
VALL-E 2
Chen, Sanyuan, et al. “VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers.” arXiv preprint arXiv:2406.05370 (2024).
들어가며
이 논문에서는 zero-shot TTS에서 처음으로 인간 수준의 성능을 달성한 neural codec language model인 VALL-E 2를 소개한다. VALL-E 기반 모델에 repetition aware sampling과 grouped code modeling을 적용하여 안정성과 인퍼런스 속도를 향상시켰다. LibriSpeech와 VCTK 데이터셋 실험에서 VALL-E 2는 기존의 시스템들을 강건성, 자연스러움, 화자 유사도 측면에서 능가하는 것을 보여줬고, 최초로 이런 벤치마크들에서 사람의 수준에 근접한 수치를 기록했다. 더 나아가 VALL-E 2는 전통적으로 어렵다고 알려진 문장들로도 고품질의 음성을 합성할 수 있다. 저자들은 VALL-E 2의 장점이 실어증이나 루게릭 병을 앓고 있는 환자들의 음성을 생성해주려는 노력처럼 가치 있는 일에 쓰일 수 있다고 말한다.
핵심 요약
- VALL-E에서 쓰이던 random sampling을 repetition aware sampling으로 대체하여 출력 오디오의 불안정성을 해소하였다.
- AR 모델링 과정에 grouped code modeling을 사용해 코덱 코드를 그룹으로 나누어 모델링함으로써 시퀀스 길이를 줄여 인퍼런스 속도를 증가시키고, 긴 컨텍스트 모델링 문제를 완화하면서 성능도 향상시킨다.
- VALL-E 2는 LibriSpeech와 VCTK 데이터셋에 대해 처음으로 사람 수준에 도달한 제로샷 TTS 성능을 보이는 모델이다.
모델 구조

VALL-E 처럼 VALL-E 2도 AR 코덱 랭귀지 모델에서 NAR 코덱 랭귀지 모델로 이어지는 계측정 구조를 가지고 있다. AR 모델은 그룹 임베딩 레이어를 가지고 있어서 코드 임베딩을 그룹 임베딩으로 투영시키고, 그룹 예측 레이어는 반대로 그룹 내의 코드들을 예측하도록 학습된다. AR 모델은 causal attention을 사용하고 NAR 모델은 full attention을 사용한다. 텍스트 토크나이징을 위해서 BPE를 사용하고, 사전 학습된 EnCodec을 사용하여 오디오를 코덱으로 토크나이징한다. 그리고 코덱 디코딩을 위해서는 사전 학습된 Vocos를 사용한다.
AR 모델은 텍스트 임베딩과 첫번째 퀀타이저의 코드 임베딩을 받아서 AR 예측을 하도록 훈련된다. 이때, 코드 임베딩은 그룹 사이즈 G로 나뉘어 각 그룹 내의 임베딩들이 히든 디멘젼 차원으로 합쳐진 후 그룹 임베딩 레이어를 거쳐서 새로운 임베딩이 된다. 그리고 텍스트 임베딩과 그룹 임베딩 사이에
