
VALL-E
Wang, Chengyi, et al. “Neural codec language models are zero-shot text to speech synthesizers.” arXiv preprint arXiv:2301.02111 (2023).
들어가며
TTS에 랭귀지 모델링을 최초로 접목시킨 논문이다. VALL-E라고 부르는 neural codec language model은 neural audio codec model에서 나온 이산적인 code를 입출력으로 활용해서 TTS를 conditional language modeling 태스크로 간주한다. VALL-E는 6만 시간 이상의 학습 데이터를 사용하여 훌륭한 in-context learning 성능을 보여주고, 특히 3초의 짧은 음성만으로 처음보는 화자의 특징을 가진 고품질 발화 오디오를 합성할 수 있다.
핵심 요약
- 자연어 처리 분야에서 획기적인 발전을 이룩한 GPT-3와 같이 TTS를 language model로 간주하여 멜 스펙트로그램 대신 audio codec 모델의 code를 모델링한다.
- 방대한 양의 semi-supervised 데이터로 TTS모델을 학습하여 화자 측면으로 일반화된 모델을 만들 수 있음을 보이고, 이를 통해 semi-supervised 데이터를 활용해서 학습 데이터를 스케일업하는 것이 TTS에서는 과소평가 되어 있었음을 보여준다.
- VALL-E는 제로샷 시나리오에서 화자 유사성이 높고 자연스러운 음성을 생성할 수 있으며, 같은 텍스트 입력이 들어오더라도 (프롬프트 오디오의 음향 환경과 화자의 감정은 유지한 채) 다양한 출력을 만들어낼 수 있다.
모델 구조
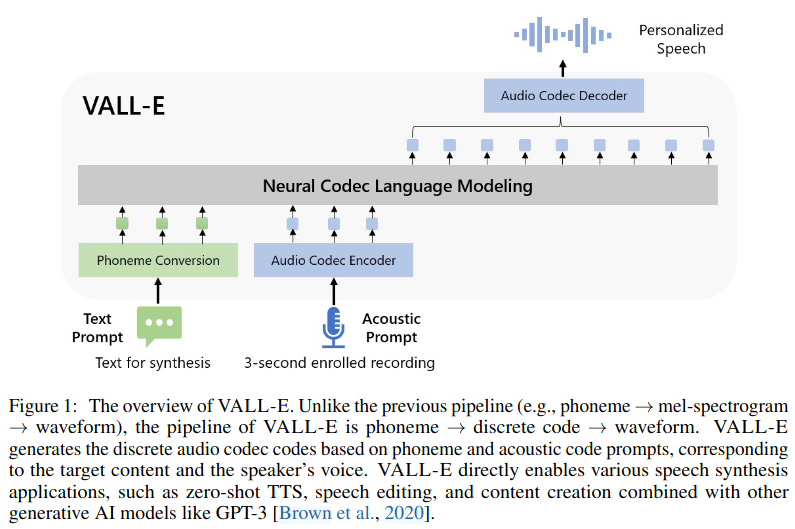
VALL-E는 텍스트와 프롬프트 오디오를 입력으로 받아서 어쿠스틱 코드를 만들어내는 neural codec language model이다. 여기서 텍스트는 G2P를 통해 phoneme으로 변형되고, 오디오 프롬프트는 오디오 코덱 모델을 통해 T x 8 사이즈의 2차원 코드 매트릭스로 표현된다.
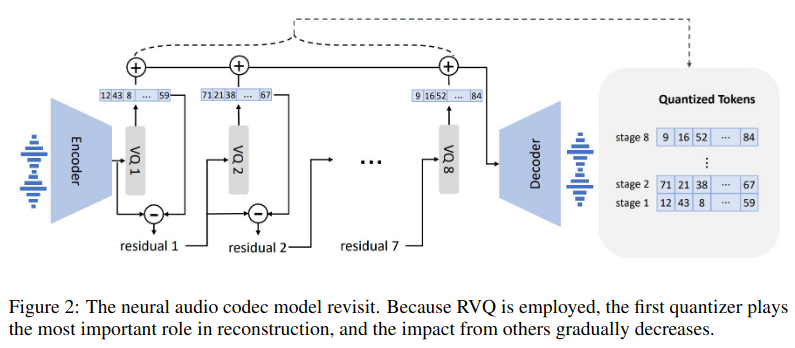
사전 학습된 neural audio codec 모델인 EnCodec을 사용한다. EnCodec의 인코더는 24kHz 오디오를 받아서 75Hz에 해당하는 임베딩을 생성하고 이는 오디오 길이를 320배 압축하는 셈이다. 각 임베딩은 8개의 퀀타이저를 이용한 RVQ로 구성되며 각 퀀타이저의 사이즈는 1024이다. 비트레이트는 24kHz 오디오 기준 6000에 해당한다. 비트레이트는 변경 가능하며, 비트레이트가 커질수록 퀀타이저가 많아지고, 오디오 재건 성능은 향상된다. 만약 12000 비트레이트를 선택했다면, 16개의 퀀타이저가 필요하고 10초의 오디오는 750 x 16의 크기를 가지는 매트릭스로 표현된다. 모든 퀀타이저의 이산적인 값을 사용해서 EnCodec의 디코더는 real-valued 임베딩을 생성하고 24kHz 오디오를 재건한다.
