
Parallel Tacotron 2
Elias, Isaac, et al. “Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling.” arXiv preprint arXiv:2103.14574 (2021).
들어가며
Parallel Tacotron에서 VAE 기반의 non-autoregressive한 TTS가 가능하다는 것을 보였지만, phoneme의 duration을 외부의 aligner를 통해 계산하고 있는 단점이 있다. 외부의 aligner를 사용하면 모델의 훈련 과정이 복잡해지고 외부 aligner 성능에 TTS의 성능이 민감하게 반응하기 때문에 여러 문제점을 초래할 수 있기 때문이다. 그래서 Parallel Tacotron 2에서는 자체적으로 개발한 duration model을 Parallel Tacotron 구조에 포함시키고 학습이 가능하도록 fully differentiable하게 만들었다. 그리고 예측된 duration에 맞게 upsampling하는 메커니즘을 추가하고 기존의 iterative reconstruction loss를 수정하여 duration model과의 시너지를 높였다.
핵심 요약
- token의 duration을 구하고 token-frame간의 alignment를 추출하기 위해서 differentiable duration modeling과 learned upsampling의 조합을 사용한다.
- Soft-DTW를 사용하여 reconstruction loss를 계산하기 때문에 target과 predicted frame의 length가 달라도 상관이 없다. 즉, duration model에서 계산한 duration의 합이 꼭 멜 스펙트로그램의 프레임 수와 일치하지 않아도 된다.
- teacher forcing을 없앰으로써 음성 합성 품질이 향상되었고, 특정 token의 duration을 조절해 주었을 때 생성된 음성(멜)이 알맞게 발음되는 것을 확인하면서 token-frame간 alignment가 token의 경계에 맞게 학습된 것을 증명한다.
모델 구조
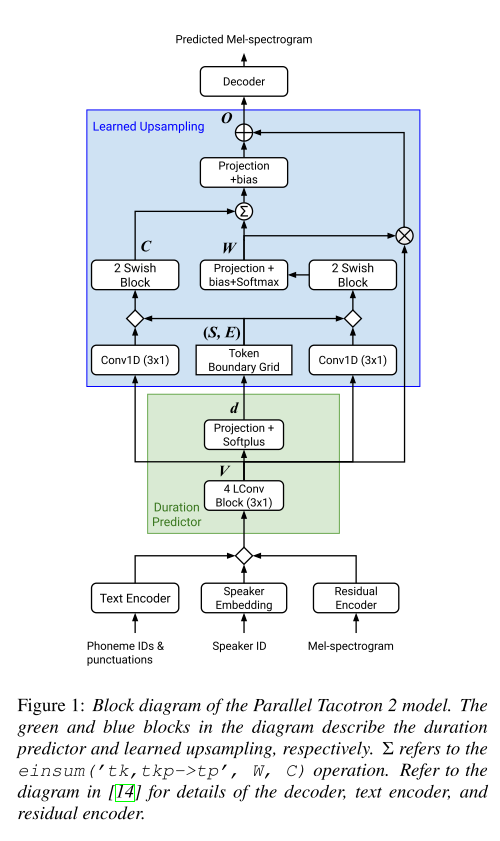
Differentiable Duration Modeling & Upsampling
Parallel Tacotron에서는 인코더의 출력을 token duration에 맞게 upsample하기 위해 length regulator를 사용하는데 이때 정수형의 duration을 필요로 하기 때문에 실수형의 duration을 올림한다.
이렇게 올림하는 과정에는 두 가지 문제점이 존재한다.
첫째, 올림 오차가 모델에 주입된다.
둘째, 올림 과정은 미분 불가능하기 때문에 오차에 대한 그래디언트가 전파될 수 없다.
그리고 훈련 과정에서 target duration을 알려주며 teacher forcing을 사용하는데 이는 훈련과 추론 과정의 차이를 유발할 뿐더러 L1 loss를 통해 계산되는 reconstruction loss의 gradient가 duration prediction 과정에 영향을 미칠 수 없도록 한다. 그렇기 때문에 reconstruction loss를 최소화시키기 위해서 duration predictor와 decoder를 동시에 최적화시키는 것이 불가능해진다.
따라서 Parallel Tacotron 2에서는 위의 문제를 해결하기 위해 오차의 그래디언트가 duration modeling까지 전파될 수 있는 구조를 제시한다. 이를 위해 duration과 모든 연산 과정이 실수 도메인에서 다루어지고, teacher forcing을 없애서 네트워크가 token-frame간의 맵핑을 배울 수 있도록 유도한다.
duration predictor는 총 target frame의 duration과 예측한 duration의 총합의 차이를 loss로 학습이 되고, 인코딩된 V를 O로 upsample하기 위해 upsample module에서 duration으로부터 얻어낸 정보를 바탕으로 attention 계산을 거치게 된다.
