
NN-KOG2P
Kim, Hwa-Yeon, Jong-Hwan Kim, and Jae-Min Kim. “NN-KOG2P: A Novel Grapheme-to-Phoneme Model for Korean Language.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
들어가며
TTS 기술이 발전하고 AI 서비스에 많이 접목되면서 빠르고 높은 성능의 G2P 기술이 요구되고 있다. 전세계 언어의 G2P 기술은 rule-based, statistical-based, 그리고 neural-network-based 방식 등으로 다양하게 구현되고 있는데 최근 Transformer 기반의 G2P가 가장 좋은 성능을 보여준다고 알려져 있다. 하지만, 한국어 G2P 연구는 주로 rule-based로 이루어져 왔고 neural net을 사용한 시도가 없다. 이 점을 고려해서 본 논문은 한국어의 발음 특성을 반영한 neural net 기반 G2P 모델을 제시한다.
핵심 요약
- 단순한 Feed Forward Neural Network를 사용한 한국어 G2P 모델이다.
- 한국어의 발음 특성을 고려한 입력 시퀀스를 구성하였다.
- 추론 속도가 입력의 길이에 영향을 받지 않으므로 실시간 AI 서비스에 적용 가능하다.
모델 구조
Eumjeols and Phonological Phrasing Information
한국어는 phonetic language이기 때문에 의미나 형태론적 패턴에 따라 발음이 달라질 수 있다. 그러므로 이를 입력 character와 함께 정보로 넣어주는 것이 중요한데 이러한 추가 정보를 phonological phrasing information이라고 한다.

예를 들어, 표 1과 같이 ‘경찰은 용의자의 지적수준이 높을 것이라고 지적했다.’라는 문장이 있으면 우선 어절 단위로 문장을 나누고 각 어절을 음절로 나누면서 phonetic phrasing information을 어절의 끝에 붙여주는 형식이다.
Representation of Context and POS through Surrounding Eumjeols
한국어의 의미를 고려한 발음을 생성해주기 위해 주변 음절들로부터 정보를 추출해 context를 만들어줄 필요가 있다. 이를 식으로 표현하면 아래와 같다.
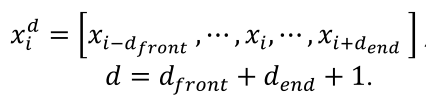
i 번째 음절의 feature를 만들어주기 위해서 앞뒤 정해진 수만큼의 음절 정보를 합쳐준다.
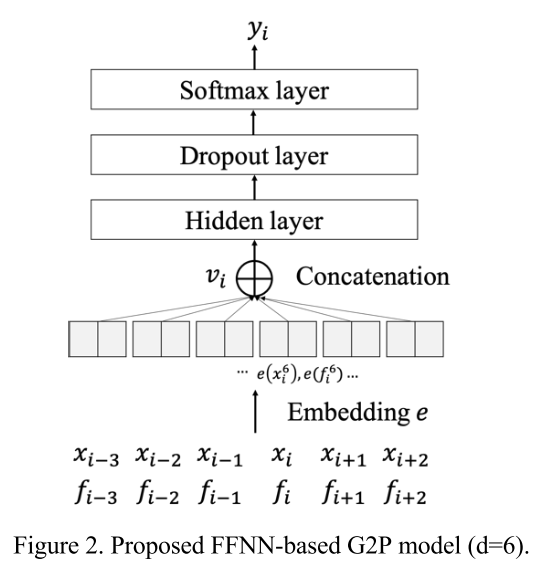
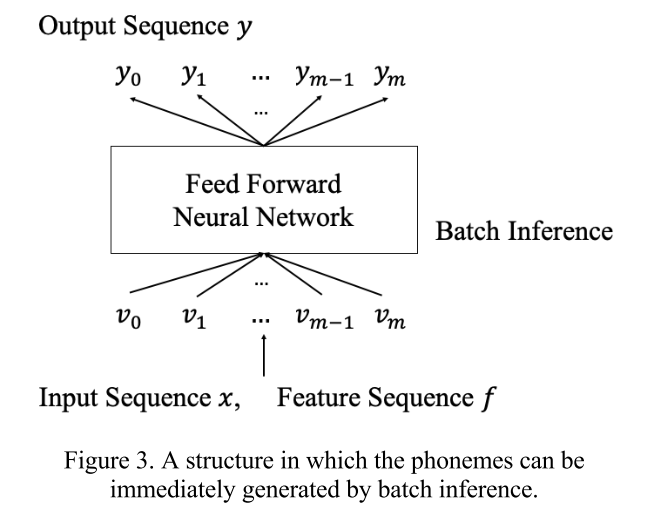
이렇게 구성된 음절 feature와 phonological feature를 각각 임베딩한 후 concat 하여 FFNN 모델을 통과시킨다. 그리고 위의 과정이 batch inference로 parallel하게 수행될 수 있기 때문에 입력의 길이에 상관없이 추론이 실시간으로 이루어진다.
