
Parler-TTS
Lyth, Dan, and Simon King. “Natural language guidance of high-fidelity text-to-speech with synthetic annotations.” arXiv preprint arXiv:2402.01912 (2024).
들어가며
Large-scale 데이터셋으로 학습한 TTS 모델들이 훌륭한 in-context learning 능력과 자연스러움을 보여주고 있지만, 화자 아이덴티티나 스타일 조절은 레퍼런스 오디오에 기반하기 때문에 창조성에 한계가 있다. 한편, natural language prompting이 직관적인 조절 방법을 제시하는 동시에 효과를 입증했으나 human-labeled description에 의존해야 한다는 점이 large-scale로 확장하는 데 장애물이 되고 있다. 본 논문에서는 앞서 언급한 두 가지 접근 방식의 격차를 메우기 위한 방법을 제시하고 있으며, 이 논문의 방법을 huggingface 팀에서 재생산시킨 것이 바로 Parler-TTS 이다.
핵심 요약
- 45000 시간 데이터셋을 gender, accent, speaking rate, pitch, recording condition 등의 속성을 포함하여 효과적으로 라벨링하는 방법을 제안한다.
- 라벨링한 대용량 음성 데이터로 speech language model을 학습시키고 여러 속성들을 독립적으로 조절할 수 있다는 것을 보인다. 또한 학습때 보지 못했던 조합으로 화자 아이덴티티와 스타일을 만들어내는 것이 가능하다.
- 학습 데이터에 최소한의 고품질 오디오 (약 1%)를 포함시키고 SOTA 오디오 코덱 모델을 사용하면 매우 고품질인 오디오를 생성할 수 있다.
데이터셋 제작
- 메타데이터 수집
- MLS, LibriTTS-R을 사용하며 두 데이터셋 모두 transcription을 기본적으로 제공한다.
- gender: 데이터셋 안에 예측 모델로 생성된 gender 라벨이 포함되어 있다.
- accent: EdAcc, VCTK, VoxPopuli 데이터셋을 이용해서 accent classifier를 학습시켜 사용하고 총 53개 accent를 커버한다.
- recording quality: 우회적인 지표로 signal-to-noise ratio (SNR)와 C50의 예측값을 사용한다. 두 feature 모두 Brouhaha를 사용해 계산한다.
- pitch: pitch contour는 PENN을 사용해 계산하고 speaker-level 평균과 utterance-level 표준편차를 기록한다. speaker-level 평균은 성별에 따른 화자의 상대적인 pitch를 라벨링하기 위함이며, utterance-level 표준편차는 각 발화가 얼마나 다이나믹한지 라벨링하기 위함이다.
- speaking rate: 포님 개수를 발화 시간으로 나누어서 계산한다.
- 메타데이터 준비
- 메타데이터 수집이 끝났으면 이를 natural language description으로 변경하는 작업을 진행한다.
- 이산적인 라벨인 gender와 accent는 추가적인 처리 없이 바로 키워드로 사용될 수 있다.
- 그러나 pitch, speaking rate, SNR, C50은 연속적인 값으로 이산적인 카테고리에 매핑하는 작업이 필요하다. 그 방법으로 저자들은 전체 데이터셋에서 각 변수들의 분포를 확인한 뒤, binning을 통해 7가지 카테고리로 나눈뒤 짧은 어구로 매핑시키는 방식을 사용한다. 예를 들어, speaking rate의 경우, “very fast”, “quite fast”, “fairly slowly”로 나누는 식이다.
- 또한, SNR과 C50이 모두 가장 높거나 낮은 bin에 속하는 경우에는 “very good recording”, “very bad recording”이라는 라벨을 추가로 달아주었다.
-
마지막으로 일반화 성능을 올릴 수 있게 위에서 생성된 키워드들을 language model (Stable Beluga)에 통과시켜 전체 description을 완성한다.
