
Neural Lexicon Reader
He, Mutian, et al. “Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge.” arXiv preprint arXiv:2110.09698 (2021).
들어가며
End-to-end TTS 모델을 학습시키기 위해서 만드는 데이터에는 많은 제약조건이 따른다. 왜냐하면 음성 말뭉치는 될 수 있으면 모든 knowledge를 포함하고 있어야 하고, 그 knowledge를 모델이 학습할 수 있어야 하기 때문이다. 결국 완벽한 모델을 만들기 위해서는 사람이 수동적으로 추가적인 knowledge를 주입해줘야 하는데 예를 들어서 일반적인 규칙에서 벗어난 pronunciation knowledge를 주입해주기 위해서 grapheme-to-phoneme(G2P) 파이프라인을 추가해주는 방식이 있다.
본 논문에서는 수작업으로 언어별 G2P 파이프라인을 따로 구성하지 않아도 외부 lexicon 정보를 활용하여 해당하는 문자의 pronunciation knowledge 얻어내는 방식으로 pronunciation error를 줄이는 TTS 모델인 Neural Lexicon Reader를 제시한다.
핵심 요약
- TTS 모델 내부에서 Token2Knowledge 어텐션을 사용함으로써 데이터셋 외부의 knowledge를 활용하는 일반적인 프레임워크를 제시한다.
- 언어별 전문 지식으로 G2P 파이프라인을 만드는 노력 없이 non-phonemic 스크립트로 학습 가능한 end-to-end TTS를 만들었다.
- 데이터 양이 적거나 학습한 언어와 다른 언어로 fine-tuning하는 transfer learning의 경우에도 lexicon-reading의 성능이 우수함을 보인다.
모델 구조
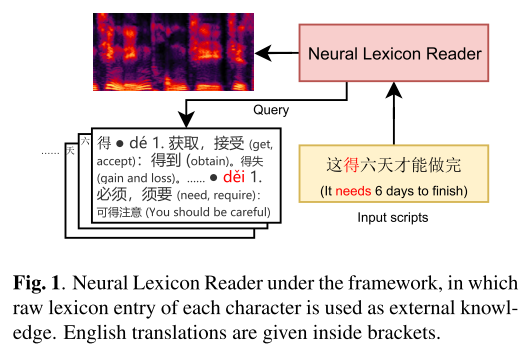
그림 1은 본 논문에서 제시하는 TTS 프레임워크 상에서 Neural Lexicon Reader의 역할을 보여준다. Neural Lexicon Reader에 입력된 문자를 lexicon에 Query로 보내고 어텐션 연산을 수행해서 가장 관련이 높은 pronunciation을 가져오는 방식으로 이해하면 된다.
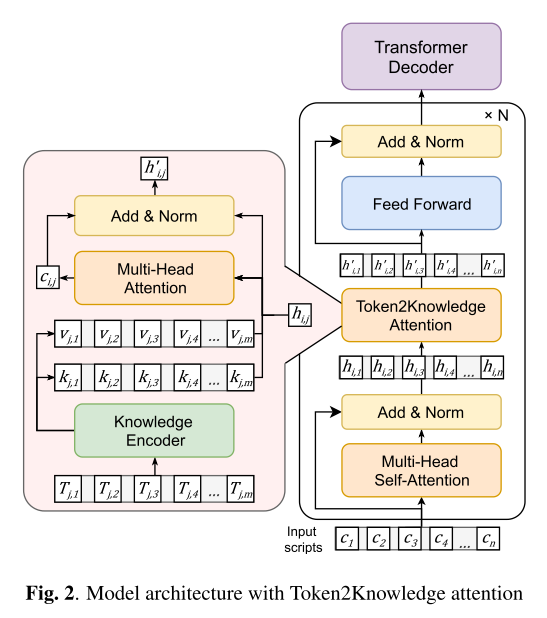
Neural Lexicon Reader의 자세한 구조는 그림 2와 같다. 기본적으로 Transformer로 이루어져 있고 Byte2Speech의 모델 구조를 따른다. 첫번째 인코더를 제외한 모든 인코더에는 Token2Knowledge 어텐션 모듈이 추가되었는데 lexicon에서 knowledge를 추출하는 핵심부분이다.
