
Unified Mandarin TTS Front-end Based on Distilled BERT Model
Zhang, Yang, Liqun Deng, and Yasheng Wang. “Unified Mandarin TTS Front-end Based on Distilled BERT Model.” arXiv preprint arXiv:2012.15404 (2020).
들어가며
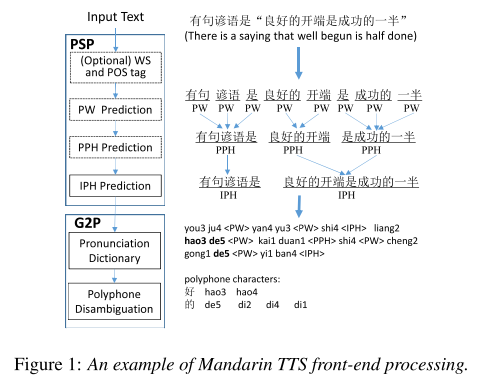
Mandarin TTS에는 prosodic structure prediction(PSP), grapheme-to-phoneme(G2P)로 이루어진 front-end 모듈이 필수적인데 그동안 text processing의 연속인 긴 파이프라인으로 구성되어 있어서 많은 노력이 들 뿐더러 에러가 누적되는 이슈가 있었다. 그렇기 때문에 최근에 front-end를 단순화 시키는 아이디어를 제시하는 연구들이 늘어났는데 대부분의 연구는 front-end 단계들을 통합된 모듈로 합치기는 하지만 모델의 구조가 복잡했고 계산량이 여전히 많으며 end-to-end로 학습될 수 없다는 단점을 갖고 있다.
본 논문에서는 위의 단점을 해결하는 단순하면서 효율적인 front-end 모델을 제시한다. pre-trained 언어 모델의 성공을 모티브로 삼아서 Chinese BERT에 기반한 unified Mandarin TTS front-end 모델을 만들었다.
핵심 요약
- BERT를 text encoder로 사용하고 multi-task learning으로 PSP와 G2P를 동시에 학습할 수 있는 unified front-end 모델을 제안한다.
- two-stage distillation strategy를 사용해서 front-end 모델을 더 작은 사이즈로 주입하고 edge device로의 배포도 용이하도록 만들었다.
- 본 논문에서 제시하는 모델로 PSP와 G2P task에서 SOTA 성능을 기록했다. 그리고 distilled 모델도 베이스라인 모델의 25%에 해당하는 크기로 베이스라인의 성능을 뛰어넘었다.
모델 구조
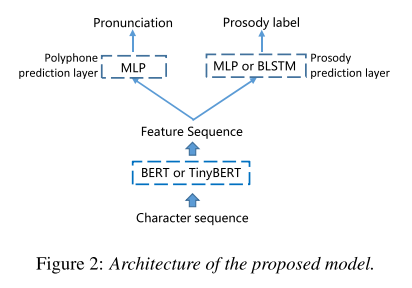
모델은 크게 3 파트로 구성된다. 첫번째인 text encoder에서는 character-based BERT를 사용해 text representation을 뽑아내고 두번째, 세번째 파트인 polyphone prediction layer와 prosody prediction layer에서 각각 pronunciation과 prosody를 예측한다.
polyphone prediction layer는 모든 훈련 문장에 대해서 polyphonic character에 대한 cross entropy를 구하고 이를 평균내는 방식으로 loss를 계산하여 학습하고, prosody prediction layer는 prosodic break를 4개로 분류(mixed prosodic level → 그림 3 참고)하여 polyphone과 비슷한 방식으로 학습한다.

그리고 두 개의 예측 파트가 multi-task learning으로 함께 학습되는데 pronunciation과 prosodic boundary가 함께 레이블링되어 있는 말뭉치를 구축하기는 어려우므로 mixed training strategy를 적용한다. 즉, 모든 학습 배치마다 pronunciation, prosody 학습을 위한 데이터를 섞어서 배치하여 전체 모델의 가중치가 훈련 과정 내에 연속적으로 업데이트 될 수 있도록 유지하면서 loss는 데이터에 따라 선택적으로 계산한다.
TinyBERT
original BERT는 계산량이 많고 큰 저장용량을 요구하기 때문에 real-time 서비스에 사용하기에는 어려움이 있다. 그래서 저자들은 knowledge distillation 기법을 적용한 TinyBERT를 이용한다. 이는 BERT와 동일한 구조를 갖지만 Transformer layer와 hidden unit의 수가 더 적은 버전이라고 생각하면 된다.
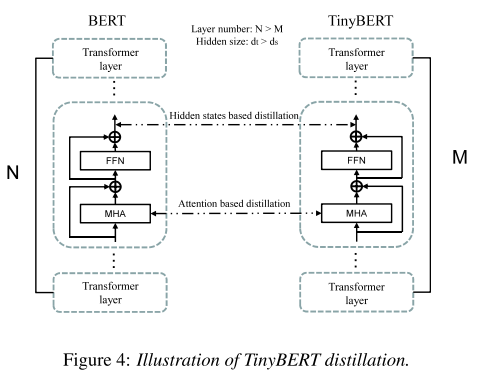
distillation 과정은 두 파트로 나뉠 수 있는데 teacher모델의 multi-head attention matrix를 배우는 attention based distillation 과정과 Transformer layer의 output으로부터 배우는 hidden states based distillation 과정이 있다. 두 과정 모두 teacher와 student 모델의 matrix 사이에서 MSE를 계산하여 훈련된다. 그리고 이렇게 만들어진 TinyBERT를 TTS front-end task에 적합하게 fine-tuning 하기 위해서는 그림 5와 같은 과정이 필요하다.
