
VALL-E X
Zhang, Ziqiang, et al. “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling.” arXiv preprint arXiv:2303.03926 (2023).
들어가며
VALL-E를 확장 시켜서 cross-lingual TTS가 가능한 모델 VALL-E X를 제안한다. 소스 언어의 음성과 타겟 언어의 텍스트를 프롬프트로 활용해 타겟 언어 음성의 어쿠스틱 토큰을 예측하는 multi-lingual conditional codec language model이라고 할 수 있다. VALL-E X는 VALL-E의 강력한 in-context learning 능력을 이어받아 zero-shot cross-lingual TTS와 zero-shot S2ST에 적용될 수 있다. 소스 언어로 녹음된 하나의 음성만으로 처음 보는 화자의 목소리, 감정, 그리고 음향 환경까지 복제하여 고품질의 타겟 언어 음성을 합성할 수 있다.
핵심 요약
- 대용량의 multi-lingual multi-speaker multi-domain unclean 음성 데이터셋을 이용해 cross-lingual neural codec language model을 제안한다.
- multi-lingual in-context learning을 통해 VALL-E X는 자연스럽게 처음 보는 화자의 음색, 감정, 백그라운드 노이즈를 유지한 채 cross-lingual 음성을 만들 수 있다.
- language ID를 함께 활용해서 cross-lingual TTS에서 잘 알려진 foreign accent 문제를 완화시킨다.
모델 구조
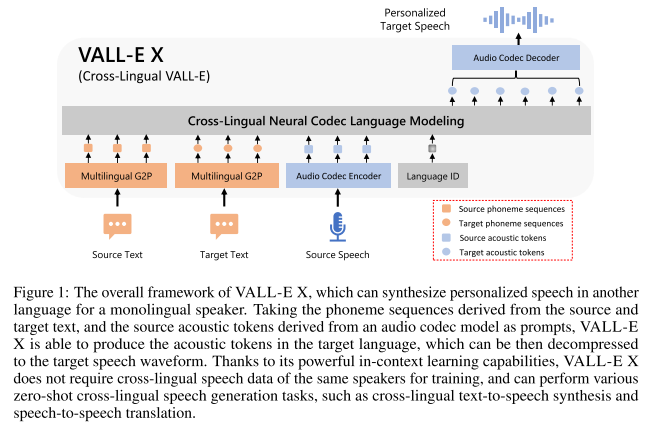
VALL-E에서 영감을 받아 multi-lingual AR codec LM과 multi-lingual NAR codec LM이 존재하고, 오디오 코덱 모델로 EnCodec을 사용한다. G2P는 IPA 기호에 기반한 BigCiDian의 포님 셋을 이용하여 영어와 중국어를 통합된 기호체계로 변환한다.
AR 모델은 포님 시퀀스를 받아서 EnCodec 첫번째 퀀타이저의 어쿠스틱 토큰을 예측하도록 학습된다. NAR 모델은 현재 문장의 포님 시퀀스와 같은 화자가 발화한 다른 문장의 어쿠스틱 토큰 시퀀스를 프롬프트로 받는다. 여기서 어쿠스틱 토큰 시퀀스는 현재 문장과 동일한 문단에서 분할된 문장에서 가져오는데, 이유는 현재 문장과 비슷한 음성 특성 (화자, 속도, 배경음 등)을 가질 것으로 기대할 수 있기 때문이다.
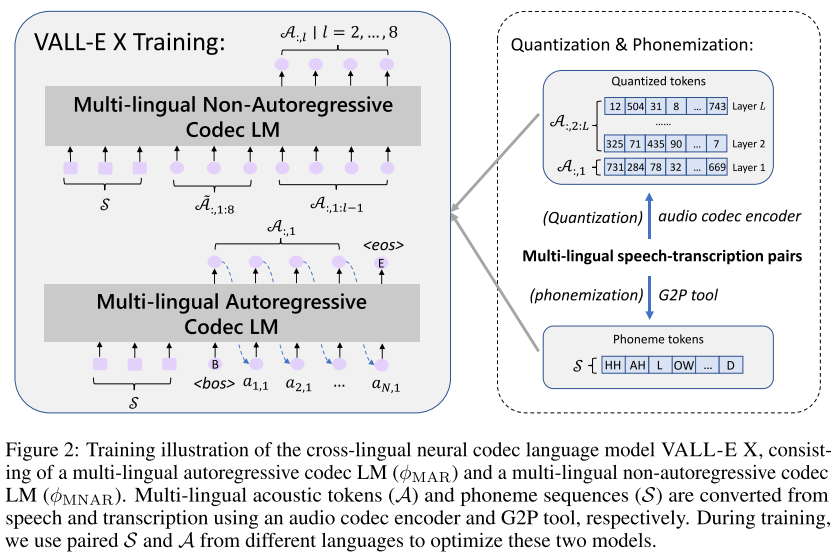
multi-lingual 데이터로 학습할 때, 모델이 cross-lingual 음향 변환을 배우게 하기 위해 같은 화자가 두 가지 언어를 녹음한 bilingual ASR 코퍼스를 적극 활용하며, language ID도 추가해 준다. 저자들은 AR 모델에서 language ID 임베딩을 어쿠스틱 토큰에 더해주는 방식으로 컨디셔닝을 해줬으며, 이를 통해 언어에 따른 발화 스타일을 정확하게 가이드해줄 수 있었고 L2 accent 문제를 완화할 수 있었다고 말한다.