NAR 모델에서는 ID 임베딩을 AdaLN으로 제공해주는 것이 아니라 입력과 함께 합쳐서 제공하는 것이 VALL-E와 다르다. 그리고 텍스트 임베딩 뒤와 코덱 임베딩 뒤에
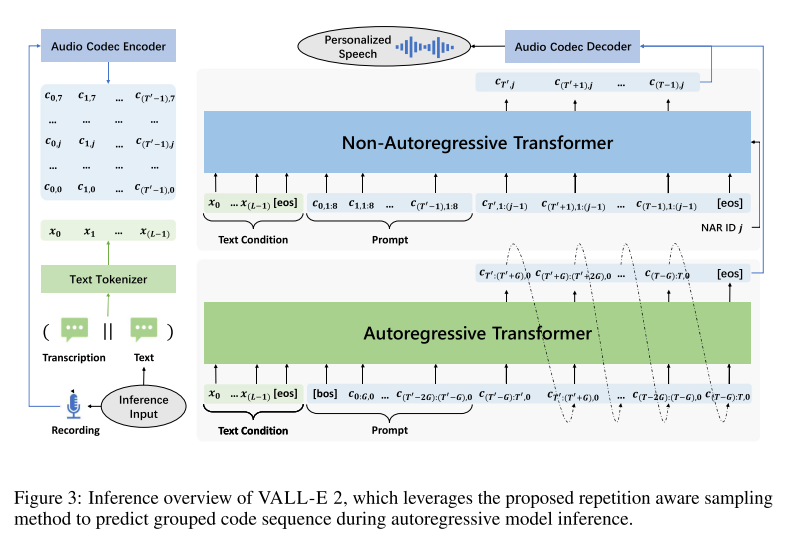

AR 모델을 인퍼런스 할 때는 repetition aware sampling을 사용한다. Random sampling을 사용하던 VALL-E 와 다르게 먼저 사전 정의된 top-p 값을 사용해 nucleus sampling을 하고, K 만큼의 윈도우 내에서 repetition ratio를 계산하여 특정 threshold를 넘으면 random sampling 된 코드로 대체하는 방식이다. 이렇게 하면, 디코딩 프로세스는 nucleus sampling을 통해 stability를 보장받고, random sampling을 통해 infinite loop를 피할 수 있게 된다. 또한, 추가적인 샘플링 과정으로 인해 지연되는 시간은 전체 인퍼런스 과정에서 굉장히 미미한 수준이라고 한다.
NAR 모델은 텍스트와 오디오 프롬프트, 그리고 AR 모델에서 예측한 첫 번째 퀀타이저 코드를 받아서 greedy decoding으로 2-8번째 퀀타이저 코드를 예측한다.
실험 결과
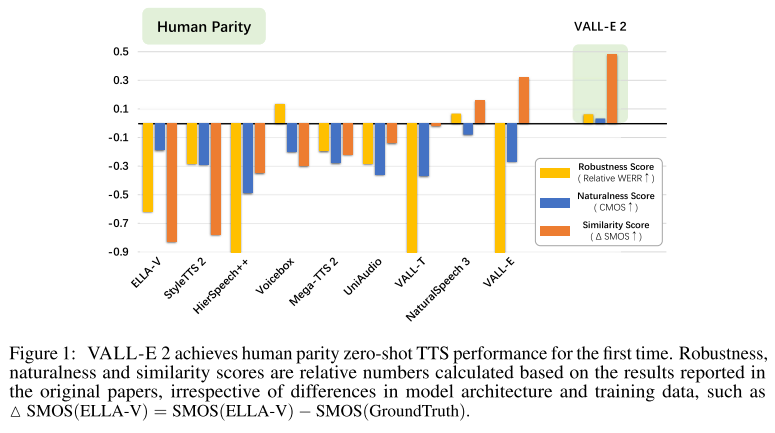
GT 오디오의 score와 각 모델 생성 결과의 score를 비교하여 막대 그래프로 나타내었을 때, Figure 1와 같이 VALL-E 2는 모두 GT를 앞서면서 human parity에 근접한 결과를 보여준다. 구체적인 실험 결과들을 지금부터 살펴보겠다.
우선 VALL-E 2는 Libriheavy 데이터셋을 사용해 학습되었다. VALL-E 2 모델은 그룹 사이즈 1, 2, 4, 8 로 네 가지 세팅으로 실험하여 비교하고 베이스라인인 VALL-E 는 원래의 구조를 유지하면서 공평한 비교를 위해 Libriheavy로 학습시켰다.
제로샷 TTS 평가를 위한 데이터셋으로는 LibriSpeech test-clean과 VCTK를 사용한다.
먼저 LibriSpeech 데이터는 학습 데이터와 동일하게 LibriVox project를 통해 수집된 데이터이므로 in-domain 데이터이다. VALL-E 처럼 LibriSpeech test-clean에서 4-10초 사이 오디오만 사용하며 이는 40명의 화자에 대해 2.2 시간 분량의 녹음을 포함한다. LibriSpeech 실험에서는 3s Prefix as Prompt 라고 부르는 continuation 태스크와 Ref Utterance as Prompt 라고 부르는 제로샷 TTS 태스크를 수행하여 평가한다.