["female", "Hungarian", "slightly roomy sounding", "fairly noisy", "quite monotone", "fairly low pitch", "very slowly"] => "a woman with a deep voice speaking slowly and somewhat monotonously with a Hungarian accent in an echoey room with background noise"
모델 구조
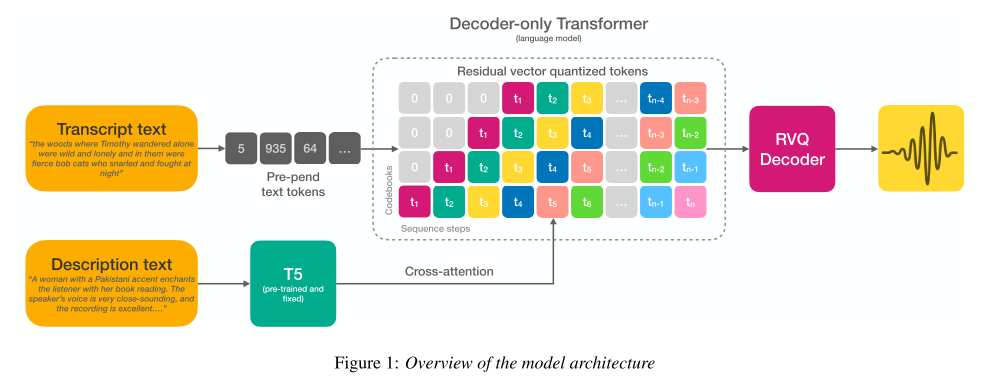
오디오 생성 모델인 AudioGen 모델을 사용하여 TTS에 맞게 수정하였다. TTS에 맞게 만들기 위하여 transcript 컨디셔닝 시에 word dropout을 제거하고, 초기 실험을 거쳐, transcript는 pre-pending, description은 cross-attention으로 컨디셔닝하는 방법을 채택했다.
이전의 연구들과는 달리, 모델에 어떤 형태의 오디오나 스피커 임베딩도 제공해주지 않고 오로지 transcript와 description에만 모델이 의존할 수 있도록 유도한다. 오디오 코덱 모델로는 Descript Audio Codec (DAC)를 사용한다.
실험 결과
테스트셋은 MLS와 LibriTTS-R에서 마련했는데 accent의 경우만 Rainbow Passage, Comma Gets a Cure, Please Call Stella를 사용해 테스트셋을 만들었다.
gender 컨트롤을 테스트하기 위해 사전 학습된 gender classifier를 사용하였고, 테스트셋에서 94%의 정확도를 기록했다.
accent도 사전에 학습해둔 accent classifier를 통해 테스트를 진행했고, 68%라는 낮은 정확도를 기록했다. 저자들은 라벨의 노이즈와 학습 데이터셋의 accent 분포 불균형 때문에 이런 문제가 발생했을 것으로 추측한다.
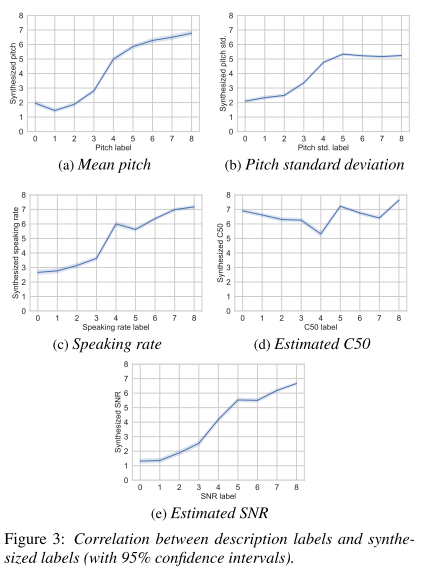
그 외 속성들은 테스트셋에 대한 실제 라벨과 예측된 값을 비교하는 방식으로 성능을 측정한다. 그림 3을 통해 알 수 있듯이, C50을 빼고 나머지는 실제 라벨과 예측 라벨이 비례 관계를 따르면서 양호한 성능을 보여준다.
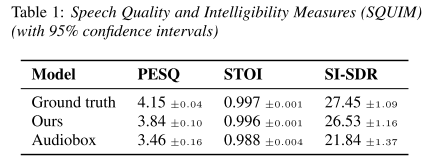
Torchaudio SQUIM을 사용해 음성의 품질을 평가해보았을 때도, 본 논문에서 제안하는 모델이 Audiobox를 능가하는 성능을 보여준다.
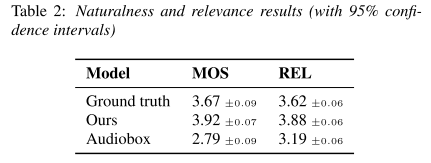
자원 봉사자들을 모집해 청취 테스트를 수행했을 때도 Audiobox를 능가하며, 심지어 GT도 크게 앞서는 것을 보여준다. 여기서 REL은 relevance의 줄임말로 음성이 description을 얼마나 충실하게 반영했는지를 평가하는 척도이다.
의견
- 제로샷 TTS의 한계를 극복할 수 있는 방법으로 가장 간결하고 효과적인 접근 방식이라고 생각한다.
- 자연어 prompt 기반 TTS 연구가 더 확장되어 레퍼런스 오디오나 이미지를 적절히 활용하는 연구들도 많이 나와주면 좋겠다.
- 가상인간 음성합성 서비스를 위해 베이스라인으로 쓰일 수 있겠다.

Leave a comment