
SoundStream: An End-to-End Neural Audio Codec
Zeghidour, Neil, et al. “Soundstream: An end-to-end neural audio codec.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 30 (2021): 495-507.
들어가며
음성 맞춤형 코덱들이 일반적으로 목표로 하는 비트레이트로 음성, 음악 및 (일반적인) 오디오를 효과적으로 압축할 수 있는 뉴럴 오디오 코덱 모델인 SoundStream을 제안한다. SoundStream은 Text-to-Speech(TTS)와 Speech Enhancement 연구에서 제안된 방법들을 기반으로 모델 구조와 목적 함수를 구성하여 양자화된 임베딩으로부터 고품질의 오디오를 재건할 수 있다. 전통적인 방식의 코덱들은 고정된 비트레이트에서 동작하였지만, SoundStream은 다양한 비트레이트(3kbps ~ 18kbps)에 걸쳐 오디오를 압축함과 동시에 SOTA 모델들의 성능을 뛰어넘는다. 또한, 본 논문에서 제안하는 컨디셔닝 방법을 통해 디노이징과 압축을 동시에 수행할 수 있다.
핵심 요약
- End-to-End로 Encoder, Quantizer, Decoder가 모두 한 번에 학습되는 최초의 뉴럴 오디오 코덱이다.
- Opus, EVS 등 SOTA 코덱들을 넒은 범위의 비트레이트에서 능가하며, Quantizer Dropout이라는 기법으로 학습되어 하나의 모델이 여러 비트레이트를 다룰 수 있다.
- 추가적인 지연 시간 없이 압축과 품질 향상을 동시에 수행할 수 있는 코덱을 제안한다.
모델 구조
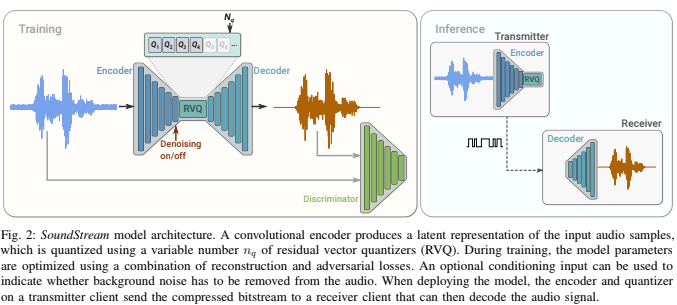
SoundStream 모델은 아래의 네 가지 모듈로 이루어져 있다.
- Encoder: 오디오를 받아 임베딩 시퀀스로 만드는 역할을 한다.
- Residual Vector Quantizer(RVQ): 임베딩을 유한한 코드북 벡터의 합으로 나타냄(=벡터 양자화)으로써 목표로 하는 비트레이트로 정보를 압축하는 역할을 한다.
- Decoder: 양자화된 임베딩으로부터 오디오를 재건하는 역할을 한다.
- Discriminator: Decoder로부터 재건된 오디오와 원본 오디오를 구분지을 특성을 학습하여 고품질 오디오 압축의 학습을 돕는 역할을 한다.
위의 그림에 나타나 있는 것과 같이 네 가지 모듈은 End-to-End로 함께 학습되며, 인퍼런스 시에 Transmitter 쪽에서는 원하는 비트레이트에 맞춰 양자화된 임베딩을 전달하고 Receiver 쪽에서는 전달받은 임베딩을 디코딩하여 오디오 신호를 복원해내게 된다.