VCTK 데이터는 108명의 화자를 포함한 데이터셋으로 out-of-domain 데이터이다. VCTK에서는 3s, 5s, 10s로 프롬프트를 구성하여 평가한다.
그리고 두 가지 데이터셋으로 평가할 때 공통으로 AR 모델링에 single sampling과 five-time sampling을 적용하여 성능을 비교한다. single sampling은 말그대로 repetition aware sampling을 한번만 수행해서 나온 결과로 성능을 측정한 것이고 five-time sampling은 다섯 번 수행한 결과에서 베스트 성능을 기록하는 것이다. 이때, 베스트 성능을 고르는 방식으로 Sort on SIM and WER과 Metric-Wise Maximization을 사용한다.
- Sort on SIM and WER: 5개의 샘플이 나오면 SIM과 WER을 이용해서 정렬하는 방식으로, SIM이 0.3 보다 크면 WER을 기준으로 정렬하여 베스트 샘플을 선정하고 그 외의 경우에는 SIM을 기준으로 정렬하여 베스트 샘플을 선정한다.
- Metric-Wise Maximization: 5개의 샘플에 대해서 각 메트릭을 모두 계산하고 그 중 최고의 값들만을 선택하는 방식이다.
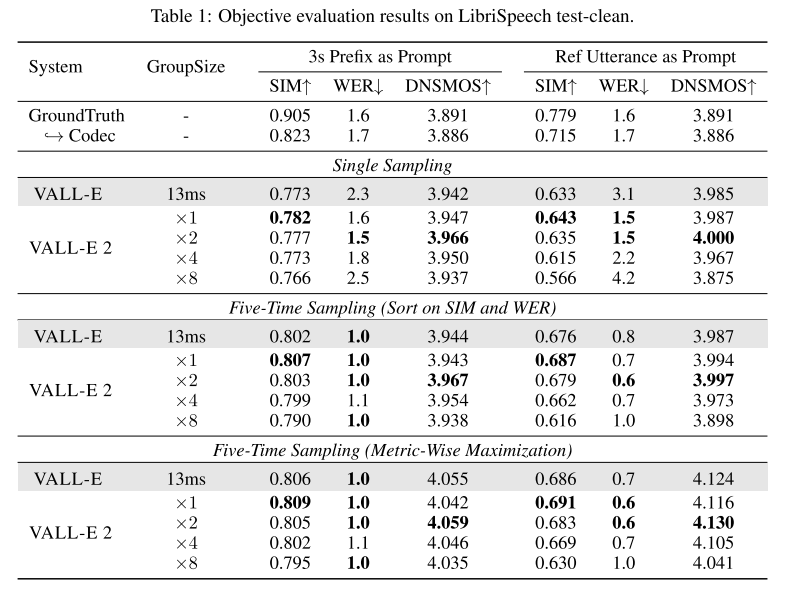
Table 1의 LibriSpeech objective result를 보면 VALL-E 2가 모든 세팅에서 VALL-E를 능가하는 것을 알 수 있다. 그리고 WER과 DNSMOS는 GT보다도 좋은 수치를 보여준다. 베이스라인인 VALL-E는 five-time sampling을 사용하면 대체로 준수한 성능을 보이지만, single sampling일 때 robustness가 부족한 결과를 보인다. 이는 AR 디코딩 과정에서 random sampling을 사용해서 생기는 불안정성 때문이라고 해석할 수 있다. 반면에 VALL-E 2는 single sampling을 사용하더라도 robustness가 준수하며, GT WER보다도 낮은 수치를 보여준다.
그리고 VALL-E 2는 그룹 사이즈 2를 사용하면 WER과 DNSMOS가 더 좋아진다. 따라서 grouped code modeling은 인퍼런스 효율을 증가시키는 것 뿐만 아니라 모델의 성능을 향상시킨다.
