
G2P using byte representation
Yu, Mingzhi, et al. “Multilingual grapheme-to-phoneme conversion with byte representation.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
들어가며
인코더-디코더 구조를 가진 뉴럴넷을 활용한 G2P 성능이 mono-lingual, multi-lingual 가릴 것 없이 향상되고 있다. 하지만 그동안 이루어진 대부분의 multi-lingual 연구는 비슷한 grapheme을 공유하는 언어들(e.g. European languages) 사이에서만 이루어져서 전혀 다른 표기법을 따르는 언어들로 multi-lingual G2P 모델을 만드는 것은 여전히 어려운 숙제다. 본 논문에서는 Transformer 기반의 모델에 byte-level representation을 입력으로 넣어주어 위의 문제를 해결할 수 있음을 보인다.
핵심 요약
- 256 size의 vocab만을 가진 byte-level input representation으로 G2P를 했을 때 character-level을 사용했을 때보다 정확도가 향상되었다.
- byte representation을 사용할 경우, 형태가 비슷하거나 발음이 비슷한 문자끼리 유니코드 번호 인접하다는 사실을 통해 문자 간 knowledge sharing이 가능한데 character representation에는 knowledge sharing이 없다.
- european languages보다 multi-byte를 사용하는 east asian languages에서 G2P 성능 향상이 뚜렷하게 관찰되었다.
모델 구조
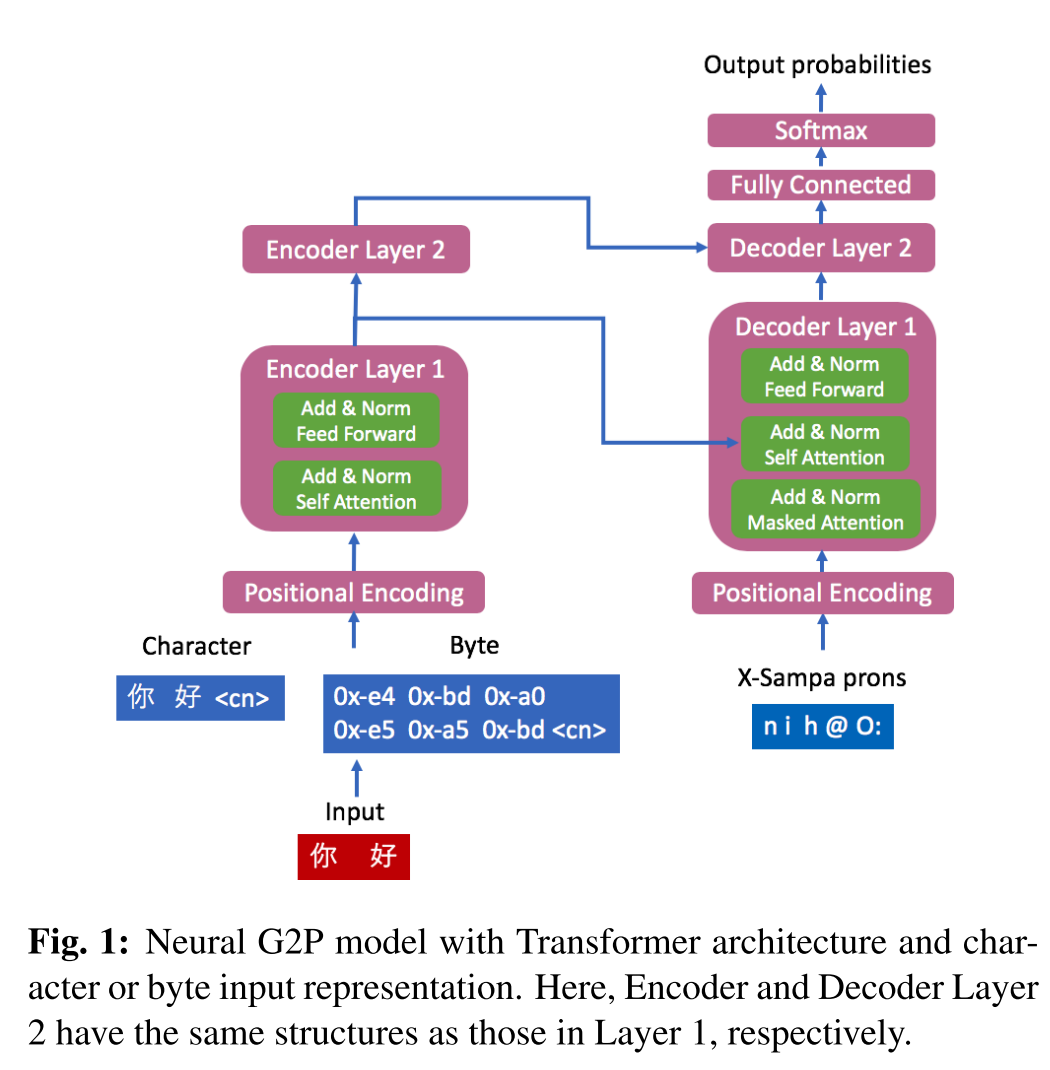
인코더와 디코더 layer가 2개씩으로 이루어진 Transformer 구조이며 head의 개수는 8개로 설정했다. 입력으로 넣어주는 character나 byte 시퀀스의 마지막에 language index를 달아주는데, 이는 같은 grapheme을 공유하는 언어들 사이에서 발음은 각각 다르게 나타나기 때문이다.
실험 결과
mono-lingual 모델의 성능
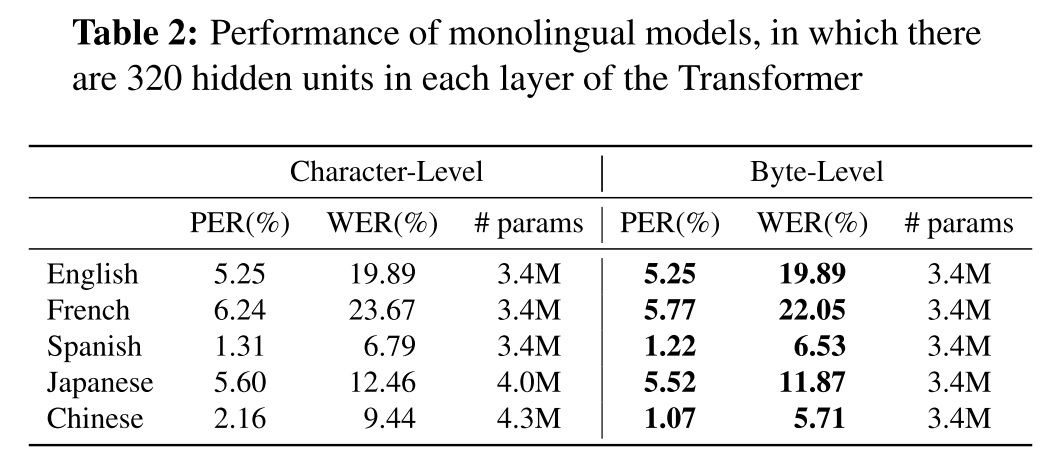
mono-lingual 모델에서 character, byte representation을 사용했을 때 영어는 성능이 동일하다. 이는 영어 문자 하나가 정확히 1byte로 표현되기 때문에 byte로 표현하는 것과 character로 표현하는 것에 큰 차이가 없었음을 보여준다. 반면에 비슷한 알파벳을 쓰는 프랑스어와 스페인어는 성능이 향상됐는데 이 두 언어에는 multi-byte로 표현되는 몇몇 알파벳이 포함되어 있기 때문이다. 그리고 중국어에서 가장 큰 성능 향상이 관찰되었는데 중국어와 일본어에서는 byte를 사용할 경우 모델의 사이즈도 많이 작아진다.
