
Parallel WaveGAN
Yamamoto, Ryuichi, Eunwoo Song, and Jae-Min Kim. “Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
들어가며
기존의 TTS는 autoregressive 모델을 사용하거나 teacher-student framework에 기반하여 음성을 합성하는데 각각 추론 속도가 느리거나 너무 복잡하다는 단점을 안고 있다. 그래서 본 논문에서는 non-autoregressive WaveNet에 기반해서 multi-resoluton STFT loss와 adversarial loss를 최소화 시키는 GAN 네트워크를 이용하여 실제와 같은 음성을 합성할 수 있는 Parallel WaveGAN을 제시한다.
핵심 요약
- multi-resolution STFT loss와 adversarial loss를 동시에 최적화하는 joint training 기법을 제안한다.
- teacher-student 구조 없이 학습 가능한 덕분에 학습과 추론 시간 모두 단축시킬 수 있다(베이스라인으로 ClariNet을 사용한다).
- Transformer 기반의 acoustic 모델을 결합하여 TTS를 수행했을 때 베이스라인보다 높은 MOS를 기록했다.
모델 구조
GAN이므로 생성자와 판별자로 이루어져 있다. 생성자는 WaveNet 기반의 모델인데 기존의 WaveNet과는 3가지 차별점이 있다.
- 인과 합성곱(causal convolution) 대신 비인과 합성곱(non-causal convolution)을 사용한다.
- 모델의 입력은 가우스 분포에서 추출한 랜덤 노이즈와 멜 스펙트로그램과 같은 보조 피쳐이다.
- 학습과 추론 단계에서 비회귀적인 방식을 사용한다.
판별자도 생성자와 비슷하게 비인과 합성곱과 leaky ReLU 활성화 함수의 조합으로 구성되어 있다.
학습 방식
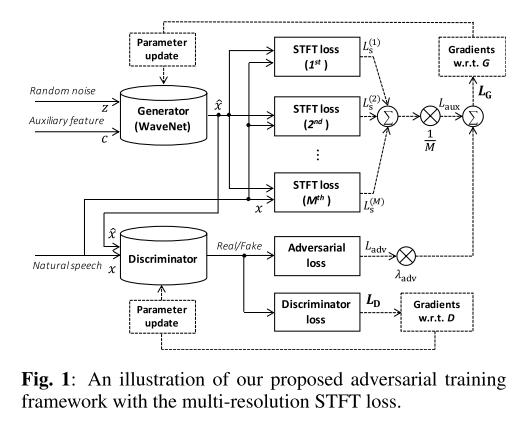
기본적인 GAN 학습 방식에 STFT loss를 보조 손실 함수로 추가한 형태이다. 여기서 STFT loss는 STFT 파라미터를 다양하게 조정해가면서 구한 뒤 합친 다중 해상도 손실 함수(multi-resolution loss)이며 GAN의 학습이 안정적이고 효율적으로 이루어지도록 돕는다고 한다.
손실 함수
-
적대적 손실 함수(adversarial loss)
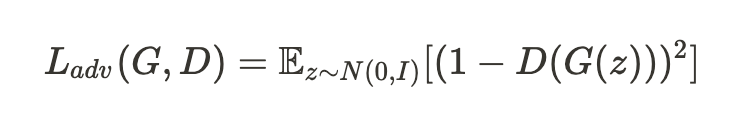
- 보조 손실 함수(auxiliary loss)
-
single STFT loss
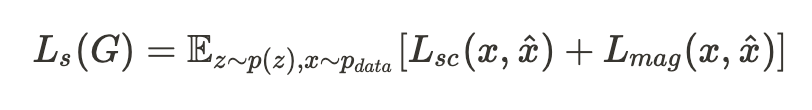
- spectral convergence & log STFT magnitude loss
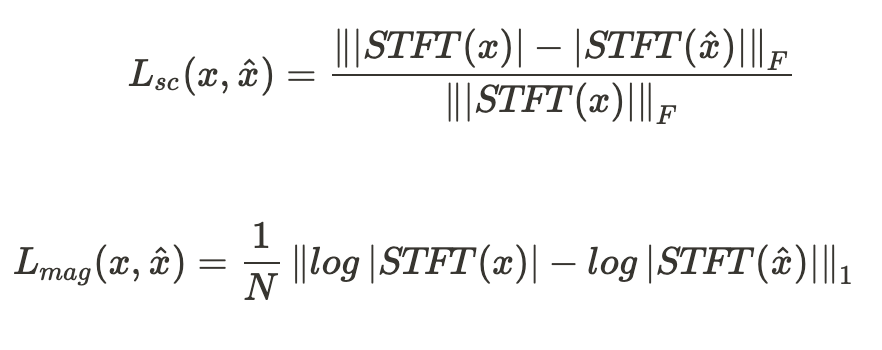
- 다중 해상도 손실 함수
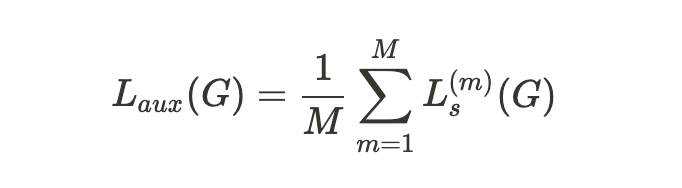
-
- 최종 손실 함수 형태
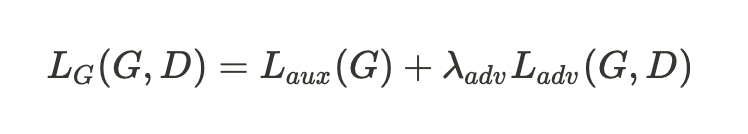
의견
- 샘플을 청취한 결과 오디오 샘플을 그대로 복원해 내는 태스크에서는 WaveNet이나 ClariNet보다 잡음이 미세하게 더 많이 들리지만, TTS 태스크에서는 우열을 가리기 힘들만큼 좋은 품질의 음성을 합성해내는 것을 알 수 있다. 즉, 뉴럴 보코더 중 합성 품질이 가장 좋다고 여겨지는 WaveNet과 비슷한 음질을 보여준다고 할 수 있겠으나 TTS 태스크에서는 Transformer TTS 모델이 멜 스펙트로그램을 만들어준 것이기 때문에 보코더인 Parallel WaveGAN보다는 Transformer TTS 모델의 영향이 더 컸던 것은 아닐지 의구심이 든다.
- 성능이 베이스라인 모델들과 비슷하다 하더라도 파라미터 수와 학습 시간을 크게 줄였기 때문에 활용할 가치는 충분하다고 생각한다.




Leave a comment