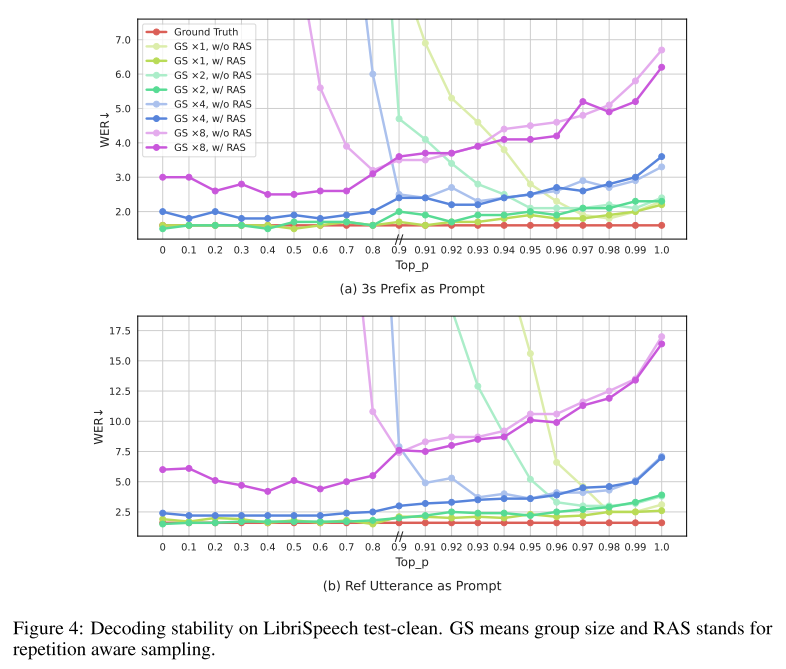
또한 Figure 4를 보면 repetition aware sampling이 모든 그룹 사이즈에서 디코딩 안정성을 크게 향상시킨다는 사실을 알 수 있다.
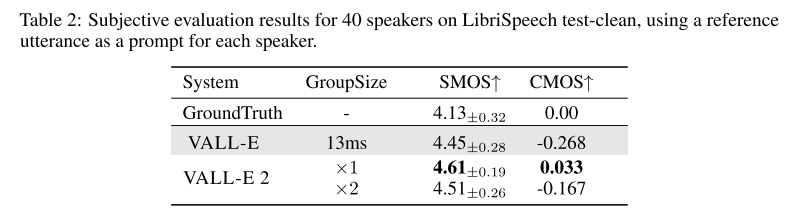
Table 2의 LibriSpeech subjective result를 보면 VALL-E 2가 VALL-E보다 SMOS, CMOS에서 앞서며, GT보다도 좋은 결과를 보여준다. 즉, LibriSpeech 제로샷 TTS에서 human parity에 도달했다.
어블레이션으로 2가지를 진행하는데 한가지는 model input에 대한 어블레이션이고, 다른 하나는 training data size에 대한 어블레이션이다.
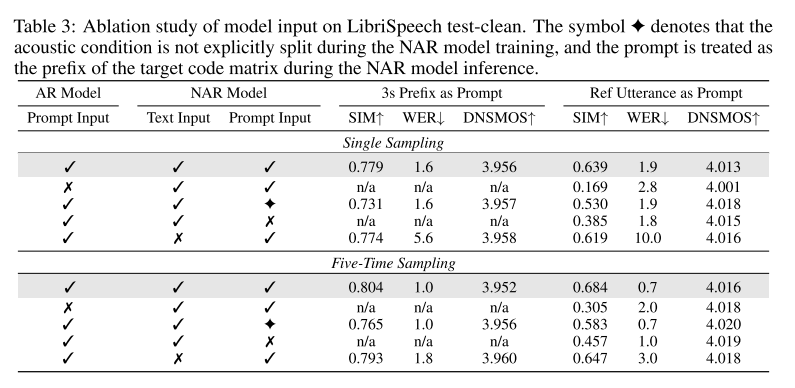
Table 3을 보면 AR과 NAR 모두에 프롬프트를 넣어주는 것이 화자 유사도에 중요한 역할을 한다. 그리고 NAR 모델에서 어쿠스틱 컨디션을 명확하게 분리하는 것도 화자 유사도를 위해 중요하다. 또 AR 모델에 텍스트 프롬프트를 넣는 것이 모델의 강건성에도 중요한 영향을 미치는 것으로 밝혀졌다.