Encoder and Decoder
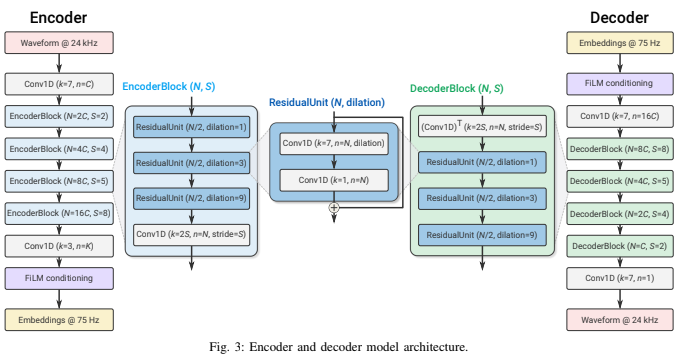
Encoder와 Decoder는 SEANet의 구조를 모방하여 convolution 블록 기반으로 만들어졌다. Encoder에서는 채널 수를 늘리면서 다운 샘플링하고, Decoder에서는 반대로 채널 수를 줄이면서 업 샘플링을 하여 오디오를 복원해내는 구조이다. 실시간 인퍼런스를 보장하기 위해서 모든 convolution 블록에 causal convolution을 사용하고 있다. 오디오는 Encoder 블록 내에 존재하는 모든 stride 값의 곱만큼 시간축으로 압축되는데, 위의 그림에서는 $2\times4\times5\times8=320$ 이므로 임베딩 하나가 320개의 입력 샘플을 의미하는 셈이다.
FiLM conditioning은 선택 사항으로, SoundStream을 통해 오디오 압축과 디노이징을 함께 수행하고 싶을 때 사용한다. 구체적으로는 (inputs, targets, denoise)의 형태로 학습 데이터셋을 구성하고, denoise가 True일 때만 targets을 입력 오디오의 깨끗한 버전으로 만든다. 그리고 denoise 임베딩을 linear layer에 통과시켜 feature modulation을 위한 계수들을 구한 뒤, Encoder나 Decoder convolution 블록의 출력에 modulation을 해주는 것이다. 사전 실험에 의하면, Encoder나 Decoder 보틀넥 부분에만 FiLM layer를 적용하는 것이 가장 효과적이라고 한다.
Residual Vector Quantizer

Quantizer는 Encoder의 출력인 임베딩을 타겟 비트레이트에 맞추어 압축하기 위해서 존재하는데, SoundStream에서는 Quantizer까지 End-to-End로 역전파를 통해 함께 학습되도록 유도하기 위해 VQ-VAE에서 제안하는 VQ를 사용한다. VQ는 임베딩 차원과 일치하는 차원을 가진 벡터들로 구성된 코드북을 가지고 있어서, 임베딩을 코드북 인덱스를 의미하는 one-hot 벡터로 표현하게 된다. 그런데 단순 VQ를 오디오 압축에 적용하기에는 치명적인 단점이 있다. 예를 들어, 코덱 모델이 6kbps를 목적으로 한다고 가정하면 24kHz의 샘플레이트를 가지는 오디오의 1초는 임베딩에서 75frame으로 표현되고, 6000/75=80 이므로 각 frame은 80개의 비트로 표현된다. 즉, 코드북에는 2^80개의 벡터가 저장돼 있어야 한다는 의미이므로 현실적으로 불가능하다.
SoundStream은 VQ를 여러 스테이지로 나누어 처리하는 RVQ를 사용하여 위의 문제를 극복한다. 알고리즘1에서 나타낸 것처럼 임베딩을 여러 Quantizer에 통과시킨 후, 잔차 값을 반복적으로 통과시키는 과정을 거치고 매 스테이지에서 나온 양자화 벡터들을 더하여 최종 양자화 벡터를 만들어 낸다. SoundStream에서는 8개의 Quantizer를 사용하므로, 하나의 코드북 당 10개의 비트를 담당하여 2^10=1024개의 학습가능한 벡터를 가지고 있으면 된다.
일반적으로 코드북 사이즈(=코드북이 가진 벡터 개수)가 정해지면 Quantizer의 개수가 비트레이트를 결정한다. 그리고 Quantizer가 Encoder, Decoder와 함께 학습되므로 원하는 비트레이트가 있다면 해당 비트레이트로 학습된 SoundStream 모델이 각각 마련되어야 한다. 하지만, 이렇게 모든 비트레이트 경우의 수에 맞춰 모델을 준비하는 것은 메모리 사용 측면에서 비효율적이므로 비트레이트를 원하는대로 조절(scalable)할 수 있는 모델이 있으면 훨씬 실용적이게 된다. SoundStream 저자들은 이러한 모티베이션을 가지고 Quantizer Dropout을 제안한다. 말그대로 학습할 때 Quantizer를 일부 사용하지 않는 것인데, 랜덤 개수만큼을 사용하는데 대신 Quantizer를 1번부터 순차적으로 사용한다. Quantizer Dropout을 사용하면 Quantizer 개수로 표현 가능한 모든 비트레이트에 대해 모델이 대응 가능해지고, 인퍼런스 시에는 표현 가능한 비트레이트 중 하나를 정하면 압축에 사용하는 Quantizer 수가 저절로 정해지게 된다.