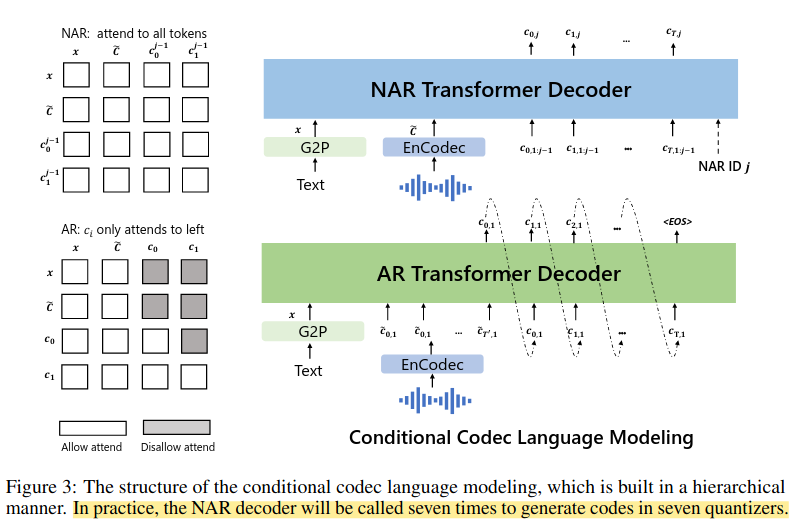
neural codec 모델은 residual quantization을 사용하기 때문에 code들은 계층적 구조를 가지게 된다. 상대적으로 앞쪽의 퀀타이저들은 화자의 아이덴티티와 같은 음향적 특성을 복원하기 위한 정보를 담아내도록 유도되고, 뒷쪽의 퀀타이저들은 좀 더 세밀한 디테일들을 담도록 배워진다. 따라서 VALL-E는 이러한 code의 특성을 이용해 2개의 conditional language model을 계층적 방식으로 디자인한다.
- AR Transformer Decoder
- AR 모델은 각 타임스텝의 첫번째 퀀타이저의 코드들을 예측하기 위해 학습된다.
- 모델은 phoneme embedding, acoustic embedding, transformer decoder, prediction layer로 구성되어 있다.
- 모델의 입력은 phoneme sequence와 첫번째 code sequence를 합쳐서 만들어지며, 각 sequence 뒤에 <EOS> 토큰을 붙여 구분해준다.
- sinuous position embedding도 계산해서 더해주는데 prompt와 input 토큰을 구분해서 계산한다.
- causal transformer 모델로, 각 타임 스텝의 토큰을 생성할 때 이전 스텝의 토큰들만을 참고할 수 있도록 마스킹 해준다.
- 마지막 projection layer와 acoustic embedding의 파라미터는 서로 공유한다.
- AR 모델을 학습할 때 오디오 클립을 명시적으로 추출하지 않으므로 오디오의 어떤 prefix sequence 이던 상관없이 뒤에 이어지는 sequence의 프롬프트로 간주될 수 있다.
- 인퍼런스 할때는 레퍼런스로 주어진 오디오(enrolled recording)에 해당하는 phoneme sequence와 합성하고자 하는 phoneme sequence를 이어붙여야 한다. 또한 레퍼런스 오디오의 acoustic token sequence도 함께 이어붙여주는데, 이 방법의 효과는 추후 실험으로 증명한다.
