
Parallel Tacotron
Elias, Isaac, et al. “Parallel Tacotron: Non-autoregressive and controllable TTS.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
들어가며
TTS는 대표적인 one-to-many mapping 문제로 입력으로 들어온 text에 해당하는 음성의 형태가 다양하게 존재할 수 있어서 자연스럽고 효율적으로 음성을 생성하는게 매우 까다롭다. 그래도 최근에 autoregressive한 방식에서 벗어나 Transformer 기반의 모델들이 TTS에 사용되면서 parallelizable해졌는데 여전히 한계점은 존재한다. autoregressive한 모델을 사용할 때는 디코딩 과정에서 이전 스텝의 멜 스펙트로그램과 텍스트가 컨텍스트로 쓰였기 때문에 출력 음성의 변화가 크지 않았지만, non-autoregressive한 방식에서는 컨텍스트를 주입할 수 있는 다른 방식을 찾아야만 한다. 예를 들어, FastSpeech는 모델이 입력으로 받은 text에 부족한 정보들을 채워주기 위해 F0, energy, pitch 등을 추가 정보로 주입한다. 그리고 음성 데이터로부터 운율과 같은 latent factor를 잡아낼 수 있도록 auxiliary representation을 추출하여 주입하는 시도들이 있는데 이는 스타일 토큰의 형태로 주입될 수도 있고, VAE의 latent vector로 제공되기도 한다.
본 논문에서는 Tacotron을 non-autoregressive하게 변형시킨 뒤 VAE-style residual encoder를 추가하여 이로부터 음성을 자연스럽게 합성하는 방안을 연구하고 평가한다.
핵심 요약
- Transformer의 self-attention 대신 Lightweight Conv(LConv)를 이용한 non-autoregressive 모델을 구현하여 추론속도를 향상시켰다.
- spectrogram decoder에 iterative loss를 사용해서 좀 더 자연스러운 음성을 합성할 수 있다.
- VAE-style residual encoder를 사용하여 모델에 추가 정보를 주입해주었고 이를 통해 자연스러운 음성을 합성할 수 있다.
모델 구조
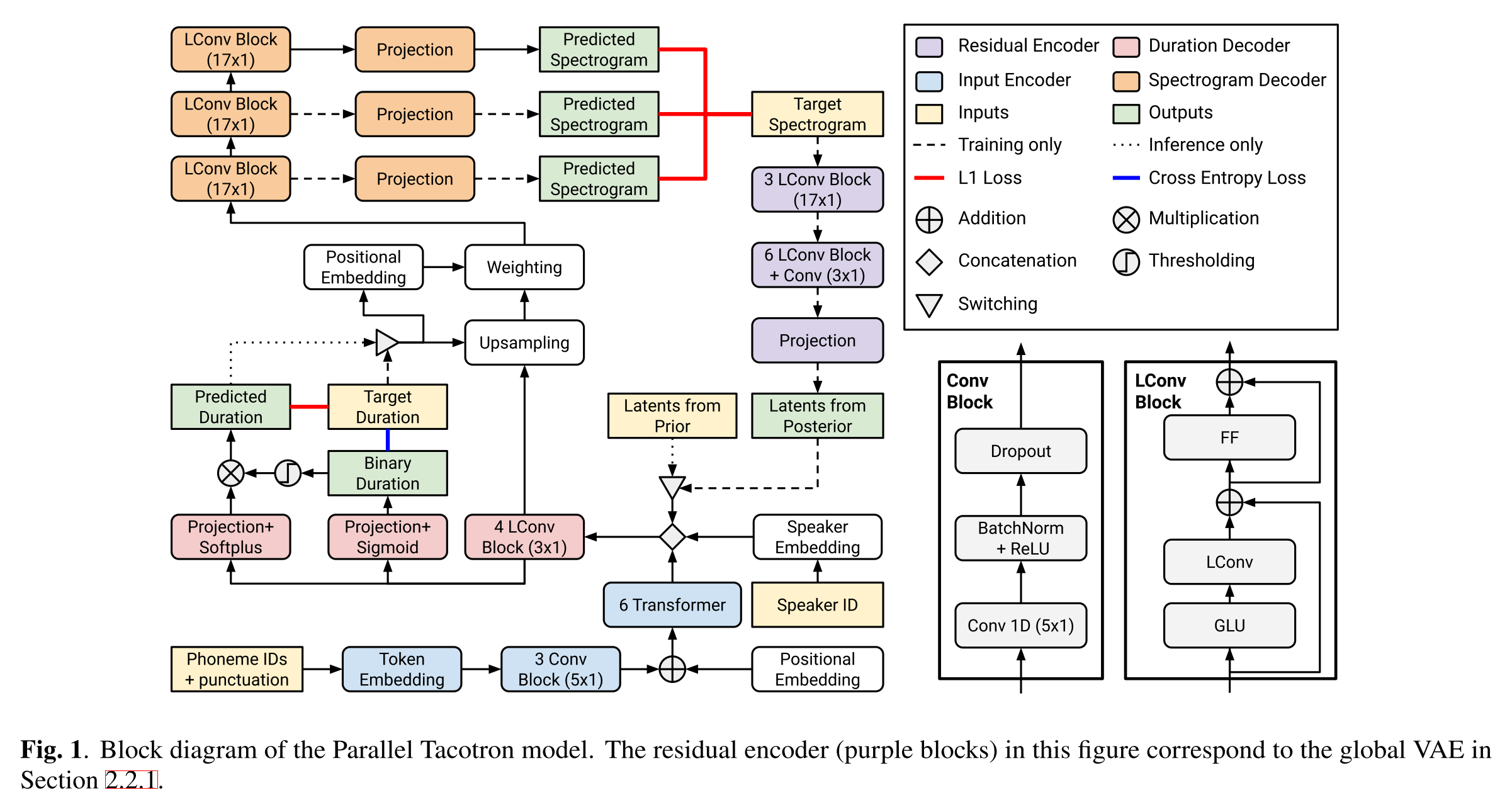
