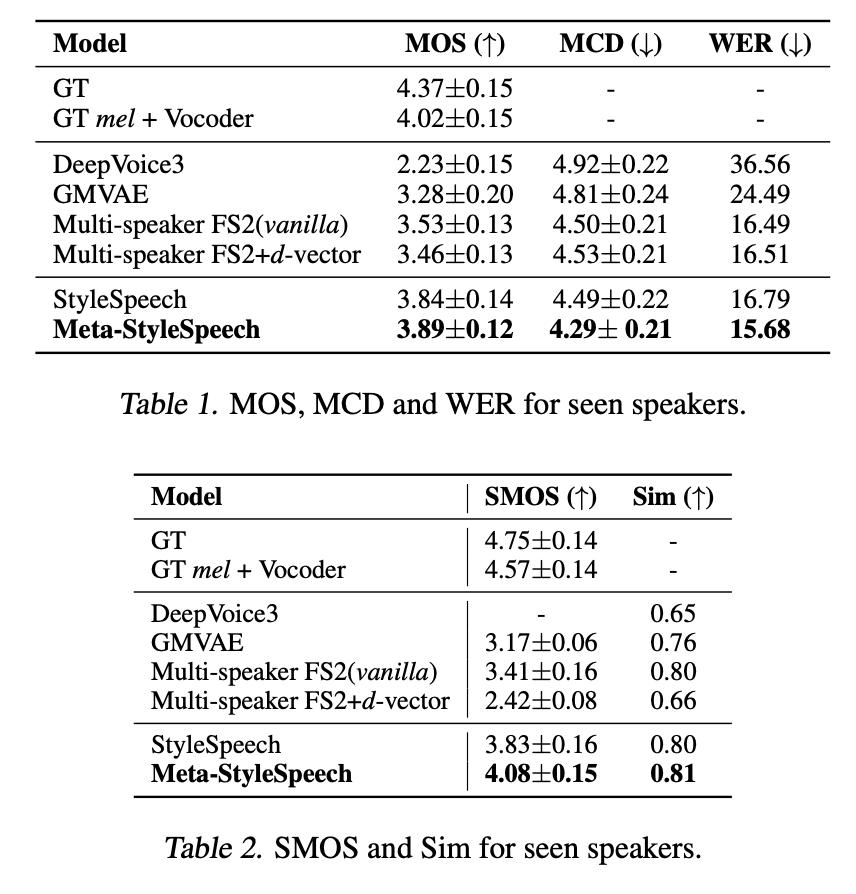
주관적인 지표인 MOS, 객관적 지표인 MCD, WER 모두 본 논문에서 제시하는 모델의 값이 가장 좋게 나타나고 실제 음성과 유사성도 가장 높게 나타난다.
학습되지 않은 화자들에 대한 음성 합성
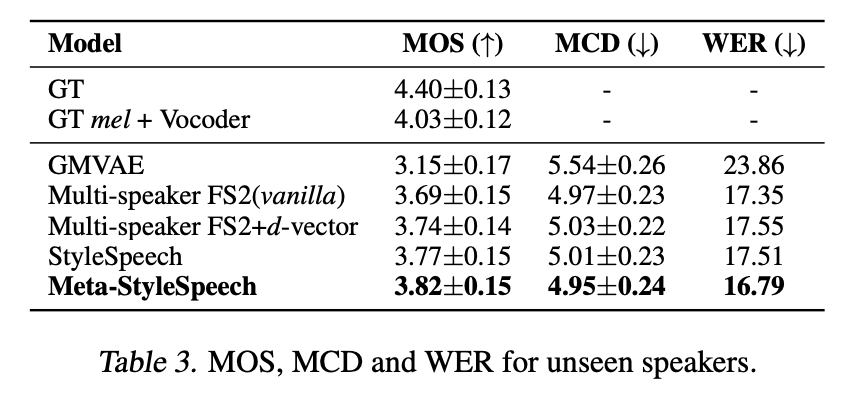
training set에서 보지 못했던 화자들에 대한 음성 합성 결과 역시 Meta-StyleSpeech에서 가장 좋게 나타난다.
