
Should you use a probabilistic duration model in TTS? Probably! Especially for spontaneous speech
Mehta, Shivam, et al. “Should you use a probabilistic duration model in TTS? Probably! Especially for spontaneous speech.” arXiv preprint arXiv:2406.05401 (2024).
들어가며
TTS 연구에서 duration modelling은 합성된 음성의 운율을 조절하는 중요한 역할을 한다. 대부분의 NAR TTS는 duration modelling을 회귀 문제로 간주하기 때문에 같은 문장이면 동일한 타이밍을 가지고 발화되는 특성이 있다. 이를 해결하기 위하여 probabilistic model을 활용하는 방법이 제안되었지만, 어떤 것이 더 좋은지에 대한 의견이 아직도 분분한 상황이다. 그러나 이 논문의 저자들은 기존의 연구들이 오디오북 데이터셋과 같은 read aloud 데이터로만 실험을 진행하고, 현실에서 더 일반적이라고 할 수 있는 spontaneous 데이터는 무시되었다는 것을 지적한다. 구체적으로 NAR TTS 아키텍처 유형과 음성 데이터셋 유형에 따라 어떤 duration modelling이 효과적인지 실험을 통해 밝혀낸다.
핵심 요약
- 전통적인 regression-based (deterministic) duration modelling과 flow matching을 사용한 probabilistic duration modelling을 비교한다.
- regression-based TTS 모델은 stochastic duration modelling으로 효과를 보지 못하지만, probabilistic TTS 모델은 성능 향상을 이룩할 수 있다.
- deterministic과 probabilistic duration modelling 의 차이는 spontaneous 음성 데이터셋으로 학습할 때 가장 두드러졌고, LJ Speech 데이터셋에서는 거의 없었다. 이는 현대의 TTS 시스템이 자연스러운 음성의 복잡성을 처리하는 방법에 대한 더 나은 벤치마크의 필요성을 강조한다.
모델 구조
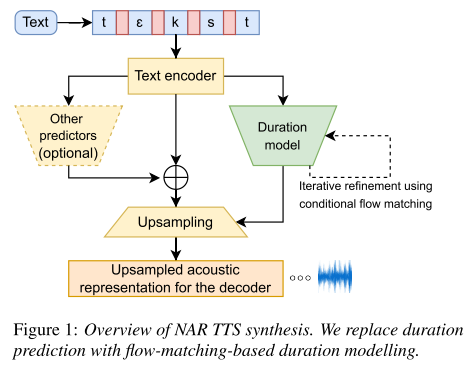
모델 구조는 위와 같이 NAR TTS에서 MSE-based duration predictor를 conditional flow matching predictor로 바꾼 형태이다. 구체적으로 Matcha-TTS에서 사용하는 OT-CFM을 사용한다. 즉, flow matching을 통해 log-domain reference duration의 확률 분포를 학습하게 된다.
실험 결과
학습 데이터셋과 평가 모델은 아래와 같이 선정되었다.
- 데이터셋
- read-speech dataset
- LJ Speech (LJ)
- RyanSpeech (RS)
- spontaneous-speech dataset
- Trinity Speech-Gesture Dataset II (TSGD2)
- AptSpeech (AptS)
- read-speech dataset
- 평가 모델
- FastSpeech 2 (FS2): deterministic acoustic model
- Matcha-TTS (Matcha): probabilistic acoustic model
- VITS (VITS): end-to-end probabilistic TTS model
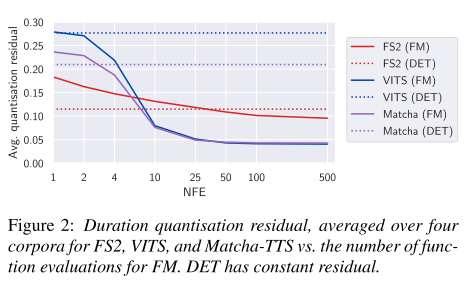
그림 2는 NFE에 따라 duration model이 얼마나 정확하게 duration을 예측하는지 보여주는 그래프이다. deterministic duration predictor (DET)를 사용한 경우는 당연히 NFE에 따른 값 차이가 없지만 FS2가 가장 정확하게 예측하는 것을 알 수 있다. OT-CFM-based duration predictor (FM)를 사용한 경우는 NFE가 증가할수록 duration error가 줄어드는 경향을 보이는데 VITS와 Matcha는 큰 폭으로 감소하지만, FS2에서는 상대적으로 변화가 작고 10 NFE부터는 FS2가 가장 큰 에러를 보인다. 즉, DET가 FS2에서는 효과적이지 않다고 보여진다.
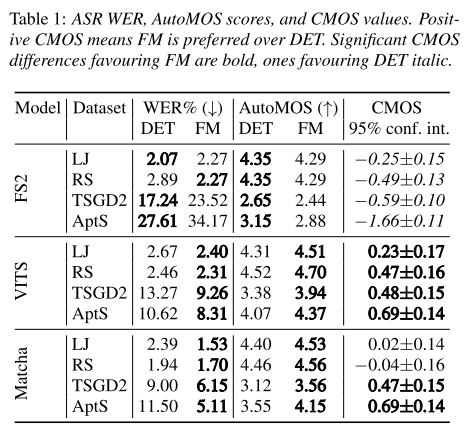
또한, 합성된 오디오를 사용해서 objective 및 subjective 평가를 진행한 결과도 마찬가지로 FS2에서 FM을 사용한 경우보다 DET를 사용했을 때 성능이 더 좋다는 것을 보여준다. 그러나 VITS와 Matcha는 모든 데이터셋에서 FM을 사용한 경우가 성능이 더 좋았으며, 특히 spontaneous-speech 데이터셋에서 성능 향상이 두드러진다.
의견
- 혁신적인 TTS 모델을 제안하는 것은 아니지만 기존 연구들의 헛점을 잘 파고들었다고 생각한다.
- spontaneous-speech에 대한 연구가 많이 없어서 아쉬웠는데, 이 논문에서 제안하는 spontaneous 데이터셋이 앞으로 벤치마크로 자주 활용되었으면 한다.

Leave a comment