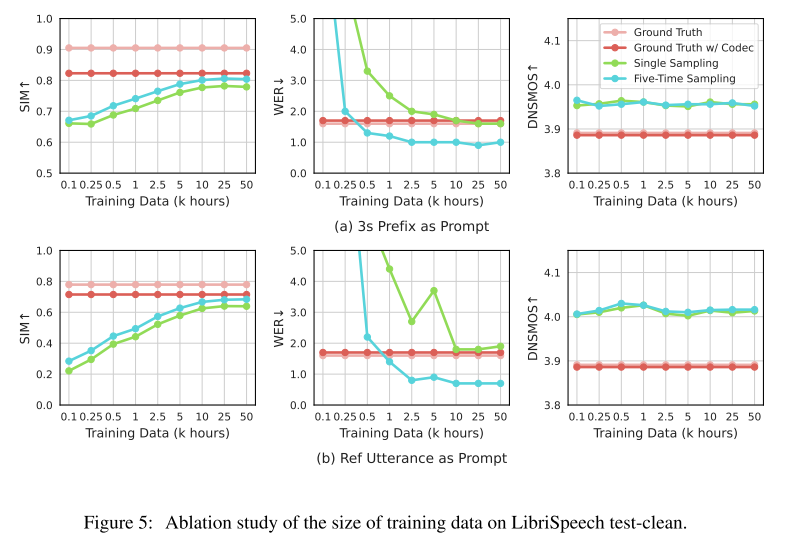
Figure 5를 보면 10k 시간만 사용해도 이미 50k와 비슷한 수준의 성능에 도달한 것을 알 수 있다. 그러나 10k 보다 적게 사용할 경우 Ref Utterance as Prompt 세팅에서 성능이 급격이 나빠진다.
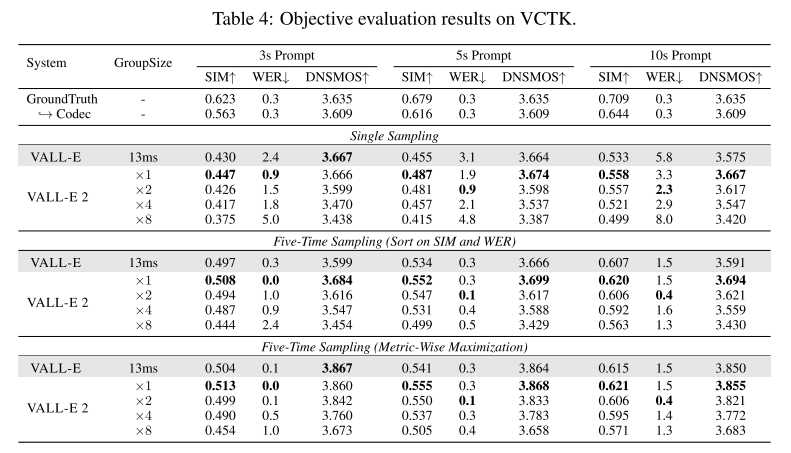
Table 4는 VCTK에서 objective result 이다. 이때도 LibriSpeech 실험과 비슷한 양상을 보여준다.