VQ-VAE-2에서 제안한 EMA 업데이트 방식을 사용하여 Quantizer를 학습한다. 그리고 모든 코드북이 사용되도록 유도하기 위해서 파라미터를 랜덤 초기화 대신 첫번째 학습 배치의 k-means 클러스터링 결과로 나온 각 클러스터 중심으로 초기화하는 방법, 몇 배치 동안 선택되지 않은 코드북을 현재 배치의 임의의 입력 프레임으로 대체하는 방법을 사용한다.
Discriminator
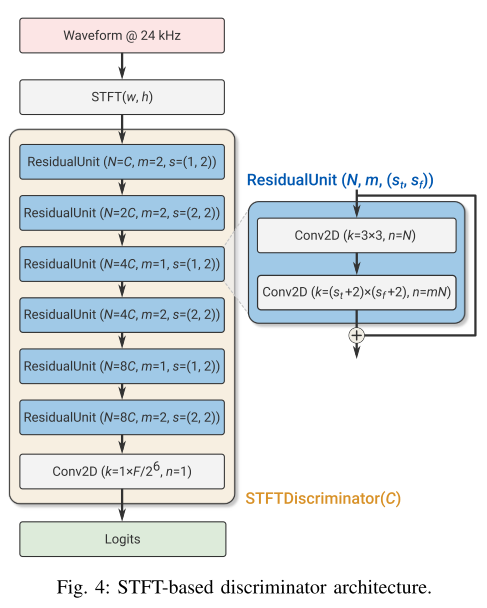
Discriminator는 크게 wave-based 와 STFT-based Discriminator로 구성되어 있다. Wave-based Discriminator는 MelGAN에서 제안된 MSD와 같은 구조이다. 그리고 STFT-based Discriminator는 입력 오디오의 STFT 결과인 복소수 표현을 받아 logit을 출력하며 그림 4와 같이 2D convolution 블록으로 이루어져 있다.
손실 함수
SoundStream은 signal reconstruction fidelity와 perceptual quality를 모두 높이기 위한 혼합 loss를 구성하여 학습을 진행한다. 먼저, Discriminator는 원본 오디오와 디코딩된 오디오를 분류하기 위해 아래와 같은 loss로 학습된다. 여기서 k는 Discriminator의 인덱스를 나타내고, 0은 STFT-based, 나머지는 서로 다른 resolution을 가진 waveform-based Discriminator들을 의미한다.
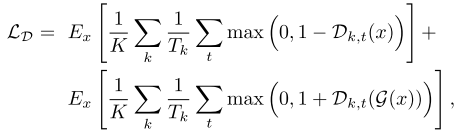
그리고 Discriminator를 제외한 Generator 파트는 아래와 같이 세 가지 loss의 합으로 학습된다.
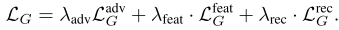
adversarial loss 는 Discriminator와 적대적으로 학습하면서 perceptual quality를 높이는 목적으로 사용되는 것이고, feature loss와 multi-scale spectral reconstruction loss는 fidelity 향상에 기여한다. feature loss는 원본 오디오와 복원된 오디오를 각각 Discriminator에 통과시켰을 때, Discriminator 내부 레이어 출력들의 L1 loss로 정의된다.
