
VALL-E R
Han, Bing, et al. “VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment.” arXiv preprint arXiv:2406.07855 (2024).
들어가며
neural audio codec 모델의 도움으로 LLM이 제로샷 TTS를 위한 유망한 접근방식이라는 것이 알려졌다. 그러나 codec LLM의 AR 모델링에서 사용하는 sampling 기반 디코딩 전략이 생성물의 다양성을 보장해주는 반면에 오타, 누락, 반복과 같은 강건성 문제를 야기하기도 한다. 추가로 오디오의 샘플레이트가 높은 경우에는 AR 인퍼런스 과정에서 매우 큰 계산 비용이 발생한다. 따라서 VALL-E R에서는 phoneme monotonic alignment와 codec-merging을 사용해서 강건성 문제와 속도 문제를 각각 해결하고자 한다.
핵심 요약
- codec-merging을 사용해서 생성된 음성의 퀄리티와 코덱 모델 자체는 그대로 유지한 채, 퀀타이저 첫번째 레이어의 코드가 담당하는 샘플레이트를 낮추어 인퍼런스 속도를 향상시킨다.
- phoneme monotonic alignment를 제안하여 포님와 어쿠스틱 시퀀스 사이의 얼라인먼트를 강화하고 decoder-only 트랜스포머 기반 TTS 모델의 강건성을 높인다.
- VALL-E R은 포님 기반의 입력 메커니즘 덕분에 운율을 조절할 수 있다. 실험 결과에서 운율을 유지하면서 음색을 복제하는 voice conversion의 목적을 달성함을 보인다.
모델 구조
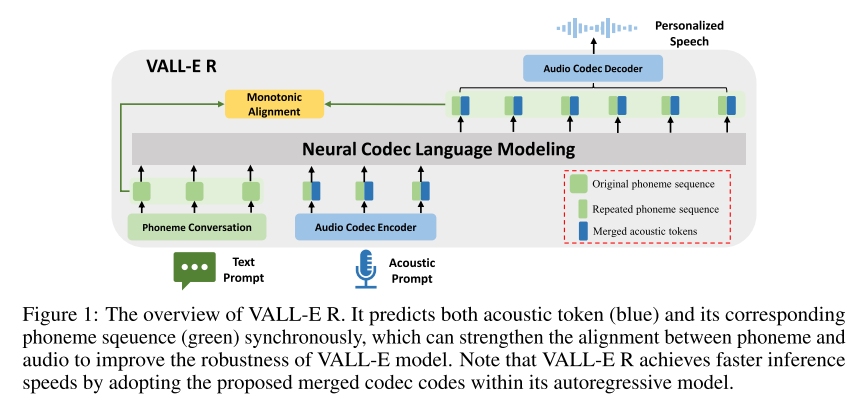
VALL-E 와는 달리 어쿠스틱 토큰만을 예측하지 않고 그에 해당하는 포님 토큰도 함께 예측하는 형태로 설계되었다. 이를 통해 포님과 오디오 사이 얼라인먼트가 견고해져 강건성 향상에 기여하게 된다. 또한 AR 모델에 codec-merging을 적용해서 인퍼런스 속도를 향상시킨다. 그리고 코덱 압축을 위해서 VALL-E와 동일한 세팅의 EnCodec을 사용하지만, 코덱 디코더로는 성능이 더 좋다고 알려진 Vocos를 사용한다.
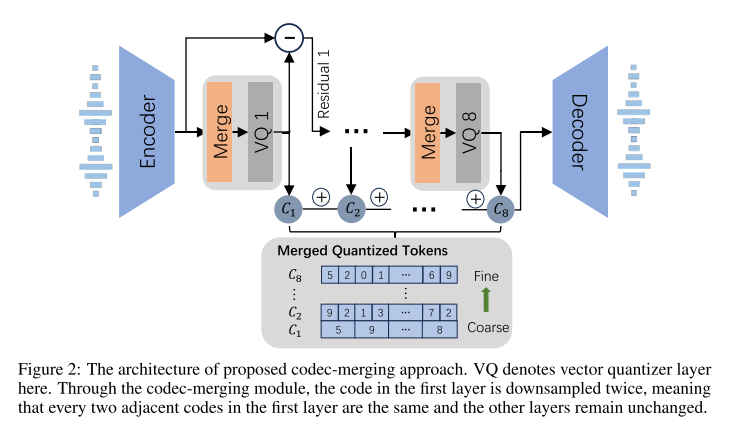
먼저 codec-merging이 적용되는 부분을 살펴보면 코덱 모델의 구조는 EnCodec과 동일하다. 다만 RVQ내에 VQ가 적용되기 전에 merge 모듈이 추가된다. 이 모듈은 residual 입력을 받아서 하이퍼파라미터로 정해진 비율(1/r)만큼 시간축으로 average pooling을 해서 다운샘플하고, 이를 r만큼 업샘플하여 원래 길이로 복원시킨다. 다운샘플 비율은 RVQ의 레이어마다 다르게 설정될 수 있고, merge 모듈은 각 레이어의 연속된 r개 프레임의 코드가 일관되도록 보장해줌으로써 해상도를 줄이는 역할을 한다.