LConv는 본 모델에서 핵심적인 역할을 하고 있는 모듈로써, 고정된 context window를 가지고 있으면서 같은 가중치를 재사용하기 때문에, context가 지엽적인(기계번역과 같은 다른 언어 태스크와 달리) TTS에서 강점을 가지고 있다.
그리고 Residual Encoder가 VAE기반으로 설계되었는데 (즉, 이상적인 샘플링 함수인 posterior를 prior와 같아지도록 학습) Global VAE와 Phoneme-Level Fine-Grained VAE의 두 가지를 적용해본다(위의 그림은 Global VAE의 경우만 나타냄). Global VAE의 경우에는 residual encoder가 speaker specific learned prior를 추정하도록 GT 멜 스펙트로그램을 입력으로 받아서 posterior를 학습하게 되고 추론 시에는 speaker prior의 평균이 입력된다.
Phoneme-Level Fine-Grained VAE는 encoder의 output과 멜 스펙트로그램 사이의 어텐션을 계산해서 정렬하는 posterior network를 가지는데 이를 위해서 positional embedding과 speaker embedding이 멜 스펙트로그램의 프레임에 더해진다. 이렇게 posterior network를 학습시키는 한편, 추론에 사용하기 위한 LSTM을 별도로 학습시키는데 여기에도 positional embedding과 speaker embedding을 주입해주며 posterior mean과의 L2 loss로 학습을 진행하게 된다. 이때 계산된 loss 값은 posterior network에 영향을 주지 않는다.
input encoder와 residual encoder에서 나온 출력들이 합쳐져서 이제 duration decoder로 들어가게 되는데 여기서 phoneme별 duration을 예측하게 되고 GT duration은 external aligner인 HMM을 사용하여 구했다. 여기서는 입력을 두 가지 네트워크에 통과시키는데 하나는 projection+sigmoid로 duration을 zero/non-zero의 binary 값으로 표현하는 네트워크고, 다른 하나는 projection+softplus로 duration을 실수형으로 표현하는 네트워크다. 모델을 훈련시킬 때는 target duration을 spectrogram decoder에 전달해주면서 각각 cross entroy loss와 L1 loss를 이용해서 두 네트워크를 학습시키고 추론 시에는 예측한 실수형 duration을 전달해준다.
