
Multi-speaker Emotional Text-to-speech Synthesizer
Cho, Sungjae, and Soo-Young Lee. “Multi-Speaker Emotional Text-to-Speech Synthesizer.” Proc. Interspeech 2021 (2021): 2337-2338.
들어가며
다양한 감정을 가진 음성을 합성하려는 TTS 연구들이 많이 이루어져 왔지만, 합성해낼 수 있는 화자의 수가 적거나 감정 class간 분포를 균일하게 유지하여 데이터셋을 구성하려는 노력이 필요하다.
본 논문에서는 (최대한 balance를 맞추려고 노력은 하지만)imbalanced data를 가지고도 다화자에 대하여 다양한 감정의 음성을 안정적으로 합성해내는 방법을 소개한다.
핵심 요약
- 음성의 silence 구간을 voice activity detection(VAD)으로 제거하여 Tacotron 2의 학습 속도를 빠르게 개선했다.
- 데이터셋에서 다른 화자에게는 존재했지만 특정 화자에 대해서 존재하지 않았던 감정도 합성해낼 수 있는 모델을 만들었다.
- curriculum learning을 사용하여 모델이 감정과 사람의 특징을 찬찬히 배워나가게 했다.
데이터셋
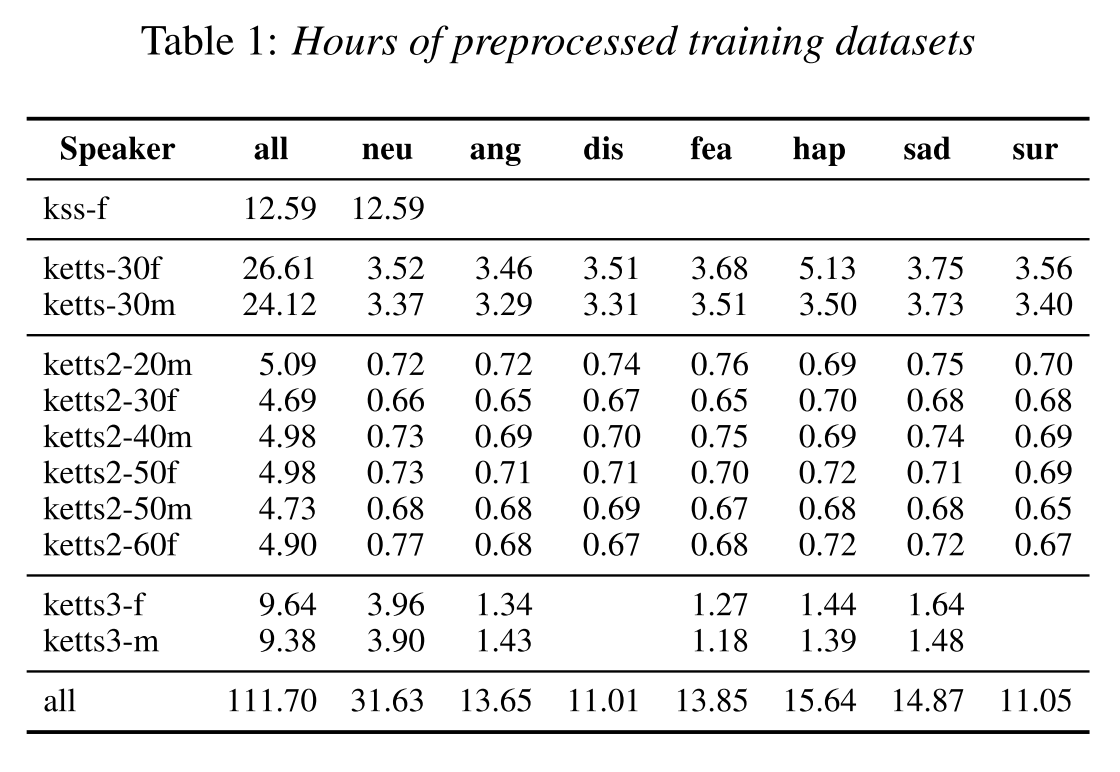
curriculum learning은 1)single speaker, neutral dataset으로 학습, 2)neutral speech from all speakers으로 학습, 3)emotional speech from all speakers으로 학습의 3단계로 진행이 되기 때문에 이에 맞는 데이터셋을 준비했다.
- kss-f: 1단계에서 쓰이는 single speaker neutral dataset이다.
- ketts: 1 female, 1 male. 2명에게 다른 문장 셋이 주어졌지만 같은 문장이 감정별로 녹음되었다. female의 happy만 빼고 speaker, emotion 밸런스가 맞다.
- ketts2: 3 female, 3 male. 같은 문장이 화자별로 감정별로 녹음되었다. 즉, speaker, emotion 밸런스가 모두 맞다.
- ketts3: 1 female, 1 male. disgust와 surprise 감정이 녹음이 안되어 있다. 화자별로 같은 문장 셋이 주어졌지만, 감정별로 다른 문장이 녹음되었다. 따라서 speaker 밸런스는 맞지만 emotion 밸런스는 맞지 않다.
curriculum learning 2단계에서부터는 전체 데이터셋에서 oversampling을 통해 mini-batch 안에 speaker-emotion pair의 비율을 동일하게 조정했다.
모델 구조
모델은 Tacotron 2와 WaveGlow의 조합으로 이루어졌다.
Tacotron 2에는 speaker embedding과 emotion embedding을 추가하여 context vector에 concat시켜주도록 약간 수정하였다.
실험 결과
데모 페이지에서 확인할 수 있듯이 같은 문장인데도 다양한 감정으로 서로 다른 화자의 음성을 합성하는게 가능하다.
의견
- 총 2페이지로 비교적 짧은 논문이지만 뚜렷한 목표의식을 가지고 적재적소에 유용한 기법을 적용한 것이 인상적이다.
- curriculum learning을 적용한 것을 큰 contribution으로 언급하고 있는데 그렇다면 curriculum learning 없이 처음부터 전체 데이터셋으로 학습하면 어떤 차이가 나타나는지 MOS 결과로 보여줬으면 좋았을 것 같다.




Leave a comment