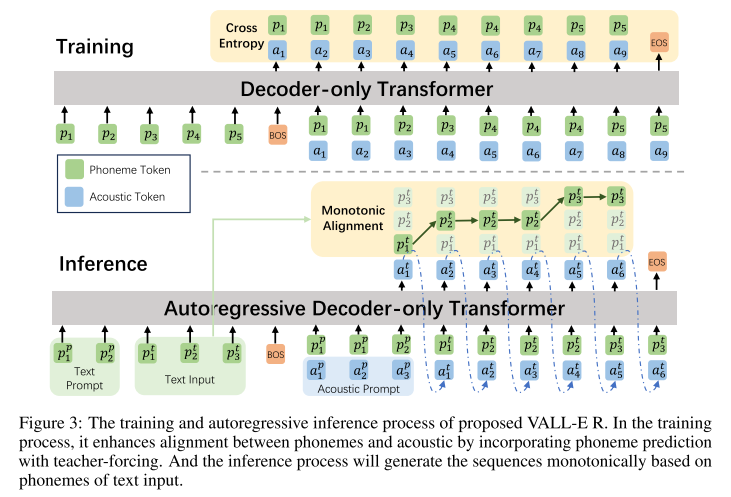
decoder-only 트랜스포머 모델의 monotonic alignment를 유도하기 위해서 저자들은 포님 예측을 LM 학습 과정에 통합시켰고, 인퍼런스 과정에 monotonic alignment 전략을 취한다.
그림 3에 나온 것처럼 학습할 때 어쿠스틱 토큰과 포님토큰이 얼라인되어 입력으로 들어가고, 얼라인은 외부 얼라이너인 MFA를 통해 구해진다. VALL-E R의 AR 과정에서는 codec-merging 모델의 첫번째 퀀타이저 토큰과 포님을 함께 예측하고, NAR 과정에서는 2-8번째 어쿠스틱 토큰만을 예측한다. VALL-E와 동일하게 어쿠스틱 임베딩과 최종 prediction layer의 파라미터는 공유한다. 즉, j번째 prediction layer의 weight는 j+1번째 어쿠스틱 임베딩의 weight와 동일하다.
인퍼런스 할 때는 프롬프트 텍스트와 합성할 텍스트가 포님으로 변환되어 함께 입력으로 제공되고, 어쿠스틱 프롬프트도 마찬가지로 컨디셔닝 정보로 쓰인다. 그리고 monotonic alignment 제약을 적용해서 매 스텝마다 예측된 포님이 합성할 텍스트 토큰 중 하나에 매핑되는데 현재 입력으로 들어온 텍스트 토큰를 유지하거나 아니면 한 포님만을 건너뛸 수 있게 한다. 이때 유지하거나 한스텝 움직일 확률은 베르누이 분포를 통해 구한다. VALL-E처럼 AR에서 어쿠스틱 토큰 예측에는 샘플링 기반의 디코딩 방식을 사용하고, NAR에서는 greedy search 방법을 사용한다.
정리하자면 VALL-E R은 인퍼런스 과정에서 monotonic alignment를 사용하여 다음과 같은 3가지 특성을 가진다.
- Locality: 각 포님 토큰은 하나 또는 연속의 몇몇 어쿠스틱 토큰에 할당될 수 있어, 유연하면서도 정확한 매핑을 보장한다. 반대로 어쿠스틱 토큰은 하나의 포님 토큰에 얼라인된다. 이러한 일대일 매핑은 발음 실수와 같은 오류를 효과적으로 예방하고, 모델의 명확성 및 안정성을 향상시킨다.