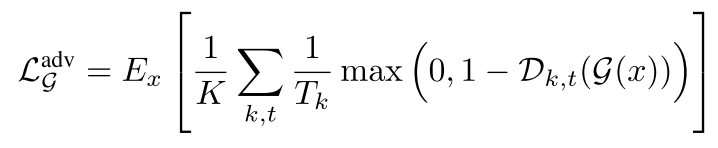
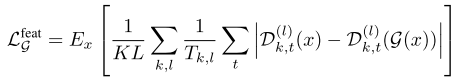
그리고 multi-scale spectral reconstruction loss는 원본 오디오와 복원된 오디오를 각각 64-bin 멜스펙트로그램으로 나타낸 뒤에 프레임 간 L1, L2 loss를 합한 형태이다.
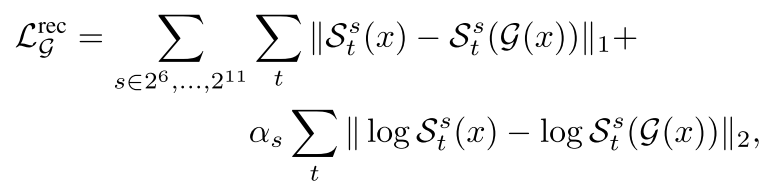
실험 결과
본 논문에서 SoundStream은 Speech(LibriTTS, LibriTTS+Freesound의 노이즈), Music(MagnaTagATune) 데이터셋으로 학습되었고, 테스트는 각 데이터셋의 테스트 스플릿을 사용하여 진행하였다. 주관적인 평가 지표로는 MUSHRA를 사용하였고, 객관적인 평가 지표로는 ViSQOL을 사용하였다.
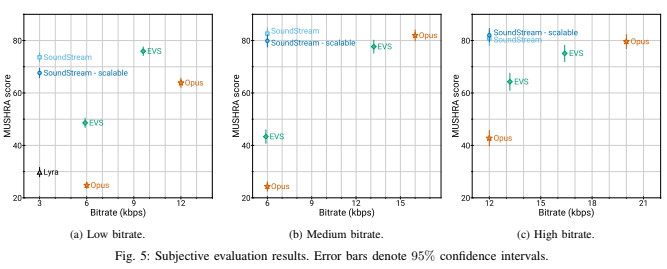
그림 5는 저, 중, 고 비트레이트 구간에서 SoundStream과 베이스라인 모델들간의 MUSHRA 성능 비교를 나타낸다. 보다시피 SoundStream은 모든 구간에서 가장 작은 비트레이트로 학습되었음에도 불구하고, 다른 모델들을 크게 능가하거나 비슷한 성능을 보인다. 또한, Quantizer Dropout을 적용한 scalable 세팅으로 학습하여도 성능저하가 크지 않다.
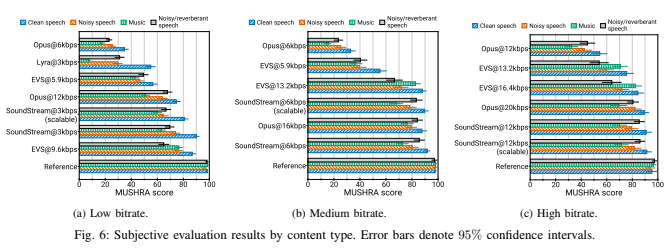
그림 6은 마찬가지로 저, 중, 고 비트레이트 구간에서 오디오 컨텐츠 타입에 따른 MUSHRA 성능을 보여준다. SoundStream은 clean, noisy 음성에 대해서 일관적으로 높은 성능을 보이고 음악 인코딩에도 우수한 성능을 보인다. 동시에 저자들은 이렇게 낮은 비트레이트에서 다양한 오디오 컨텐츠 타입에 대해 작동하는 코덱은 처음이라고 주장한다.
