
Bryan Lim, Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting, 2019
들어가며
시계열 예측에서 multi-horizon(여러 time step)을 예측하는 문제는 복잡한 입력 변수들을 포함하고 있다. 예를 들어, 과거 정보 중 시간에 따라 변하는 정보도 있고 변하지 않는 정보도 있으며 미래의 정보 중 우리가 알고 있는 정보(e.g. day of week, month)도 존재한다. 예측 모델에 입력으로 주어지는 많은 정보들이 타겟과 어떤 관계를 갖고 있는지 알아내는 것은 쉽지 않은 문제이며 최근 제안되고 있는 딥러닝 모델들은 소위 black-box라 불리는 단점을 갖고 있기 때문에 이 문제를 해결해주지 못한다. 반면, Temporal Fusion Transformer(이하 TFT)는 해석 가능한 구조를 장점으로 내세워 여러 dataset에 대해서 state-of-the-art의 성능을 기록했는데 어떤 방법을 사용했는지 살펴보자.
핵심 요약
- 시계열 예측을 위한 다양한 input의 특성(static, time variant, known, continuous 등)을 고려하여 트랜스포머 구조를 설계함.
- Gating mechanism을 활용해 모델 구조에서 사용되지 않는 요소들을 건너뛰고 다양한 데이터셋을 수용할 수 있도록 신경망의 깊이와 복잡도를 조절함.
- static covariate encoder를 활용해 트랜스포머의 연산 과정에서 static 정보가 누락되지 않도록 여러 단계에 걸쳐 input으로 함께 넣어줌.
- variable selection network를 이용해 예측 성능에 도움이 되지 않는 noisy input을 제거함.
문제 정의
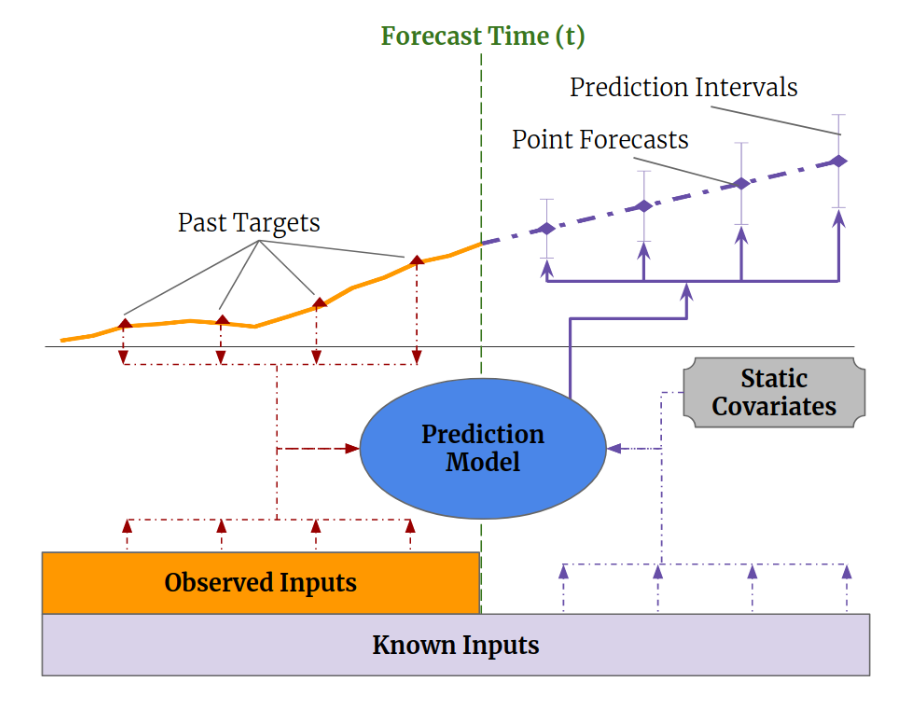
observed inputs(past), known inputs(past+future) 정보를 활용하여 미래의 target values 예측.