모델을 인퍼런스 할 때는 소스 언어의 포님, 타겟 언어의 포님, 그리고 소스 음성의 첫 번째 퀀타이저 어쿠스틱 토큰을 프롬프트로 사용하여 AR 모델이 타겟 음성의 첫 번째 퀀타이저 어쿠스틱 토큰을 예측한다. 이때 디코딩 방법으로 확률 기반 샘플링을 사용한다. 그렇게 <eos> 토큰이 샘플링 될때까지 AR 모델링을 수행한 뒤에 language ID를 더해준다.
NAR 모델은 AR 모델의 출력을 이어받아 타겟 언어의 포님, 소스 음성의 코드 매트릭스, 그리고 이전 레이어에서 예측한 타겟 음성의 코드 매트릭스를 활용하여 현재 레이어의 타겟 음성 코드 매트릭스를 예측한다. 여기서 디코딩 방식은 greedy search로, 가장 높은 확률을 가진 토큰을 선택하는 방식이다. NAR 모델을 최적화 할 때, 모든 레이어의 로스를 누적시키지 않고 효율성을 위해 한 레이어를 임의로 선택하여 모델을 업데이트한다.
최종적으로 EnCodec의 디코더를 사용하여 타겟 음성의 코드를 waveform으로 바꾸게 된다.
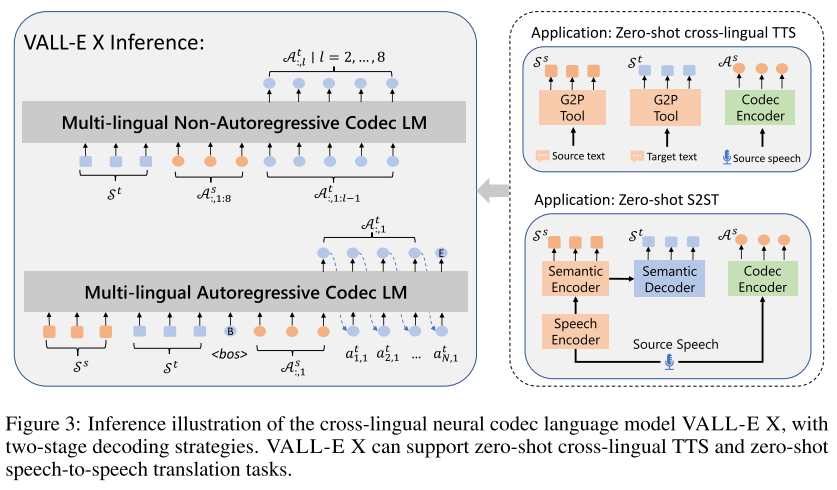
VALL-E X는 논문에서 그림 3과 같이 2가지 application으로 소개되고 있는데 구체적인 구현 방법은 아래와 같다.
- zero-shot cross-lingual TTS
- G2P를 사용해 소스 텍스트와 타겟 텍스트를 각각 포님으로 변경한 뒤, 위에서 설명한 인퍼런스 절차를 따른다.
- zero-shot speech-to-speech translation (S2ST)
- speech recognition과 translation을 위해 SpeechUT 모델을 개선시켜 사용하는데, 구체적으로 hidden unit을 포님으로 바꿔서 사전학습시킨다. 이 모델은 speech encoder, phoneme encoder, phoneme decoder로 구성되어 있다.
- 사전학습된 SpeechUT는 그대로 사용하지 않고 (소스 음성, 소스 텍스트, 타겟 텍스트) 쌍을 이용해 파인튜닝도 수행한다.