다음으로 spectrogram decoder으로 가기 전에 phoneme duration에 맞춰서 duration decoder의 input을 upsampling하는 과정을 거치고 이때 3가지의 positional embedding((1) Transformer-style sinusoidal embedding of a frame position within a phoneme, (2) Transformer-style sinusoidal embedding of phoneme duration, (3) Fractional progression of a frame in a phoneme)도 더해준다.
spectrogram decoder에서는 LConv를 여러 번 통과시키면서 멜 스펙트로그램을 iterative하게 예측하고 각각에 대한 L1 loss를 합하여 최종 loss에 더해준다.
실험 결과
Iterative loss의 효과
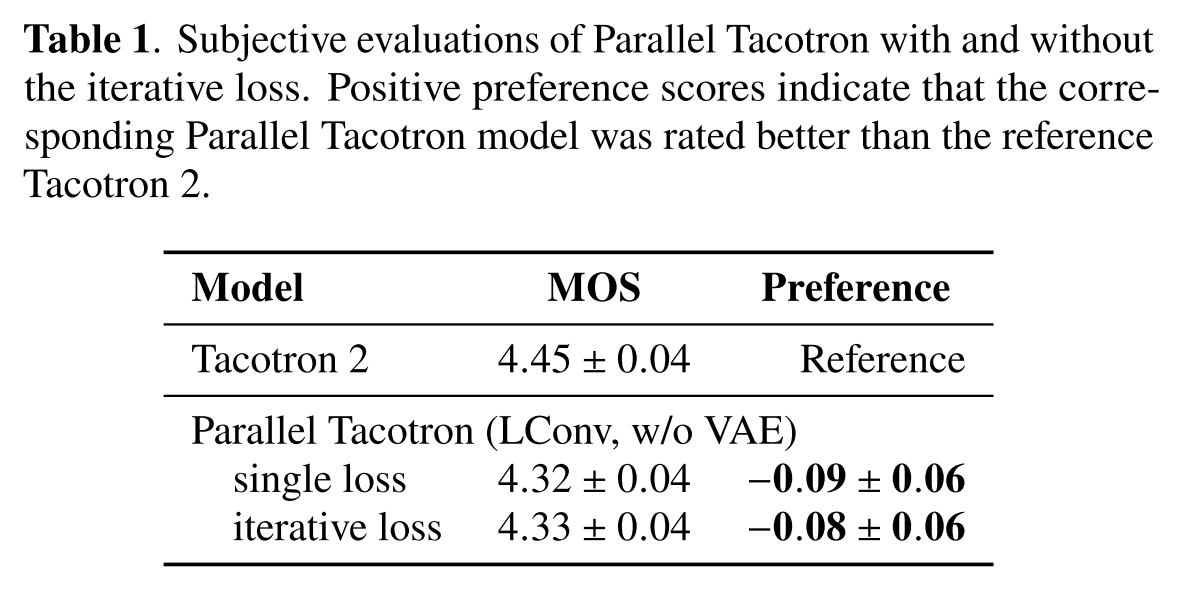
표 1을 봤을 때 baseline인 Tacotron 2와 MOS, preference 모두 비슷한데 Parallel Tacotron에서 iterative loss를 사용한 경우가 성능이 조금 더 좋다.
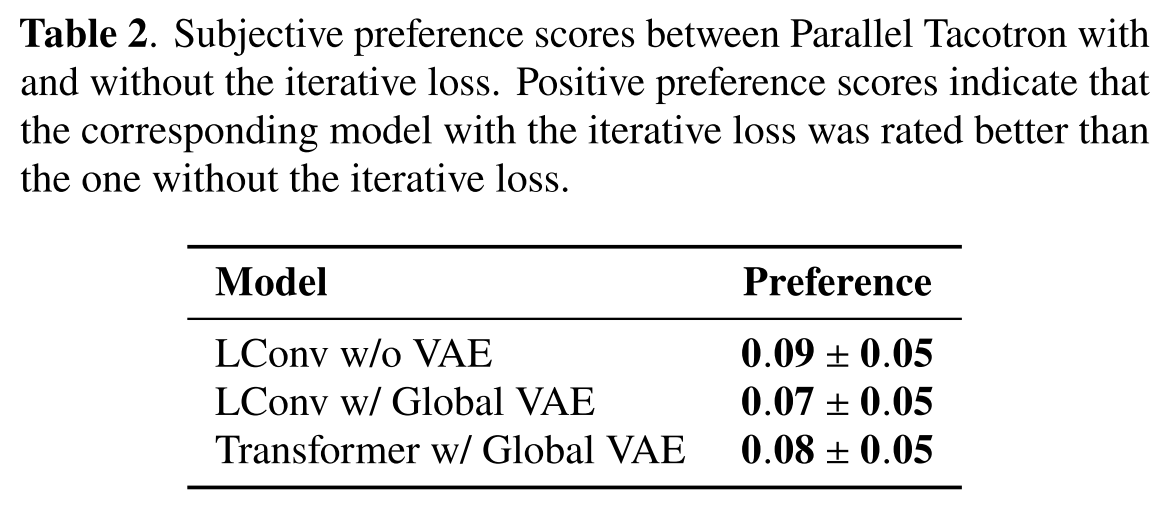
표 2에서 각 모델에 대해 iterative loss를 쓴 경우가 preference가 더 좋았다.