Token2Knowledge 내부의 knowledge encoder는 pretrained XLM-R로 구성되었는데 관련된 textual knowledge를 받아서 어텐션 계산을 위한 key와 value를 뽑아내는 역할을 한다. 여기서 key(K)는 semantic information을 담기 위해서 XLM-R의 final-layer embedding을 사용하고, value(V)는 shallow character identity를 담기 위해서 first-layer embedding을 사용한다. 입력 문자에 대한 hidden vector가 query(Q)로 사용되어 어텐션이 수행되고 여기서 context vector를 뽑아냄으로써 pronunciation knowledge를 가진 hidden vector로 바뀌어 출력되게 된다.
실험 결과
베이스라인 비교
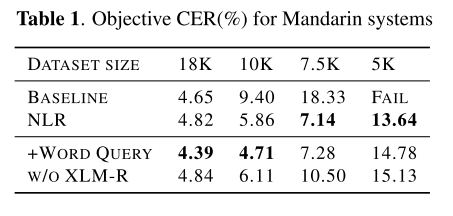
베이스라인으로는 Neural Lexicon Reader(NLR)에서 Token2Knowledge 어텐션을 제거한 Byte2Speech를 사용했다.
표 1은 single speaker Mandarin 데이터셋에 대해서 NLR과 베이스라인의 objective CER을 비교한 결과이다. 일단 데이터셋 전부인 18K 샘플을 사용했을 때 두 모델 모두 ground truth의 CER인 4.35%와 근접한 결과를 보여준다. 그리고 데이터셋의 크기를 줄여갈수록 오차가 커지지만, NLR이 적은 데이터를 가질 때도 어느 정도 안정적인 성능을 보여준다는게 확인된다. 이는 NLR이 데이터가 부족한 상황에서도 lexicon 텍스트에서 pronunciation knowledge를 성공적으로 뽑아내는 능력이 있음을 의미한다.
‘+Word Query’는 문장을 word 단위로 분리하여 lexicon에 query를 넣을 때도 word-level로 사용한 경우를 나타낸다. 이렇게 하면 억양이나 동철이음어(heteronym)에 대한 판단이 더 쉬워지는 장점이 있다. objective CER을 봤을 때 데이터의 양이 풍부할 때는 word 단위로 입력을 넣어줬을 때가 가장 좋았고 데이터가 적은 경우에는 NLR 기본 세팅보다 성능이 낮아졌다.
‘w/o XLM-R’은 knowledge encoder로 pretrained XLM-R을 사용하지 않는 경우다. 이때는 입력 스크립트를 임베딩하는 character embedding을 똑같이 사용하여 value를 만들고, character embedding 위에 추가적인 transformer 인코더를 붙여서 key를 생성한다. NLR 기본 세팅보다는 전체적으로 성능이 소폭 하락하지만, 적은 데이터로 실험했을 때 베이스라인보다는 여전히 좋기 때문에 pretrained 모델 없이도 적용될 수 있다는 것을 보여준다.
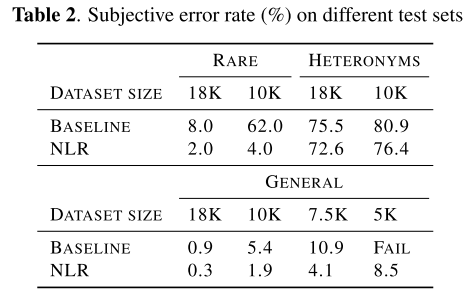
일반적인 데이터셋 말고도 rare한 문자를 포함하는 문장 100개로 test set을 구성해서 평가해보았다. 표 2에서 데이터셋 크기는 평가를 위해 사용된 모델을 학습할 때 사용한 데이터셋 크기이다. NLR이 knowledge를 활용한 방식으로 어려운 발음이나 보지 못했던 단어에 대해서도 적은 오류를 보여준다.
동철이음어 test set으로도 평가해보았다. 여러 발음으로 읽힐 수 있는 115개 문자에 대해서 문장을 생성해서 구성했는데 이때, 가장 흔한 발음은 제외하였다. 이렇게 함으로써 만약 모델이 가장 흔한 발음으로만 예측하도록 훈련된다면 성능이 안좋게 나오도록 유도했다. 결과를 보면 NLR이 베이스라인보다 우수한 성능을 보이지만 동철이음어를 문맥에 따라 구분하는 것은 여전히 어려운 과제임을 알 수 있다.