모델 구조
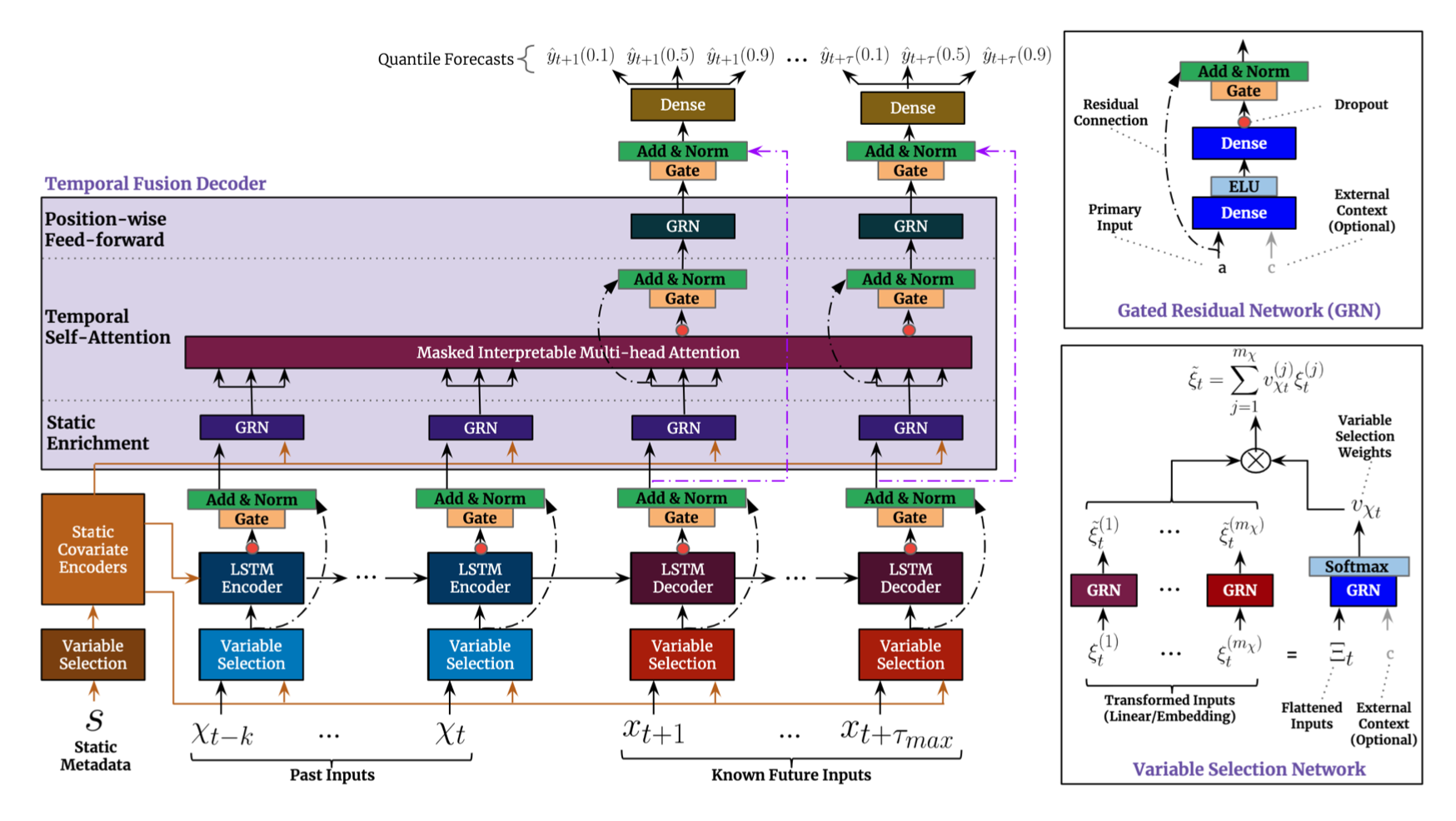
TFT의 입력으로 static metadata, time-varying past inputs 그리고 time-varying known future inputs가 주어지고 Variable Selection을 통해 각 time-step별 중요한 input에 가중치가 더 주어진다. 그리고 Gated Residual Network가 모델의 information flow를 효율적으로 만들어준다. Time dependent processing을 위해서는 sequence-to-sequence 구조를 활용한 local processing과 multi-head attention을 활용한 long-term processing을 거친다.