VAE의 효과
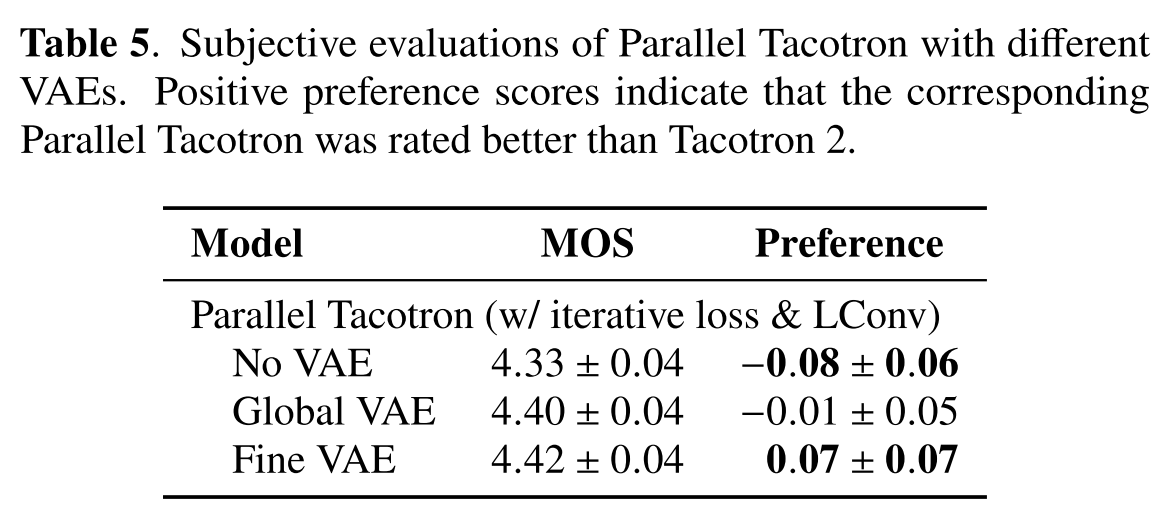
VAE를 안 쓴 경우 MOS와 preference가 심각하게 안좋아졌으나 Global VAE를 쓰면 Tacotron 2와 비슷한 수준으로 향상되고, Fine VAE를 쓸 경우에는 Tacotron 2를 능가하면서 합성된 음성의 자연스러움이 크게 향상된다.