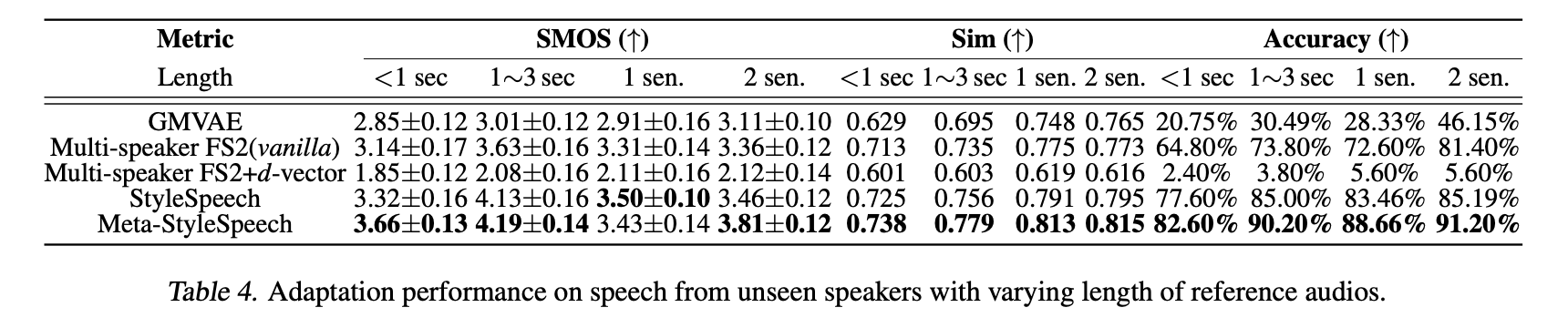
그리고 새로운 화자 적응에 사용되는 레퍼런스 음성의 길이를 조절하면서 실험해봤을 때 1가지 경우만 제외하고 Meta-StyleSpeech에서 가장 좋은 성능이 나타났고 1초보다 짧은 길이의 음성만 사용해도 베이스라인들의 성능을 크게 뛰어넘음을 알 수 있다.
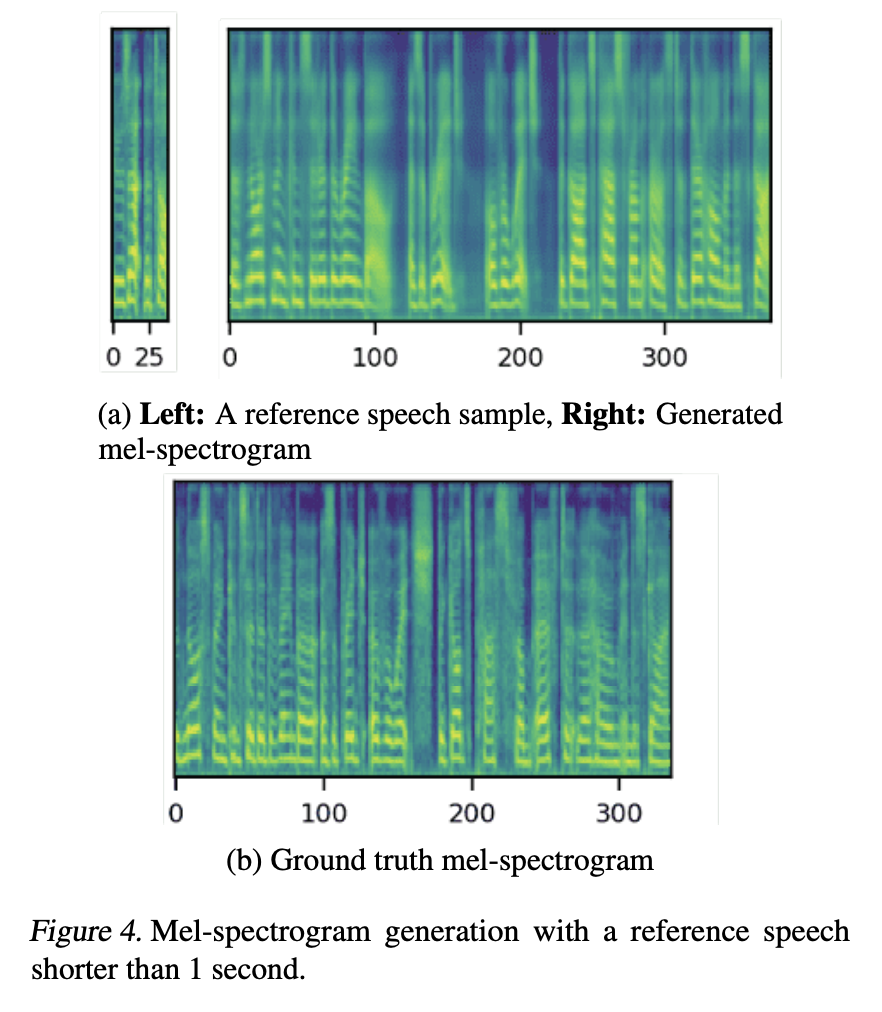
그림 4만 보아도 선명한 공명 주파수와 포먼트 표현으로부터 1초보다 짧은 음성으로 만든 멜 스펙트로그램이 실제와 유사함을 확인 가능하다.