손실 함수
prediction interval을 예측하는 것이 목표이므로 Quantile loss를 사용한다.
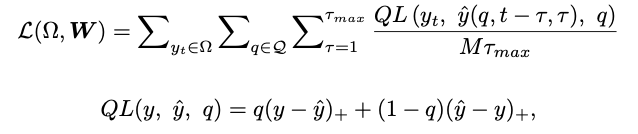
test set에 대한 성능 평가로는 normalized quantile loss를 사용한다.
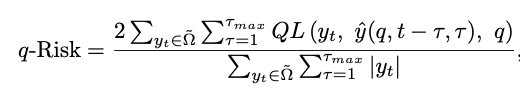
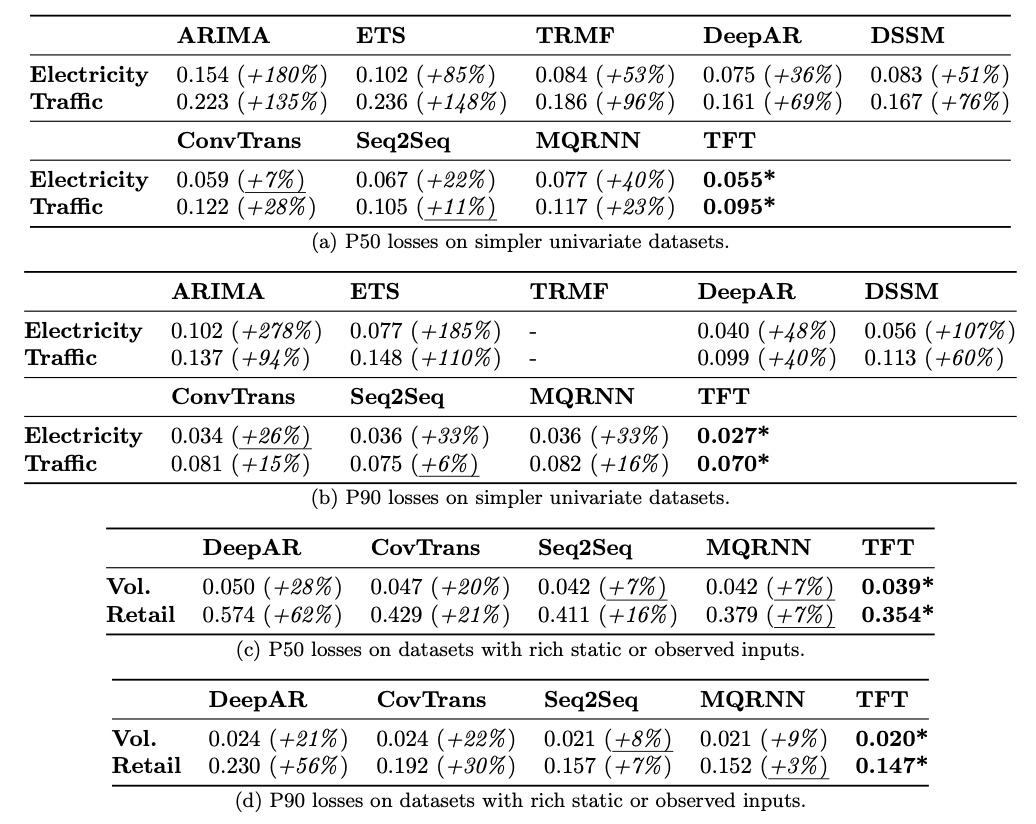
예측 성능
Electricity, Traffic, Volatility, Retail dataset에 대해 state-of-the-art의 성능을 기록함.