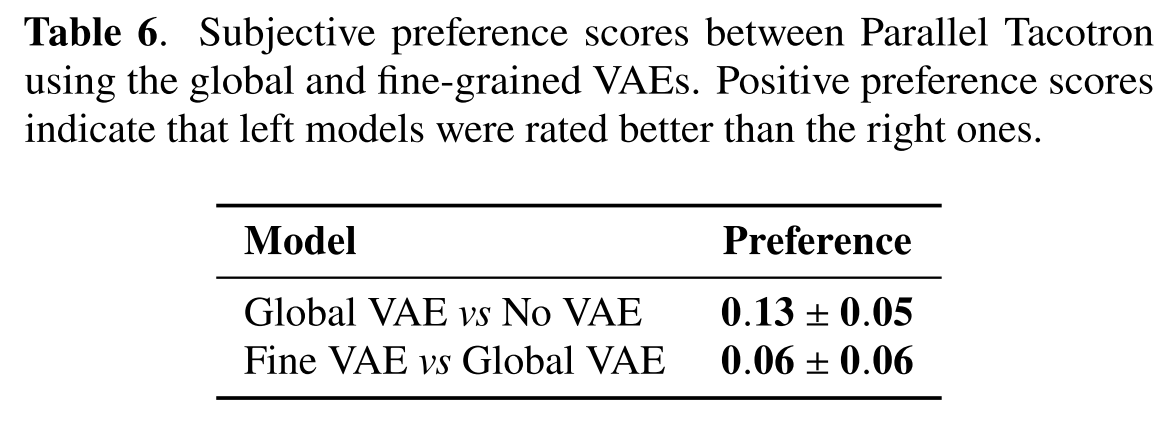
표 6의 일대일 비교를 통해 No VAE보단 Global VAE의 음성이 자연스럽고, Global VAE보단 Fine VAE의 음성이 자연스럽다는 것을 알 수 있다.
LConv의 효과
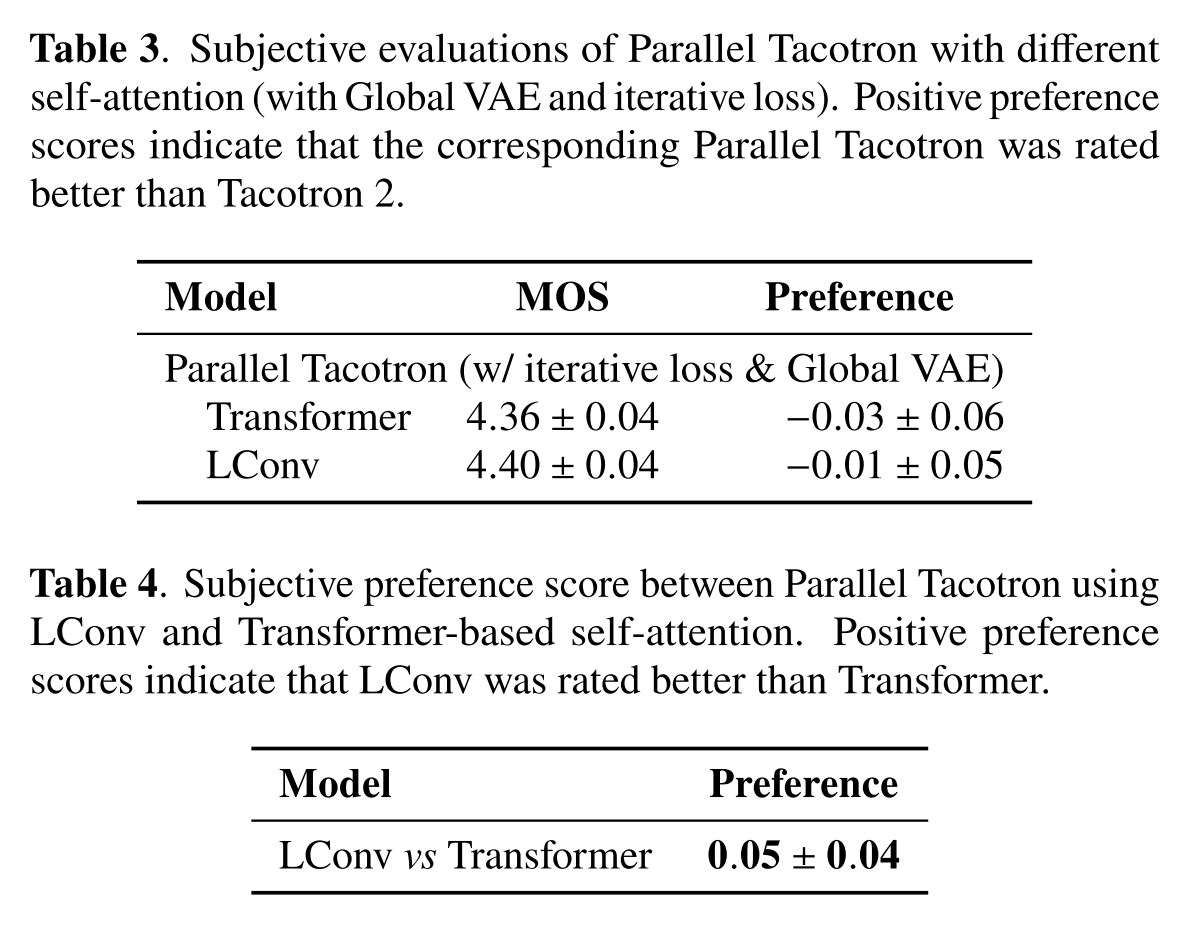
마지막으로 LConv의 효과를 확인한다. 우선 Parallel Tacotron에서 LConv와 Transformer의 self-attention을 사용한 경우 모두 Tacotron 2와 비슷한 성능을 기록했다. 하지만 Parallel Tacotron 내에서 비교를 해본다면 LConv의 preference 더 높게 기록되었기 때문에 LConv가 더 자연스러운 음성을 합성하게 도와준다고 해석할 수 있다.