multi-lingual 모델의 성능
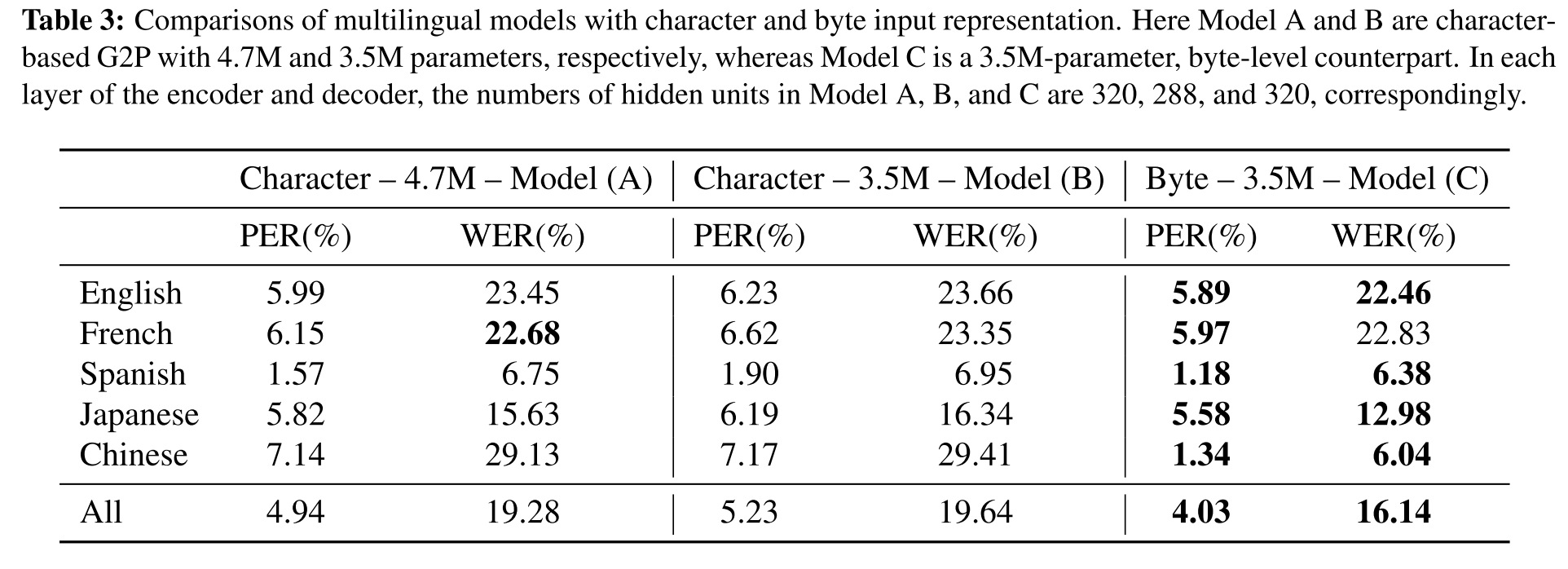
A,C의 결과를 비교해보면 같은 수의 hidden unit을 사용했지만 byte의 경우가 모델 크기가 훨씬 작으며 French의 WER 빼고는 모두 우월한 성능을 보여준다. 그리고 A를 C와 동일한 파라미터 수를 가진 모델로 축소하여 실험해보면 성능이 더 나빠지는 것을 확인할 수 있다.
의견
- 일본어와 중국어는 한자를 어느 정도 공유하고 있기 때문에 multi-lingual 모델을 학습시킬 때 부담이 조금 줄었을 것 같다. 여기에 한국어를 추가해서 아예 새로운 문자 형식이 또 등장하면 모델의 성능이 얼마나 하락할지 평가해보고 싶다.
- byte로 grapheme을 인코딩하여 모델을 학습시켜보겠다는 접근이 신선했다.




Leave a comment