- Monotonicity: 포님 시퀀스와 그에 해당하는 어쿠스틱 시퀀스의 순서가 일치하고 이러한 얼라인먼트가 단어 반복을 본질적으로 방지하는 중요한 역할을 한다.
- Completeness: 각 포님 토큰이 적어도 하나의 상응하는 어쿠스틱 토큰으로 표현되도록 강제되어 있기 때문에 이러한 요구사항이 단어 누락을 방지한다.
VALL-E R은 외부적으로 포님을 모델링하기 때문에 만약 인퍼런스 시에 예측된 포님 시퀀스 대신에 미리 정해진 포님 시퀀스로 대체하게 되면 의도한대로 생성된 음성의 운율을 조정할 수 있고 운율과 음색을 별도로 조절할 수 있는 효과를 얻을 수 있다. 이는 소스 음성의 언어적 정보나 운율을 변경하지 않으면서 음색만 복제하고 싶은 voice conversion 태스크로 간주될 수 있다.
실험 결과
모델 학습을 위해서 960시간 규모의 LibriSpeech 데이터셋을 사용했다.
모델의 성능을 여러방면으로 평가하기 위해서 아래와 같은 평가 지표들을 사용한다.
- objective metrics
- robustness 및 intelligibility를 측정하기 위해서 Conformer-Transducer ASR 모델을 사용해 입력 텍스트와 합성된 텍스트 사이 WER을 계산한다.
- speaker similarity(Spk-Sim)를 측정하기 위해서 WavLM-TDNN 모델을 사용해서 음성을 하나의 벡터로 표현한 뒤, cosine similarity를 계산한다.
- sound quality를 측정하기 위해서 speech enhancement 분야에서 쓰이는 평가 지표들을 가져오는데 PESQ, STOI가 그것들이다.
- subjective metrics: MOS, SMOS, CMOS
강건성 비교를 위한 베이스라인 모델로는 VALL-E, VALL-T, ELLA-V를 비교하고 공정성을 위해 모든 모델은 동일하게 12-layer 트랜스포머로 구현된 뒤 LibriSpeech로 학습되었다.
효율성 비교를 위한 베이스라인 모델로는 AudioLM, VALL-E, ELLA-V, RALL-E, MusicGen 등을 사용한다.
Zero-shot Text-to-Speech tasks
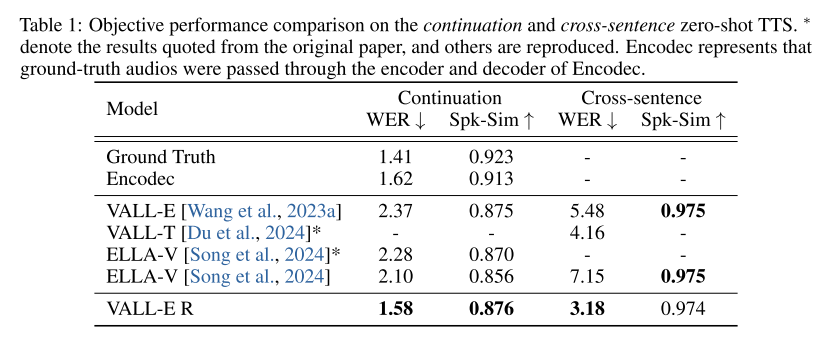
VALL-E처럼 continuation와 cross-sentence 세팅으로 제로샷 TTS 테스트를 진행했다. objective evaluation 부터 살펴보면 표 1에 나와있듯이 VALL-E R의 WER은 베이스라인들보다 우월한 수치를 보이고 Spk-Sim은 베이스라인들과 비교할만한 수치를 기록했다.
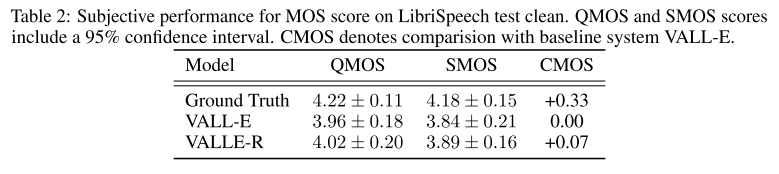
표 2에서는 subjective evaluation 결과를 보여주는데 VALL-E R이 quality, intelligibility, speaker similarity, naturalness, clarity 면에서 VALL-E를 앞서고 Ground Truth와 근접함을 알 수 있다.