- AR 모델링을 위해서 sampling-based 디코딩을 사용한다. 그러면서 저자들은 beam search를 적용하게 되면 랭귀지 모델링이 무한 루프에 빠지는 경우가 있었다고 한다.
- NAR Transformer Decoder
- NAR 모델은 나머지 7개 퀀타이저의 코드들을 예측하기 위해 학습된다.
- 아키텍처는 AR 모델과 비슷하지만 서로 다른 8개의 acoustic embedding 레이어를 포함한다.
- 학습 과정에서 2~8 스테이지를 랜덤으로 추출하고 해당 스테이지에 맞는 퀀타이저의 코드를 예측하도록 훈련된다. 이전 스테이지까지의 acoustic token들이 모두 더해져 모델의 입력으로 제공되며, phoneme sequence도 함께 프롬프트로 들어온다.
- 또한 주어진 화자의 목소리를 복제하기 위해서 레퍼런스 오디오의 acoustic token들도 어쿠스틱 프롬프트로 사용되며, 8개의 코드를 모두 더한 값을 사용한다.
- AR과 마찬가지로 position embedding은 prompt와 acoustic sequence에 별도로 적용된다.
- AdaLN으로 transformer 모델에 현재 스테이지를 알려준다.
- AR 모델과 달리 NAR 모델은 self-attention 레이어를 통해 모든 입력 토큰을 볼 수 있다.
- NAR에서도 acoustic embedding과 output prediction 레이어의 파라미터는 공유된다.
- NAR 모델링을 위해서는 가장 높은 확률을 가진 토큰을 선택하도록 greedy decoding을 사용한다.
AR과 NAR 모델링으로 이루어진 conditional codec language modeling은 아래와 같은 수식으로 표현될 수 있다.
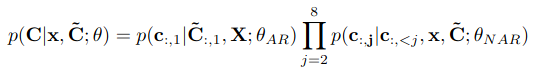
실험 결과
논문에서 VALL-E를 두 가지 타입으로 설계하여 평가한다.
- VALL-E: 본 논문의 주된 관심사로, 처음 보는 화자의 목소리가 담긴 오디오를 활용해 주어진 텍스트를 합성해내는 모델이다. 입력으로 합성할 텍스트 시퀀스, 레퍼런스 오디오 시퀀스, 그리고 레퍼런스 오디오와 매칭되는 텍스트가 들어간다. 이때 레퍼런스 오디오 시퀀스의 첫번째 레이어 토큰이 acoustic prefix로 쓰인다.
- VALL-E-continual: 모델이 continuation을 잘 수행할 수 있는지 체크하기 위한 세팅으로, 오디오의 첫 3초를 프롬프트로 사용한다. 인퍼런스 과정은 VALL-E와 동일하지만 레퍼런스 오디오와 생성된 오디오가 의미적으로 연속적이라는 것이 차이점이다.
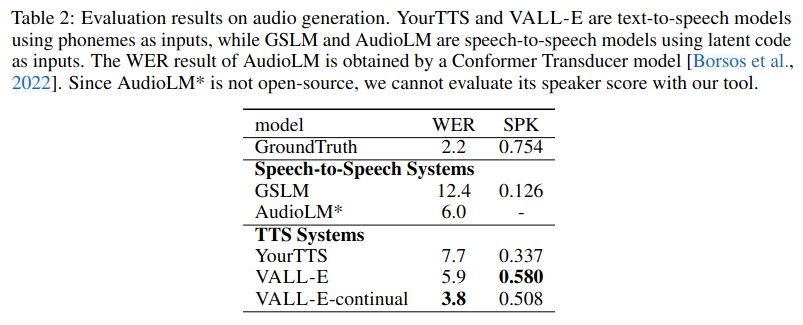
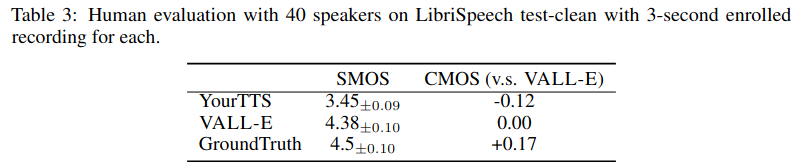
LibriSpeech 테스트셋으로 제로샷 성능을 평가했을 때, 베이스라인으로 삼은 YourTTS보다 robustness, speaker similarity 측면에서 우수하다.
