
Seq2Seq G2P
Yao, Kaisheng, and Geoffrey Zweig. “Sequence-to-sequence neural net models for grapheme-to-phoneme conversion.” arXiv preprint arXiv:1506.00196 (2015).
들어가며
다양한 NLP task에서 side-conditioned neural net이라 불리는 sequence-to-sequence(seq2seq) 모델이 높은 성능을 보여주면서 각광을 받고 있다. 특히, machine translation, image captioning, language modeling, 그리고 language understanding task에서 많이 사용되고 state-of-the-art(SOTA)를 기록하면서 모델의 단순함과 강력한 성능에 매료된 연구자들이 많다.
그동안 seq2seq이 적용되었던 task들은 입력 단어 셋의 크기가 크기 때문에 대부분의 단어들은 데이터 상에 존재하는 적은 빈도의 경우만으로 통계치가 추정되어야 하는 단점이 있었는데 여기에 neural net이 더해지면서 continuous-space 표현이 가능해져 문제가 해결된 사례이다.
반면에 NLP task 중 하나인 grapheme을 phoneme으로 치환하는 문제(G2P)는 전체 문자와 음소의 차원이 비교적 작기 때문에 n-gram 모델로도 충분히 학습이 가능했고 이 모델들의 성능이 SOTA로 기록되어 있다. 그래서 이 논문은 G2P에 seq2seq 모델을 사용해 볼 수는 있지만 machine translation이나 image captioning과 같은 task를 평가할 때처럼 관용적인 metric(BLEU)을 사용하는 것이 아니라 음소의 순서가 정확해야 하는 G2P만의 까다로움이 있는 만큼, seq2seq을 통해서도 신뢰하고 사용할만한 수준의 모델을 만들 수 있는지 알아본다.
핵심 요약
- seq2seq 모델은 n-gram model의 성능에 약간 뒤쳐지지만 거의 맞먹는 결과를 보이는데 전통적인 G2P 접근 방식에서 사용했던 alignment가 필요없으므로 큰 이점이 있다.
- uni-directional LSTM을 사용할 때는 window size가 중요하다.
- alignment와 bi-directional LSTM 모델을 함께 사용하여 SOTA를 기록하였다.
모델 구조
Encoder-Decoder LSTM(Seq2Seq)
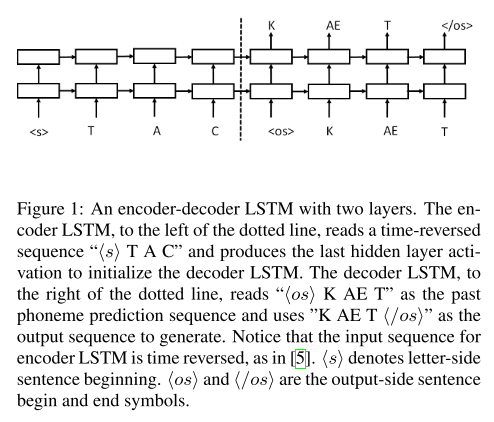
encoder와 decoder에 LSTM을 사용한 seq2seq 구조다. grapheme 입력이 들어갈 때는 시퀀스의 앞에 <s> 토큰을 붙여주고 phoneme 시퀀스가 시작될 때는 <os>, 끝날 때는 < /os>를 사용했다. encoder의 입력을 넣어줄 때 역순으로 넣어주는 트릭을 사용했다. decoding 시에는 beam search decoder를 사용하여 posterior probability가 가장 높은 시퀀스를 선택한다.
Uni-directional LSTM
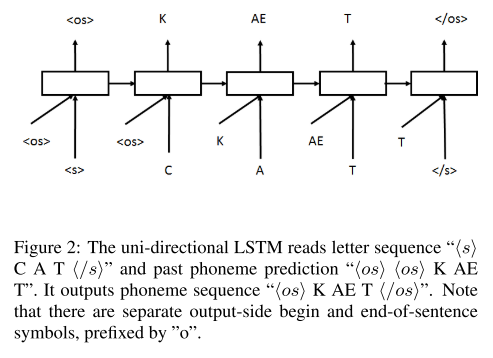
alignment를 사용하며, grapheme과 이전 시점의 phoneme 예측을 입력으로 받는 uni-directional LSTM 모델이다.
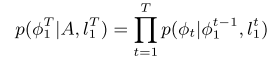
입력 시퀀스, 출력 시퀀스, alignment가 주어졌을 때 위와 같은 posterior probability를 최대화 하는 방향으로 모델이 학습된다.
Bi-directional LSTM
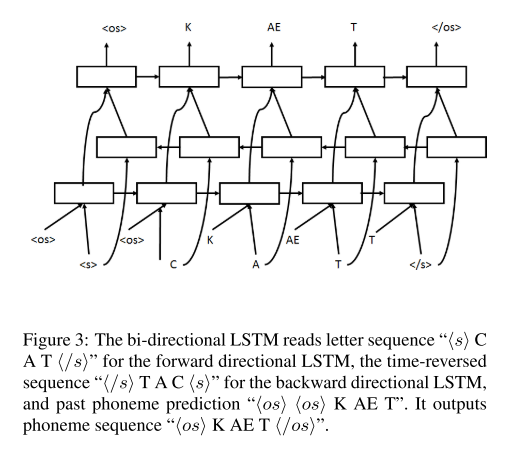
bi-directional LSTM은 위와 같이 grapheme의 입력이 여러 번 들어가고, 각 hidden layer의 output이 최종 layer에 함께 입력되는 형태를 띤다.
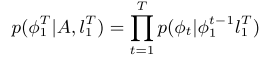
이때, 매 스텝마다 모든 입력 sequence를 보고 출력하는 효과가 나타나므로 posterior probability의 식에서 조건부로 들어가는 부분이 다르다.
실험 결과
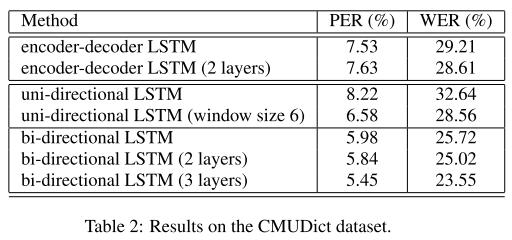
encoder-decoder LSTM의 결과는 n-gram 모델의 최고 성능으로 알려진 24.53% WER과 유사한 수준이다. 그리고 uni-directional LSTM은 기본 세팅으로 사용할 경우 가장 낮은 성능을 보여주지만, window size를 6으로 늘려서 문맥을 학습할 수 있도록 유도하면 성능이 크게 향상된다. 마지막으로 bi-directional LSTM은 1layer를 사용할 때부터 n-gram과 거의 동일한 성능을 보이는데 layer를 3개까지 깊게 쌓아보면 성능이 더 향상되면서 SOTA를 기록한다.

CMUDict뿐만 아니라 NetTalk, Pronlex와 같이 유명한 영어 데이터셋에 대해서 평가를 진행해도 bi-directional LSTM이 모두 SOTA를 갱신하였다.
의견
- 논문에서 모델 설명에 사용한 예시를 좀 더 긴 단어를 사용해 grapheme과 phoneme의 길이가 다른 경우를 보여주면서 alignment 사용 여부를 확실히 구분지어 줬으면 좋았을 것 같다.
- seq2seq 모델에서 입력을 정방향으로 넣어주면 성능이 어떻게 변하는지에 대한 실험도 필요해 보인다.
- neural net이 G2P에도 효과적으로 적용될 수 있다는 가능성을 보여줬다.




Leave a comment