Controllability of VALL-E R

VALL-E R은 인퍼런스 시에 예측된 포님 대신 임의로 원하는 포님을 넣어서 각 포님의 듀레이션을 조절할 수 있기 때문에 운율 조절이 가능하고 그렇게 인퍼런스한 모델을 VALL-E R-Prosody라고 부른다. 구체적으로 LibriSpeech test set에서 레퍼런스 음색을 제공해줄 오디오 샘플을 하나 골라서 어쿠스틱 프롬프트로 사용하고, 다른 오디오 샘플을 골라서 텍스트 프롬프트와 운율 레퍼런스로써 사용한다.
운율의 유사성을 측정하기 위한 지표로는 Mel Cepstral Distortion with Dynamic Time Warping and weighted Speech Length (MCD-DTW-SL)을 사용한다. 값이 작을수록 운율의 유사성이 높다는 의미이다.
표 3의 결과를 보면 VALL-E R-Prosody가 가장 낮은 MCD-DTW-SL을 기록하고 있으며 이는 레퍼런스 운율을 가장 잘 유지한채로 음성을 합성해낸다는 것을 의미하고 VALL-E R이 다른 모델들보다 더 나은 controllability를 가지고 있음을 보여준다.
Efficiency Comparison
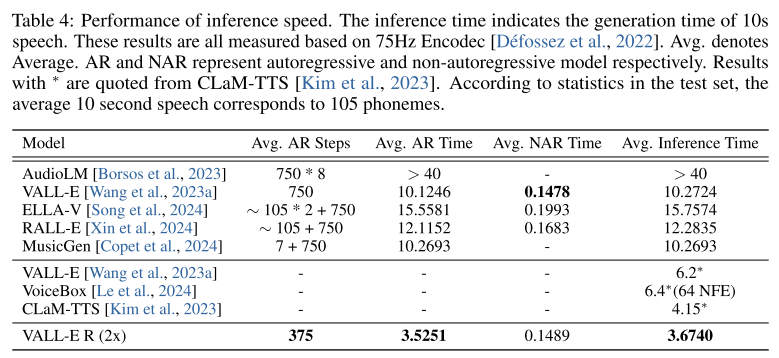
codec-merging의 efficiency를 체크하기 위해서 다른 neural codec language model들과 인퍼런스 속도를 비교했다. 표 4에서 말하는 인퍼런스 속도는 10초 오디오 즉, 750프레임을 생성하는데 걸리는 시간을 말한다. 첫 번째 퀀타이저 코드를 모델링하는 AR 모델에서만 2배 다운샘플링을 진행하는 VALL-E R이 AR스텝을 VALL-E에 비해 2배 줄이면서 AR 수행 시간을 줄이고 전체적인 인퍼런스 시간도 2배 이상 단축시킨 것을 알 수 있다. 이는 다른 베이스라인모델들과 비교해도 가장 빠른 속도에 해당한다.
Analysis and Discussion
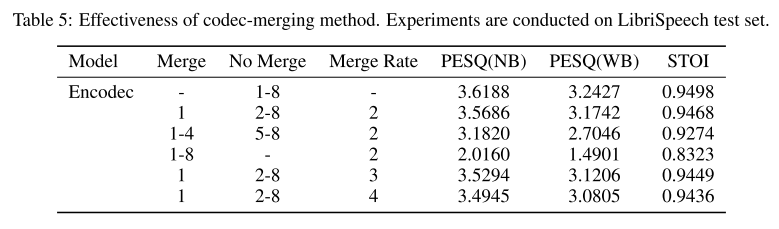
codec-merging 에 대한 어블레이션을 진행해보았는데 첫 번째 퀀타이저 결과에만 merging을 적용하는 것이 가장 적은 품질저하를 보였다.