Reconstruction Loss using Soft-DTW
예측된 멜 스펙트로그램과 실제 멜 스펙트로그램의 길이가 다를 수 있기 때문에 L1 loss를 사용하지 못한다. 그러므로 DTW(Dynamic Time Warping)을 미분 가능하도록 수정한 Soft-DTW를 loss로 사용한다. Parallel Tacotron의 디코더에서 그랬던 것처럼 iterative한 예측을 수행하기 때문에 Soft-DTW 또한 각 예측에 모두 적용된다.
Fine-grained Token Level VAE
Residual encoder에서는 fine-grained token-level VAE를 사용했다. 학습 시에는 VAE로부터 나온 posterior latent vector를 사용하고, 추론 시에는 prior의 평균인 zero vector를 사용한다.
실험 결과
음성 합성 품질
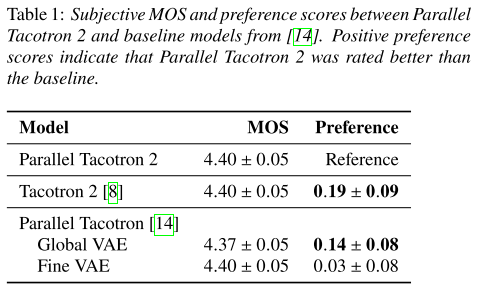
베이스라인 모델인 Tacotron 2나 Parallel Tacotron보다 음성의 preference가 높다.
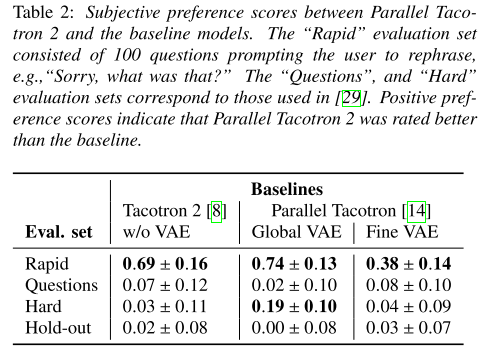
다양한 evaluation set을 가져와서 테스트 해봤을 때도 Parallel Tacotron 2가 우세한 것을 알 수 있다.
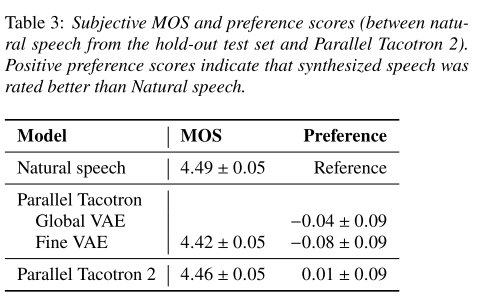
실제 음성과 비교해봤을 때 Parallel Tacotron 2의 preference가 미세하게 높을 정도로 실제와 유사한 음성을 합성한다.
Duration 조절
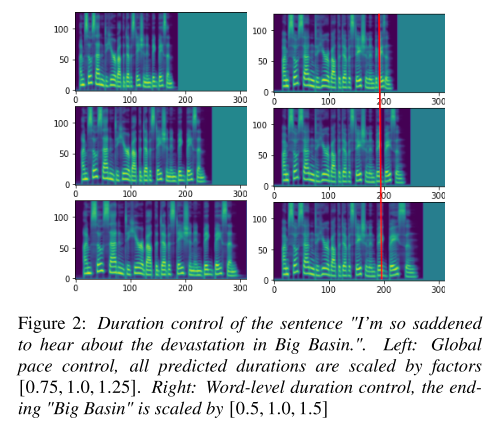
duration을 전체적으로 스케일링하거나 일부를 스케일링 했을 때 멜 스펙트로그램의 변화를 나타낸다. 의도했던대로 특정 token의 발화 속도만 변하는 것을 보아 token-frame alignment가 잘 이루어진 것을 알 수 있다.
의견
-
학습 시에는 타겟 스펙트로그램의 길이를 아니까 W의 차원인 T를 결정할 수 있는데 추론 시에는 T가 어떻게 결정되는지 궁금하다(이로부터 predicted 멜의 길이가 결정되기 때문).
→ 아마도 predicted duration의 합이 T가 될 것이다!
- 길이가 다른 시계열 데이터의 차이를 구하는 DTW를 TTS에 적용한 아이디어가 좋았다.
- upsampling 모듈에서 attention matrix를 구하는 방식에 변화를 줘서 성능을 더 높일 여지가 있는 것 같다.

Leave a comment