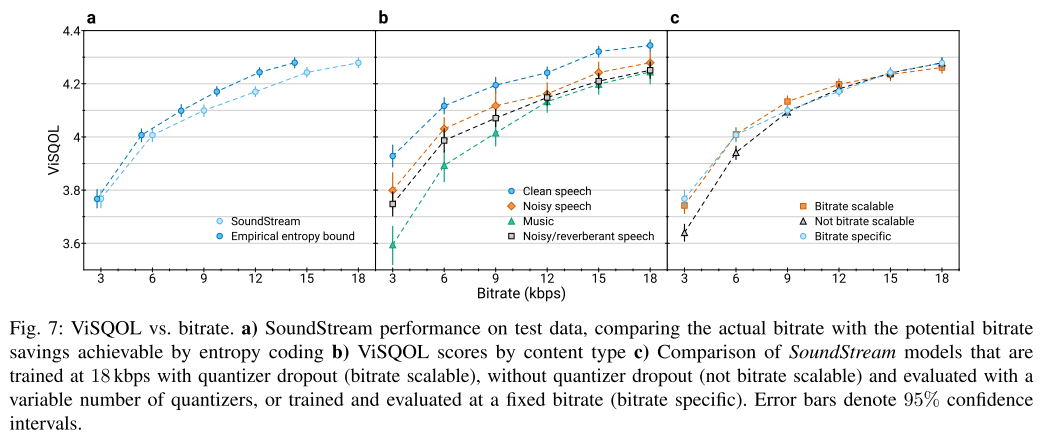
그림 7은 3kbps부터 18kbps까지의 비트레이트 범위에서 SoundStream의 ViSQOL 성능을 보여준다. 비트레이트가 낮아짐에 따라 ViSQOL 점수가 떨어지지만 가장 낮은 비트레이트에서도 3.7 이상을 유지한다.
예상대로 clean 음성을 압축했을 때 점수가 가장 높고, 비트레이트를 scalable하게 학습한 모델이 비트레이트가 낮아지더라도 성능 저하가 더 작게 나타났다.
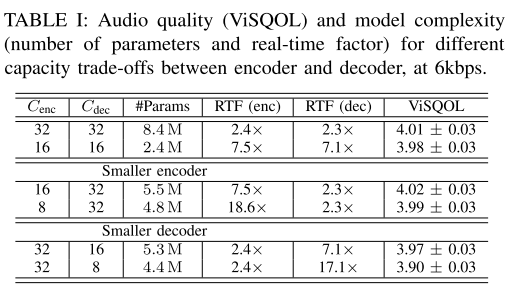
표 1은 Encoder와 Decoder 채널수를 조절하여 어블레이션 스터디를 진행한 것인데 ViSQOL 점수의 편차를 고려해 봤을 때, 큰 성능 저하 없이 모델의 크기를 줄이고 싶으면 가벼운 Encoder와 무거운 Decoder를 사용하는 편이 좋다는 결론이 나온다.

표 2는 비트레이트를 6kbps로 유지하면서 Quantizer 개수와 코드북 사이즈를 변경하면서 ViSQOL 점수를 측정해본 결과이다. 적은 수의 Quantizer를 사용하고 큰 코드북을 사용하는 것이 높은 계산 복잡성을 요구하긴 하지만 최고의 코딩 효율성을 달성할 수 있다는 것을 알 수 있다.
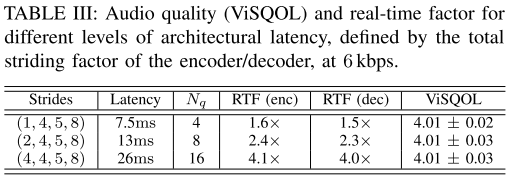
표 3은 convolution 블록의 stride 값을 조절하여 latency를 변경했을 때 RTF와 ViSQOL을 측정한 결과이다. 세가지 세팅에서 ViSQOL은 차이가 없었고, latency가 늘어날수록 인코딩과 디코딩 단계에서 한 프레임이 더 긴 오디오 샘플을 담당하는 것이기 때문에 RTF가 크게 증가하는 것을 볼 수 있다.