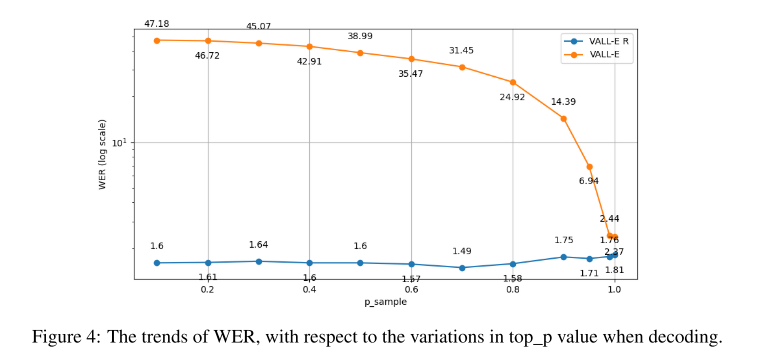
인퍼런스 시에 top_p를 조절해서 모델의 안정성과 강건겅을 테스트해보았다. VALL-E R은 monotonic alignment를 사용하기 때문에 안정적으로 문장을 생성해낼 수 있지만, VALL-E는 top_p가 줄어들수록 모델의 랜덤성이 줄어들면서 silent frame을 예측하는 경우가 많아지고 이에 따라 WER이 높아지는 결과를 보인다.
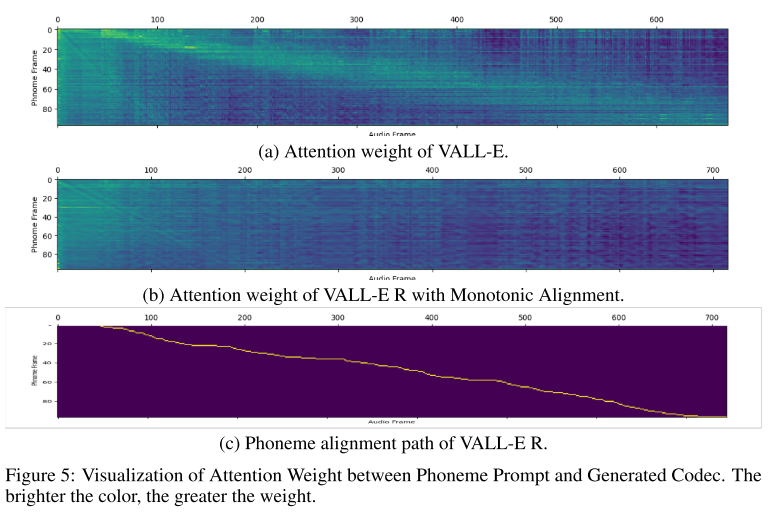
그림 5는 VALL-E와 VALL-E R의 AR모델 어텐션 웨이트를 시각화한 결과이다. VALL-E는 대각선으로 뚜렷하게 어텐션 웨이트가 높은 경향을 보이는데, 이는 매 스텝마다 어떤 포님에 집중해야하는지 알아야 하기 때문으로 해석한다. 그러나 오디오 길이가 길어질수록 어텐션이 주변으로 분산되기 때문에 발음 실수, 누락, 반복 등의 오류를 만들어낸다. 반면에 VALL-E R은 모든 포님에 균등한 어텐션 웨이트를 가지고 있다. VALL-E R은 명시적인 포님 정보를 제공받기 때문에 이러한 현상이 발생하며 덕분에 모델이 전체적인 텍스트 정보에 집중하며 오디오를 생성할 수 있다.
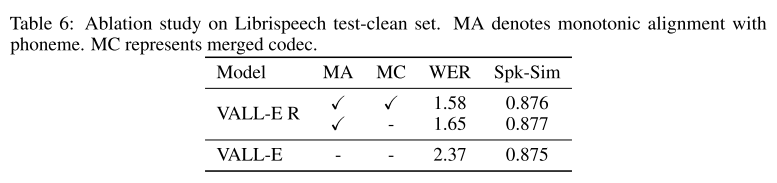
표 6은 codec-merging과 monotonic alignment를 순차적으로 제거하면서 어블레이션 스터디를 진행한 겨로가를 보여준다. 2가지 요소가 모두 WER과 Spk-Sim에 긍정적인 작용을 한다.
의견
- 학습 데이터 양이 VALL-E보다 적어진 것이 의아한데 이에 대한 설명이 없어서 아쉽다.
- AR 모델링 과정에서만 2배 다운샘플링을 진행해도 Flow matching을 사용한 VoiceBox 보다 속도가 빠르다는 점이 놀라웠다.
- 학습에 쓰이는 손실 함수에 대한 설명이 그림 3에만 간략히 나와있고 자세히 적혀 있지 않아서 아쉽다.




Leave a comment