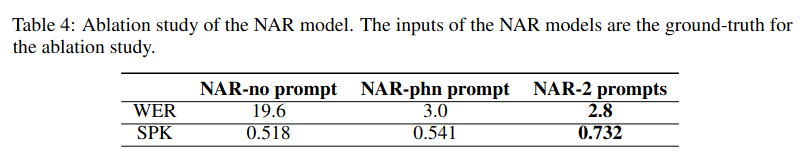
NAR 모델 입력에 대해 어블레이션 스터디를 진행한 결과, phoneme과 acoustic token을 모두 프롬프트로 제공해주는 것이 가장 좋은 성능을 보였다.
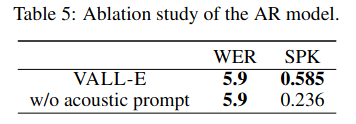
AR 모델 입력에 대해 어블레이션 스터디를 진행한 결과이다. 이때 NAR 모델에는 항상 2개 프롬프트를 모두 입력해주었다. 표 5에서 볼 수 있듯이 acoustic 프롬프트를 제거하게 되면 스피커 유사도가 극적으로 떨어진다. NAR 모델에서 acoustic 프롬프트를 볼 수 있음에도 불구하고 이런 결과가 나왔으므로, AR 모델에서 speaker similarity를 크게 결정짓는다는 것을 알 수 있다.
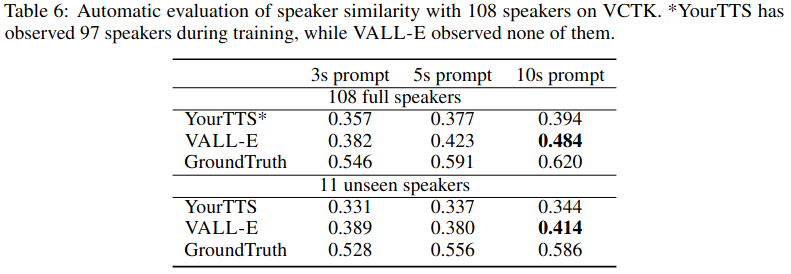

VCTK 테스트셋을 이용해서 제로샷 성능을 테스트했을 때도 VALL-E가 우수한 speaker similarity를 보여준다.
LibriSpeech 실험과 VCTK 실험에서 나타나는 차이점은 아래와 같다.
- VCTK 실험에서 VALL-E는 GT 보다 CMOS가 높게 나온다. ⇒ VCTK의 평균 문장 길이가 짧고 GT 오디오에 포함된 노이즈 때문이다.
- VCTK 실험에서 VALL-E는 SMOS가 LibriSpeech 실험에서보다 낮게 나오는 편이다. ⇒ VCTK에는 다양한 억양을 가진 화자들이 있기 때문에 스피커 유사도를 높이는 것이 원래 어렵다.
마지막으로 VALL-E의 장단점을 정리하면 아래와 같다.
- 장점
- Diversity: 샘플링 기반의 디코딩 방식을 사용하기 때문에 인퍼런스 결과가 다양하게 나온다.
- Acoustic environment maintenance: 다양한 어쿠스팅 환경을 가진 대용량 데이터로 학습되었기 때문에 어쿠스틱 환경이 유지된다.
- Emotion maintenance: 감정 데이터셋으로 학습되지 않았지만 어쿠스틱 프롬프트의 감정을 유지한 음성 합성이 가능하다.
- 단점
- Synthesis robustness: 불명확한 발음, 스킵, 반복 등이 일어난다. AR 랭귀지 모델의 어텐션 얼라인먼트 쪽 문제이며, Transformer-TTS에서도 비슷한 문제가 관찰되었다.
- Data coverage: LibriLight가 오디오북 데이터셋이라 억양이 단조로운 편이다.
- Model Structure: 랭귀지 모델을 2개로 나누는게 아닌 하나의 유니버설 모델을 만드는게 이상적이다. 전체를 NAR로 만들고 모델 인퍼런스 속도를 향상시키는게 필요하다.
의견
- SoundStream이나 EnCodec과 같이 neural audio codec 모델의 발전에 힘입어 TTS 연구에 language model을 도입한 점이 인상적이다.
- 화자 유사도를 계산하기 위해 사용한 WavLM-TDNN의 체크포인트가 공개되지 않은 것 같아 아쉽다.

Leave a comment