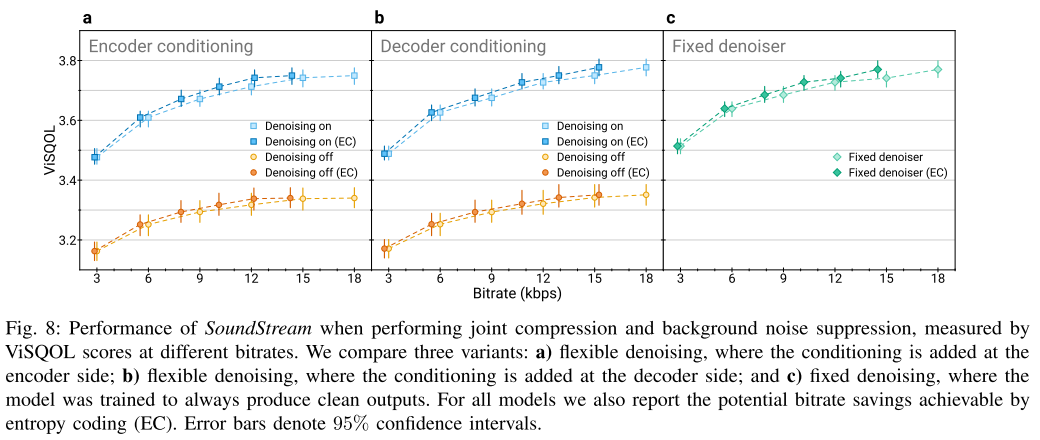
그림 8은 디노이징을 True, False 값을 섞어가며 학습한 Flexible Denoising과 항상 디노이징을 하도록 학습한 Fixed Denoising을 비교하고 있다. Flexible Denoising에서는 특히 Encoder와 Decoder 중 어느 쪽에 컨디셔닝을 하던지 큰 성능차를 보이지 않는다. 또한 Fixed Denoising과 비교해도 성능차가 없다. 한편, Entropy Coding을 통해 계산한 잠재적 비트레이트 절약율을 보면, Encoder 쪽에서 양자화 전에 디노이징을 적용하는게 좋다고 한다.
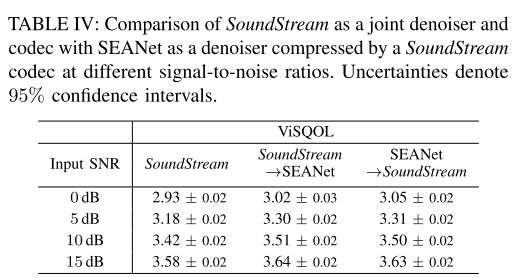
마지막으로 표 4에서는 디노이징과 압축을 함께 학습하는 SoundStream과 이를 분리시켜 디노이징 모델을 별도로 사용하는 방법 간의 성능을 비교한다. 여기서 디노이징 모델로는 SEANet을 사용한다. ViSQOL을 보면 디노이징과 압축 중 어떤걸 먼저 수행하는지에 따른 성능 차이는 없었다. 그리고 디노이징과 압축을 함께 배우도록 하는 joint 모델의 성능이 둘을 분리해서 수행하는 disjoint 모델과 거의 동등한 성능을 보이며, 두 가지 모델을 연결지어 사용하는 과정에서 생기는 latency가 없기 때문에 더 유리하다고 주장한다. 또한 입력 오디오의 품질이 좋아질수록(SNR이 높을수록) joint 모델과 disjoint 모델의 성능 차이는 점점 줄어든다.
의견
- 코덱 모델의 일부 또는 후처리 모듈로써 기능하던 머신러닝 모델을 코덱 모델 전체에 성공적으로 확장시킨 첫 번째 논문이라는 점에서 의미가 크다. 또한, 싱글 모델로 다양한 비트레이트를 다룰 수 있다는 점에서 코덱 모델의 큰 패러다임을 바꾸었다고 생각한다.
- SoundStream은 왜 stride를 (2,4,5,8)로 정하게 되었는지, latency 관련 어블레이션 실험에서 명확하게 설명해주면 더 좋았을 것 같다. 아마도 신호를 송수신하는 상황에서 초기에 신호가 도달하고 재생될때까지의 시간이 짧은 것이 실생활에서는 더 중요하기 때문에 latency가 중간 정도인 (2,4,5,8) 세팅을 선택한 것으로 추정된다.
- RVQ에서 codebook의 벡터를 선택하고 업데이트 하는 방식에 대한 설명이 부족해 보인다.
- 데모 페이지의 샘플들을 들어봤을 때, 베이스라인 모델들에 비해 복원된 오디오의 먹먹한 느낌이 덜한게 훨씬 잘 느껴지고 품질이 좋다.

Leave a comment