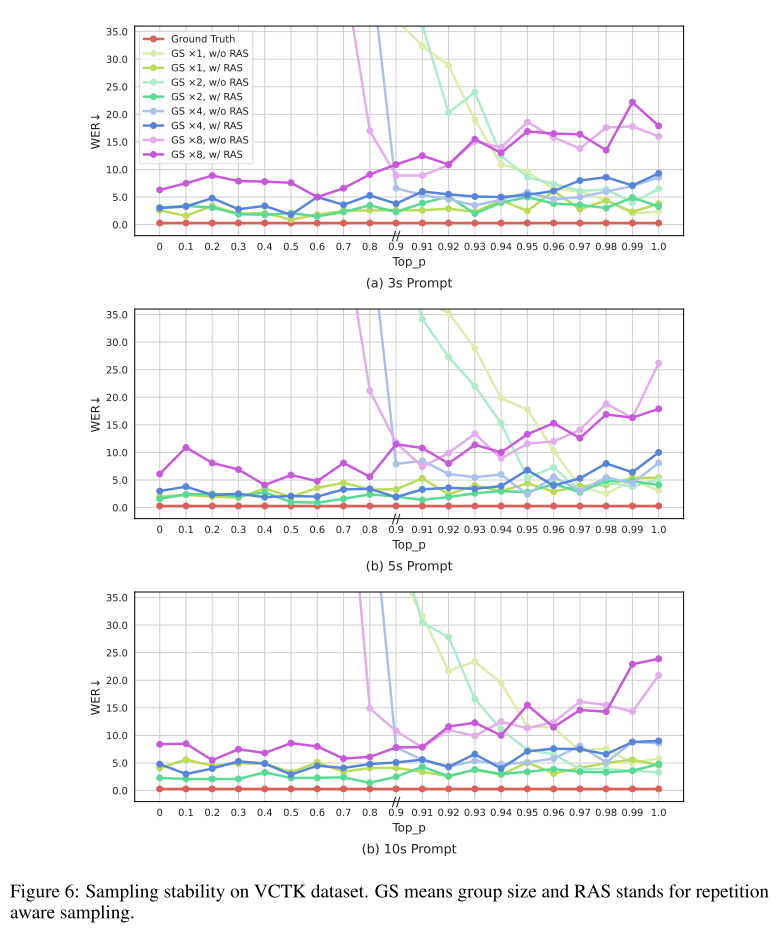
VALL-E 2의 디코딩 안정성은 Figure 6에서도 확인할 수 있다.
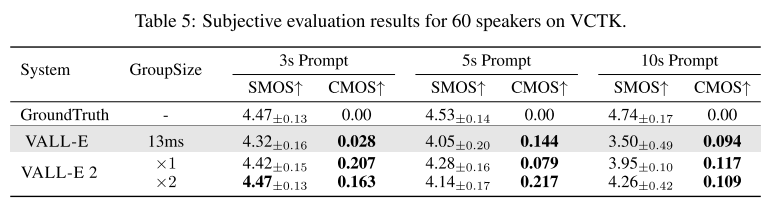
Table 5에서도 확인할 수 있듯이 VALL-E 2는 화자 유사도와 스피치 퀄리티 측면에서 모두 VALL-E를 능가한다. 심지어 3s 프롬프트를 사용할 때는 GT와 동등하거나 우월한 성능을 보여준다. 그러나 VCTK가 다양한 억양을 가지고 있는 어려움 때문에 5s, 10s 프롬프트 세팅에서는 GT 오디오의 화자 유사도를 넘어서지는 못한다. 하지만, grouped code modeling 덕분에 long context modeling이 가능해졌기 때문에 10s 프롬프트를 사용한 경우에도 VALL-E 보다 훨씬 높은 화자 유사도를 보여준다고 저자들은 말한다.
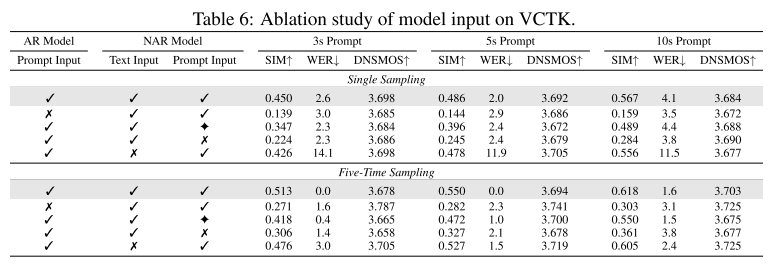
모델 입력에 대한 어블레이션 결과, LibriSpeech 실험과 동일하게 AR과 NAR의 프롬프트가 화자 유사도에 중요한 역할을 함을 알 수 있다.