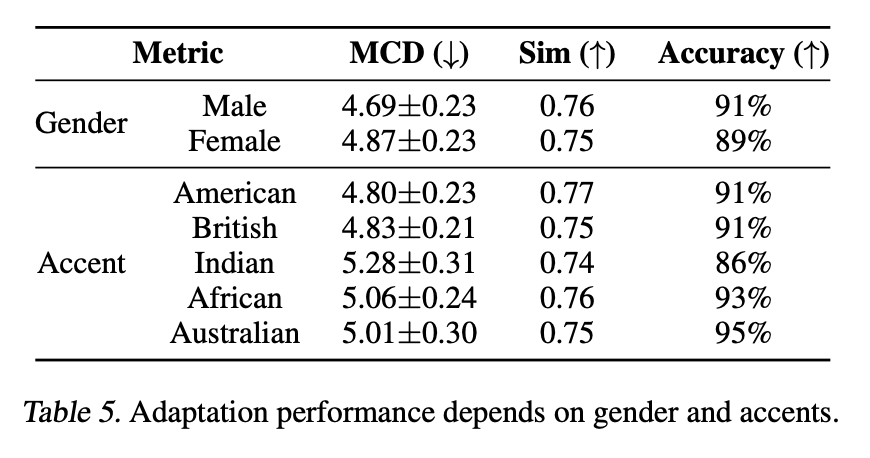
Meta-StyleSpeech가 gender나 accent에 따라서 적응 성능이 크게 바뀌는지 확인해보았는데 gender에는 상관없이 안정적인 성능을 보였고 accent의 경우 Indian accent에 대해서만 약간의 성능 저하가 관찰됐다. 이는 Indian accent가 다른 accent들보다 발화 스타일의 변동폭이 크기 때문이다.
스타일 벡터 시각화
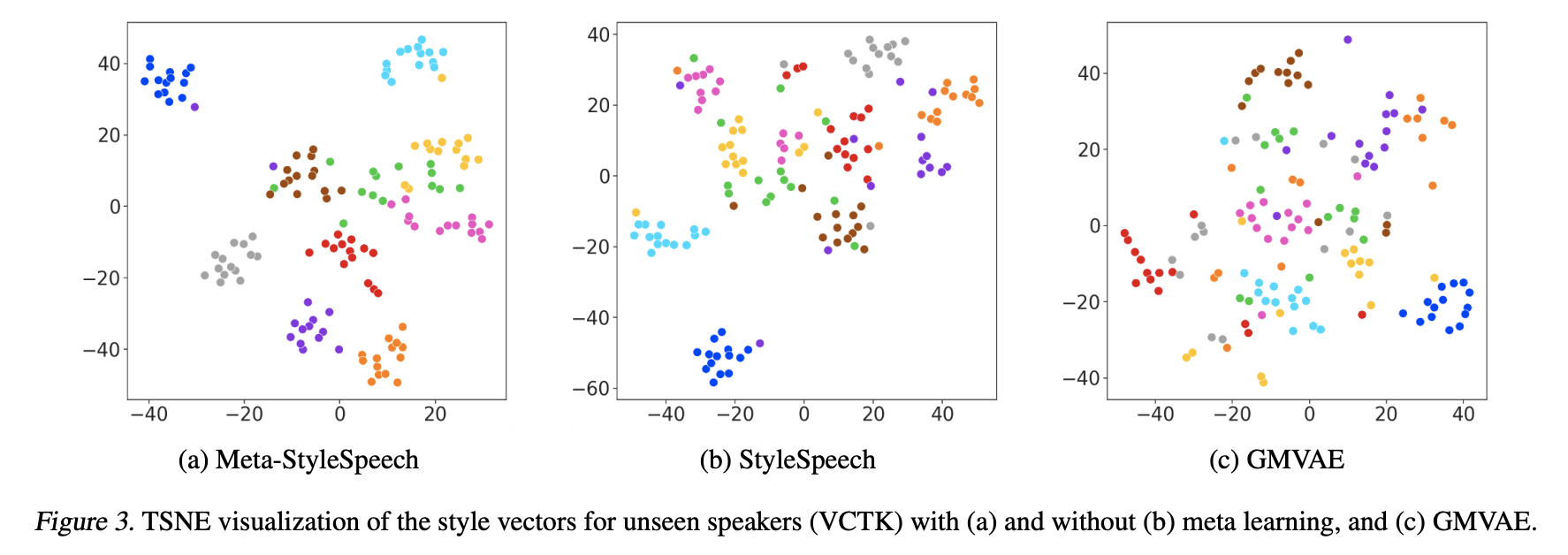
GMVAE < StyleSpeech < Meta-StyleSpeech 순으로 style vector의 군집화가 잘 이루어져 있다.
Ablation Study
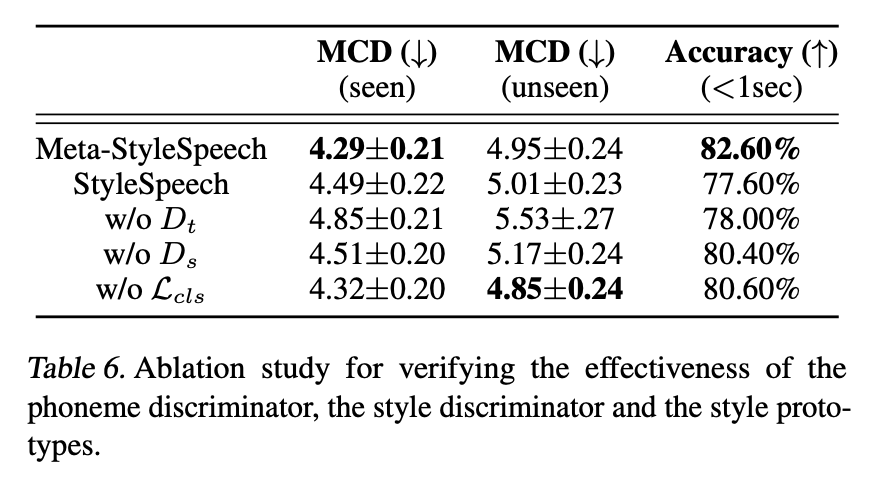
Meta-StyleSpeech의 핵심 컴포넌트들을 제거하면서 실험해본 결과 모두 성능의 저하가 관찰되었다.
의견
- 음성 합성에 StyleGAN의 아이디어를 가져와 적용한 점이 인상적이다.
- meta learning으로 화자의 정보를 기억해내는 방법을 사용해서 one-shot만으로도 적응이 가능하게 만든 것이 놀랍다.
- 짧은 길이의 샘플에 대해서만 실험을 진행했는데 샘플의 길이를 점점 늘려갔을 때 어느 정도 길이에서 더 이상 성능의 향상이 없는지도 체크해주면 더 좋았을 것 같다. 왜냐하면 실제 적용 시에는 1초보다 짧은 음성으로 학습시키진 않을 것이고 최대의 성능을 뽑아내기 위해서 조금 더 긴 음성을 활용하려고 시도할 것이기 때문이다.




Leave a comment