실제 음성과의 품질 비교

지금까지는 baseline 모델의 음성과 비교를 하였다면 이제 실제 테스트셋 음성과 합성된 음성 간의 preference를 비교한다. 0에 가까울수록 합성 음성이 더 실제와 같다는 뜻인데 Parallel Tacotron에서 Fine VAE를 쓴 경우가 가장 높게 기록되었다.
추론 속도 비교
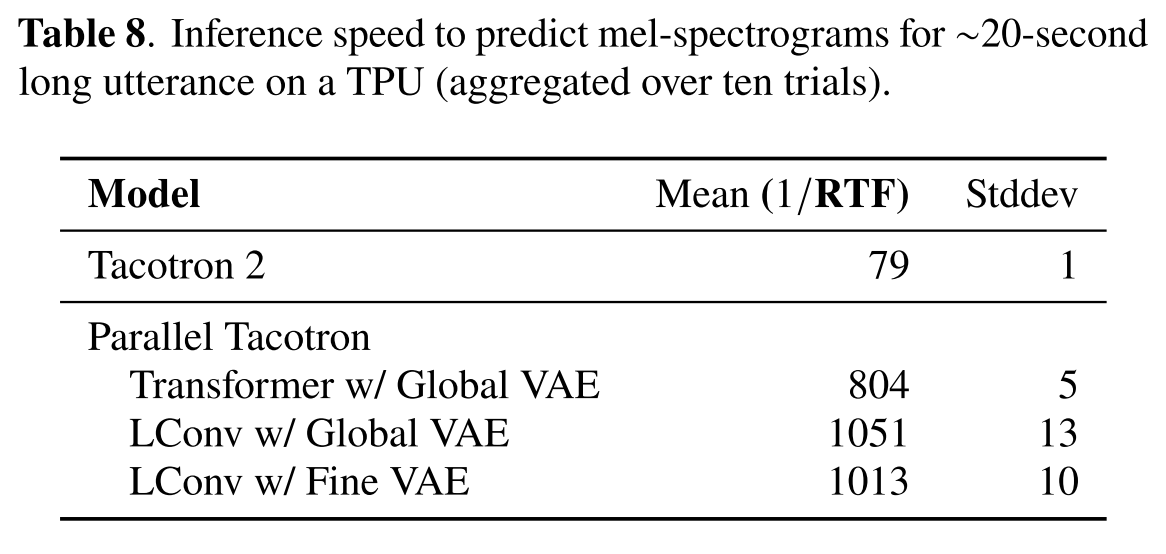
확실히 non-autoregressive한 모델인만큼 Tacotron 2모델보다 기본적으로 10배 이상 빠른 것을 알 수 있는데 여기에서 그치지 않고 LConv를 사용하면 속도가 더 향상되는 것을 확인할 수 있다. 그리고 음성의 자연스러움을 유지하면서 모델의 크기와 추론 속도간 trade-off 실험을 많이 진행하지 않았기 때문에 앞으로 추론 속도는 더 개선될 여지가 있다고 한다.
의견
- speaker별 prior를 어떻게 학습했는지에 대한 설명이 없어서 아쉽다.
- 비교실험을 많이 진행한 것은 좋았으나 baseline으로 Tacotron 2만 쓰기보다 다른 non-autoregressive 모델들을 추가해서 실험했다면 더 설득력 있는 논문이 되었을 것 같다.




Leave a comment