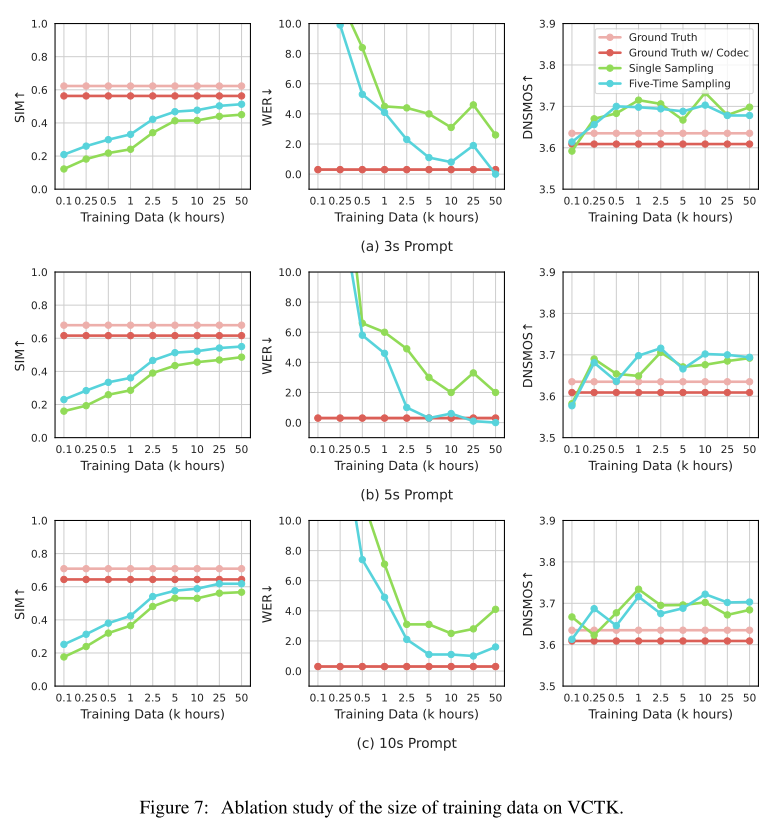
VCTK 실험에서 학습 데이터에 대한 어블레이션 결과는 프롬프트 길이와 메트릭에 따라 경향이 조금씩 다르다. SIM 은 어떤 경우든 데이터 사이즈가 클수록 높아진다. WER은 3s 프롬프트를 사용할 때 5s, 10s 프롬프트를 사용할 때보다 더 많은 데이터가 있어야 최고의 값을 갖는 경향을 보여주는데 이는 짧은 프롬프트만으로 처음 보는 화자의 특성을 반영하기가 더 어렵기 때문이다. 그리고 흥미롭게도 DNSMOS는 학습 데이터 크기가 최대일 때 최적의 값을 가지지 않는데, 저자들은 모델의 제한된 capacity 때문에 인지적인 퀄리티가 약간 저하되는 대신 더 나은 화자 유사도와 강건성을 높이는 방향으로 학습된다고 해석한다.
의견
- VALL-E R과 거의 동시에 나온 논문이고 일부 저자들이 겹치기도 하는데 서로 성능을 비교하지 않은 점이 의아하다.
- VALL-E 2와 같은 모델이 나오면서 이제 오디오북 스타일의 데이터셋에 대해서는 제로샷 성능이 포화 상태에 다다랐다는 생각이 든다. 과연 VALL-E 2가 spontaneous 스타일의 데이터셋에 대해서도 잘 적용될 수 있을지 궁금하다.
- 코덱 기반의 랭귀지 모델들이 sampling 방법만 바꿔도 색다른 퍼포먼스를 보여줄 수 있는 무궁무진한 발전가능성을 가졌다는 것이 큰 장점으로 느껴졌다.

Leave a comment