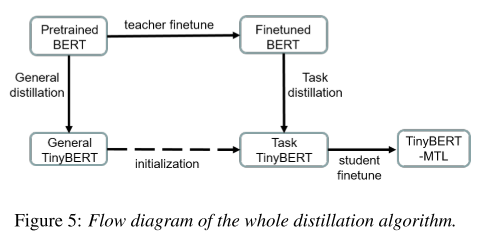
- Distillation algorithm
- general distillation: 큰 스케일의 open domain data로 학습한 original pre-trained BERT 모델을 distill하여 general TinyBERT를 만든다.
- fine-tune teacher model: BERT를 encoder로 가진 front-end 모델을 TTS-specific training data(i.e., polyphone and PSP related training dataset)로 학습시키면서 fine-tune한다.
- task distillation: fine-tuned BERT를 teacher로, general TinyBERT를 student로 하여 TTS-specific data에 대한 knowledge를 distill하는 과정을 거친다.
- fine-tune student model: front-end 모델의 encoder를 student TinyBERT로 바꾸고 2단계에서 한 것처럼 fine-tuning을 한다.
실험 세팅
데이터셋
- 내부적으로 수집한 데이터셋을 사용하였다.
- polyphone disambiguation: 340581 문장, 661 polyphone characters
- prosodic structure prediction: 231964 문장
평가 지표
- polyphone disambiguation
- ACC: character accuracy
- SENT ACC: sentence accuracy
- prosodic structure prediction
- F1 score: prosodic word(PW), prosodic phrase(PPH), intonational phrase(IPH) 각각에 대해 계산
베이스라인
- WFST-based G2P: weighted finite-state transducer(WFST)에 기반한 joint n-gram 모델
- BLSTM: g2pM 논문에서 제시한 bi-directional LSTM 모델
- BERT-polyphone: BERT encoder와 polyphone prediction layer만 가지고 있는 모델
- CRF: prosody structure를 예측하기 위해 고안된 3-level CRF 모델
- BLSTM-CRF: MFNN-BLSTM에 CRF를 붙인 형태
- BERT-prosody: BERT encoder와 prosody structure prediction layer만 가지고 있는 모델
- BERT-MTL: BERT encoder와 multi-task learning 결합한 모델
- TinyBERT-MTL: TinyBERT encoder와 multi-task learning 결합한 모델
실험 결과
베이스라인 성능 비교
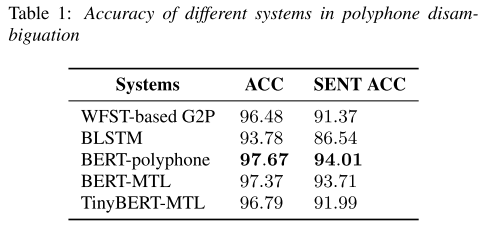
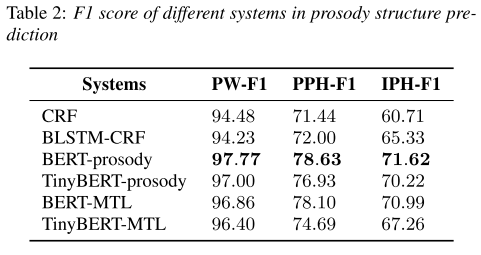
표 1,2에서 볼 수 있듯이 본 연구에서 제안하는 BERT를 encoder로 사용한 모델이 두 가지 task에서 가장 좋은 성능을 기록했다. multi-task learning을 했을 때는 single task일 때보다 성능이 약간 하락했지만 전통적인 방식들보다 여전히 높은 성능을 보여준다.
Task별 Prediction layer에 따른 성능 비교
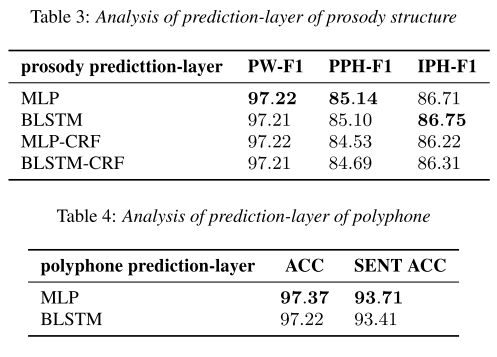
그리고 prediction layer의 구조를 바꿔가면서 실험해봤을 때 두 경우 모두 MLP를 썼을 때 성능이 가장 좋았다. 이로부터 BERT encoder가 이미 충분히 context를 잘 추출해내고 있음을 알 수 있다.
모델 크기와 추론 속도
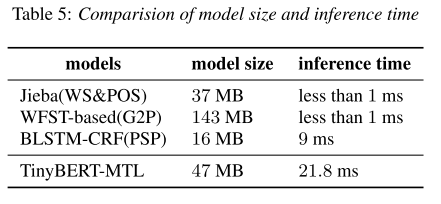
TinyBERT-MTL은 benchmark 모델인 WFST-based 모델의 25% 수준의 크기로 더 좋은 성능을 낸다. 추론 속도는 비록 증가했지만, TTS 서비스에서 latency로 체감할 정도의 수준은 아니기 때문에 용인할 수 있다고 한다.
의견
- 중국어 TTS를 할 때 언어의 특성으로 인해 전처리 과정이 복잡하다는 특징이 있는데 이를 하나의 모델로 통합하면서 성능도 향상시킨 것이 인상적이다.
- BERT의 변형모델이 발전함에 따라서 추가적인 성능 향상을 기대해볼 수 있겠다.

Leave a comment