해석 가능성
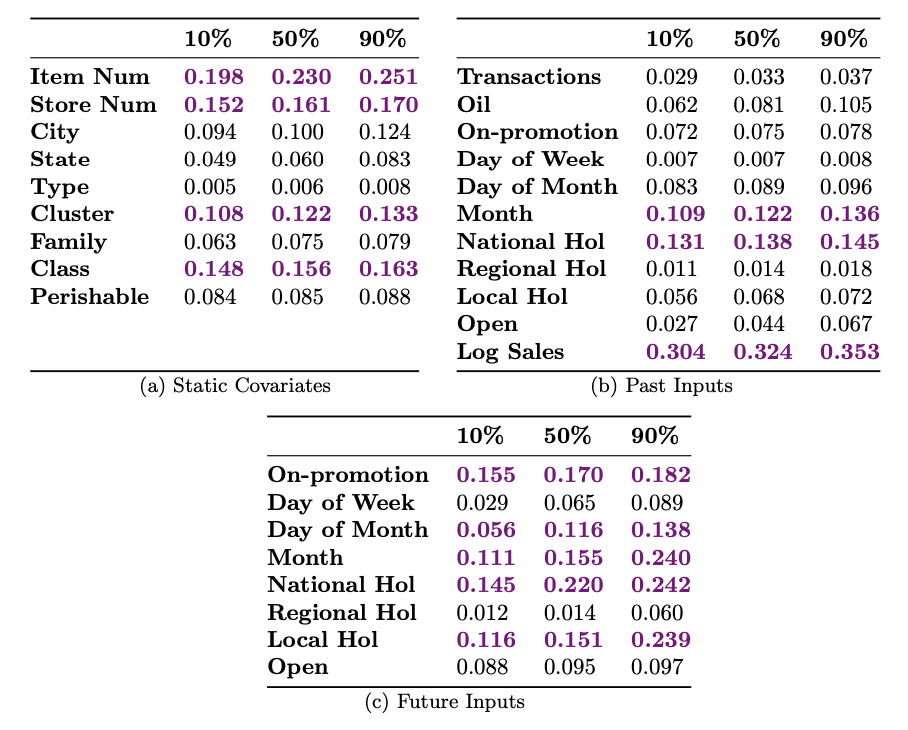
변수 중요도
variable selection network의 weight를 분석해 변수의 중요도를 판단할 수 있음.
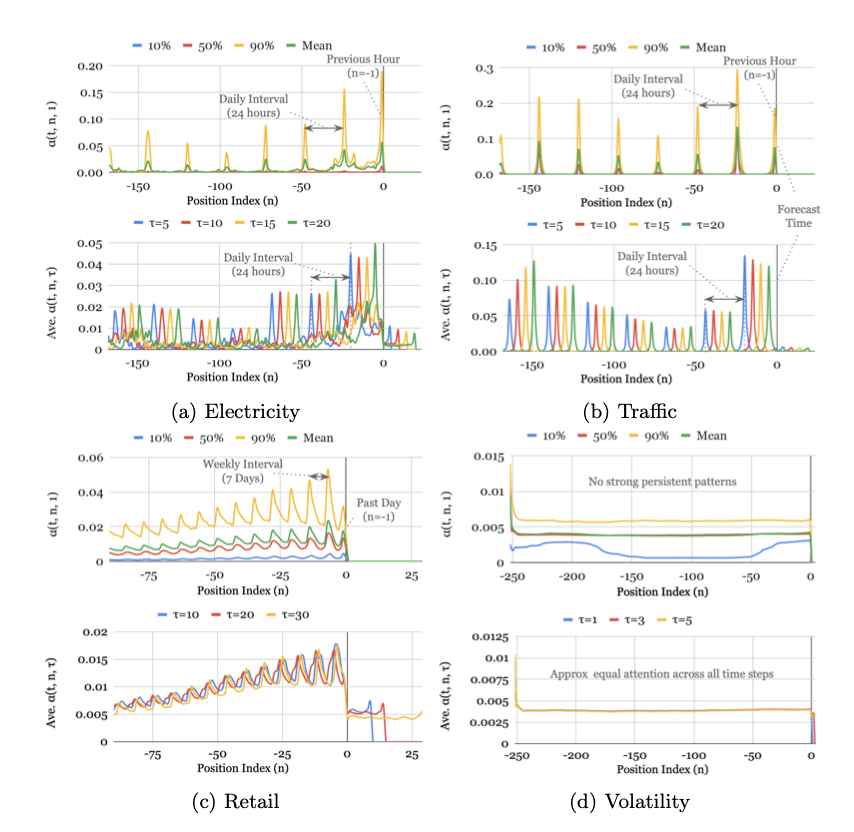
시간적 패턴 분석
seasonality와 같은 시간에 따른 패턴을 attention weight를 통해 분석 및 시각화할 수 있음.