실험 결과
G2P 성능 비교
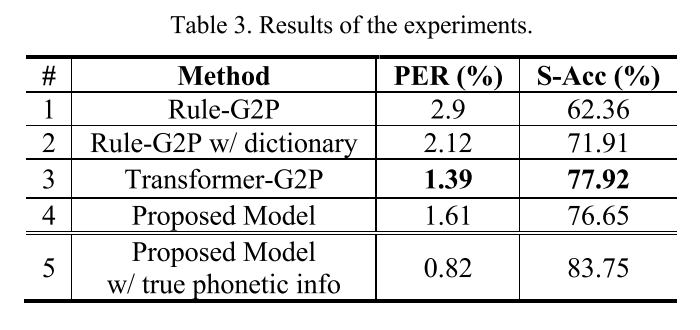
제안하는 모델이 Transformer-G2P 모델보다 PER, S-Acc 모두 약간 뒤쳐지는 결과가 나타났으나 좀 더 정확한 phonetic information을 주입해줄 경우 성능이 향상되어 Transformer-G2P를 능가하였다.
훈련 데이터 양에 따른 성능 비교
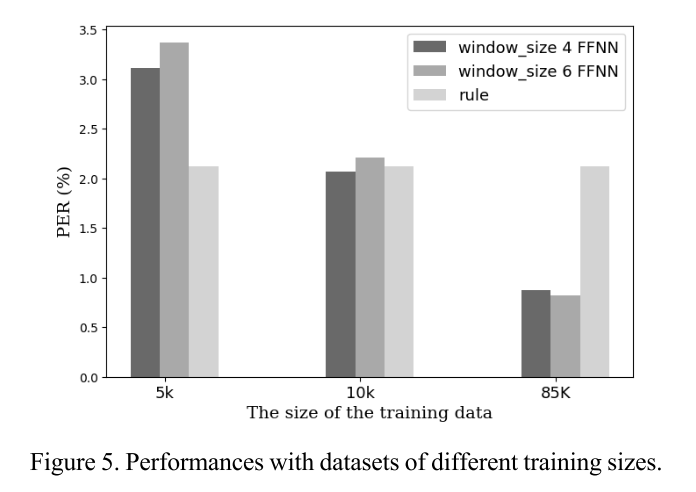
훈련 데이터의 양이 증가할수록 당연히 모델의 성능은 향상된다. 그림 5를 보면 10K, 85K의 충분한 데이터를 사용할 때는 제안하는 모델을 사용하는 것이 더 높은 성능을 기록하지만, 5K와 같이 적은 데이터를 사용할 때는 rule 기반 모델이 에러가 더 적기 때문에 이런 상황에서는 제안 모델이 비효율적임을 알 수 있다.
의견
- 한국어와 같이 발음이 복잡한 언어의 G2P는 모델링만으로 풀어내기는 어렵다는 점에 착안해서 간결하게 feature engineering을 진행해준 것이 인상적이다.
- 학습 데이터가 적은 경우에는 모델이 발음의 변환 규칙을 학습할 기회가 적기 때문에 제안 모델의 성능이 안좋은 편인데, 이를 해결할 수 있는 data augmentation 방법을 찾아보는 것도 흥미롭겠다.

Leave a comment