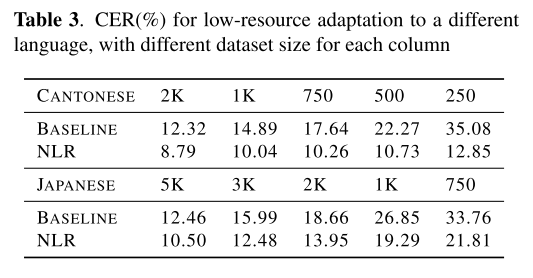
cantonese와 japanese의 적은 양의 데이터에 대해서 fine-tuning하는 실험도 해보았다. 2K cantonese 실험에서 NLR은 ground truth(8.45%)와 근접한 결과를 보여준다. 그리고 예상대로 두 언어 모두 샘플의 수가 적어질수록 성능이 하락하였다. NLR이 베이스라인보다 좋은 결과를 보여주긴 하지만 일본어는 대부분의 단어가 음독, 훈독이라는 두 가지 발음을 가지고 있기도 하고 한 문자(칸지)가 발음으로 표기될 때는 여러 문자(히라가나)로 표현되기도 하므로 중국어보다 학습하기가 어려워서 cantonese의 경우보다 낮은 성능이 기록된 걸 볼 수 있다. 그래도 표 3을 통해 lexicion-reading의 능력이 (소수의 fine-tuning 데이터와 함께) 다른 언어로도 전이될 수 있다는 결론을 내릴 수 있다.
Case Study
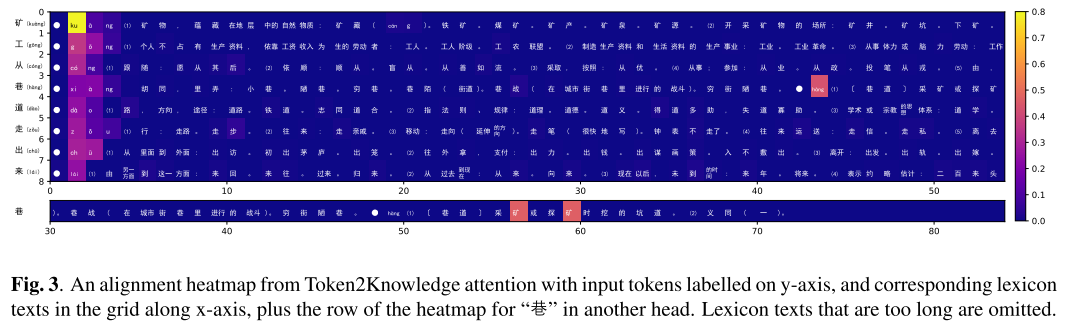
Token2Knowledge 어텐션을 히트맵으로 표현하면 그림 3과 같다. y축에 위치한 input character token에 대해서 관련된 lexicon을 보여주고 어텐션 값이 높은 텍스트가 붉은 색 계열로 나타나 있다. 관련 없는 pinyin은 무시되고 context에 맞는 pinyin에 높은 어텐션 값이 부여되고 있는 것을 알 수 있다.
특히 “巷”의 경우는 동철이음어인데 문맥 상에서 알맞은 pinyin인 “hang”으로 알맞게 읽히고 있는 것을 알 수 있는데 이는 그림 3에도 나타나 있듯이 다른 어텐션 헤드에서 “mine”을 뜻하는 “矿”에 높은 어텐션 값을 부여하고 있기 때문이라고 파악된다.
MOS 평가
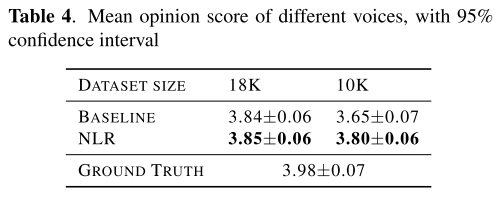
50개의 mandarin 문장을 임의로 골라서 MOS 평가를 진행했다. 문장 별로 20명의 평가자가 평가하여 산출된 결과가 표 4에 나타나 있다. NLR은 데이터가 많은 경우에는 베이스라인과 동등한 수준의 성능을 보여주지만, 데이터가 적어졌을 때 베이스라인을 능가함과 동시에 데이터가 풍부했을 때와 비슷한 수준의 음성 품질을 유지하고 있음을 알 수 있다.
의견
- Token2Knowledge 어텐션에서 key, value가 왜 각각 semantic, shallow 정보를 담아야 하는지에 대한 설명이 부족한 느낌이 든다.
- 데모 사이트에도 나와 있듯이 lexicon에 적혀 있는 pinyin을 수정하면 이미 학습된 모델이라 하더라도 최종 테스트 문장의 발음을 lexicon 기반으로 발음하게 되는 적용 사례가 인상적이다.




Leave a comment