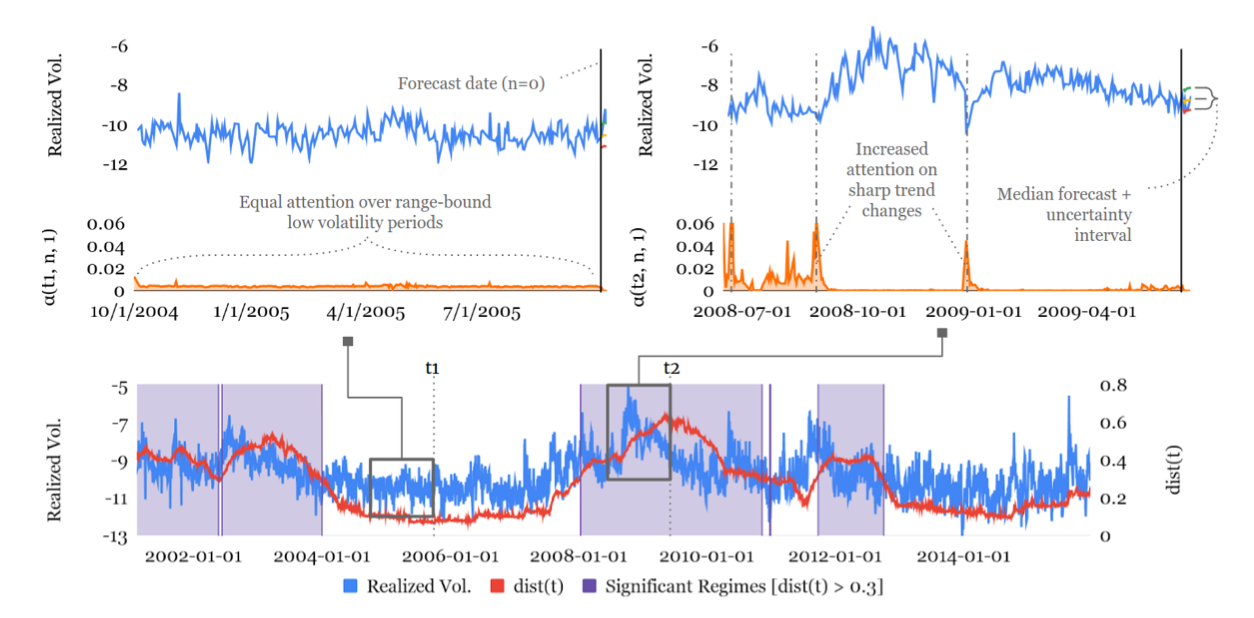
국면 식별
time step 별 attention weight의 평균을 분석해서 급격한 변화가 일어나는 중요한 국면을 식별할 수 있음.
아래 그림에서 2008년 금융 위기가 significant regime으로 그려진 것을 볼 수 있다.
결론
- 트랜스포머 구조를 활용해 해석 가능하고 높은 정확도를 가지는 시계열 예측이 가능하다.
- 입력의 복잡도가 낮은 것부터 높은 것까지 모두 상관없이 실세계의 여러 데이터셋에 적용 가능한 모델이다.




Leave a comment