- 따라서 인퍼런스 시에 소스 음성이 들어오면 speech encoder를 통해 인코딩된 시퀀스가 phoneme encoder를 통해 소스 포님 시퀀스로 변환되고, 소스 포님 시퀀스는 phoneme decoder를 통해 타겟 포님 시퀀스로 변환된다. 그리고 EnCodec의 인코더를 통해 소스 음성이 코드 시퀀스로 변환되어 프롬프트로 함께 입력된다.
실험 결과
VALL-E X는 영어와 중국어 데이터로 학습되었는데 영어는 LibriLight (60,000 시간), 중국어는 WenetSpeech (10000+ 시간) 데이터셋을 사용하였다. 또, S2ST 모델을 학습시키기 위해서 추가적으로 machine translation (MT) 과 speech-to-text translation (ST) 데이터를 사용했는데 MT 데이터로는 AI Challenger, OpenSubtitles2018, WMT2020을 사용했다. 영어→중국어 ST 데이터는 GigaST를 사용했고, 중국어→영어 ST 데이터는 WenetSpeech를 자체 모델로 번역한 것을 사용했다. zero-shot cross-lingual TTS를 테스트하기 위해서 LibriSpeech dev-clean과 EMIME 데이터셋을 사용하며, S2ST는 EMIME 데이터셋을 사용해서 테스트한다.
실험 결과에서 cross-lingual TTS model은 VALL-E X, S2ST 모델은 VALL-E X Trans라고 표기한다. zero-shot cross-lingual 베이스라인 모델은 YourTTS를 사용하고, S2ST 베이스라인은 ASR → MT → YourTTS로 이어지는 cascaded S2ST를 사용한다.
Zero-shot cross-lingual TTS
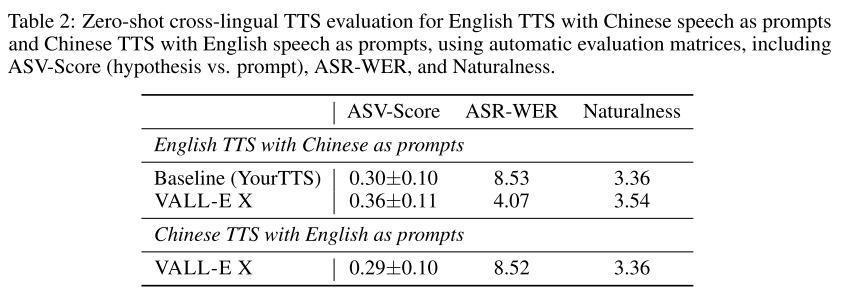
ASV-Score는 speaker similarity를 평가하기 위한 지표로 VALL-E와 같이 WavLM 기반 모델을 사용한다. ASR-WER은 speech quality를 나타내는데 HuBERT-Large 기반 ASR 모델을 사용하여 WER을 계산한다. ASR-BLEU는 translation quality를 평가하기 위한 지표로 쓰인다. 그리고 naturalness는 NISQA-TTS로 예측된 MOS 점수이다.
표 2의 objective evaluation 결과를 보면 VALL-E X가 영어 합성에서 베이스라인보다 뛰어나다는 것을 알 수 있다. 베이스라인인 YourTTS가 중국어를 합성할 수 없기 때문에 중국어 합성은 VALL-E X의 결과만 기록되어 있다.

사람이 점수를 매긴 subjective evaluation 결과를 봐도, VALL-E X가 베이스라인보다 speaker similarity가 높고, speech quality도 상대적으로 좋다는 결론이 나온다.
Zero-shot speech-to-speech translation (S2ST)
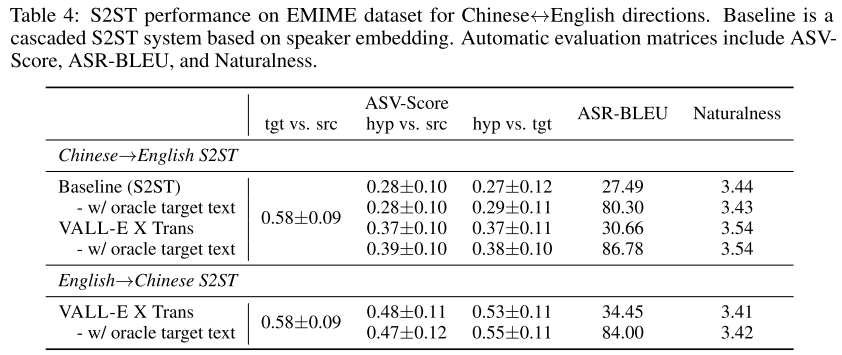
먼저, speaker similarity 부터 살펴보면 EMIME의 chinese-english paired speech utterance를 활용해서 3가지 ASV-Score를 제시하고 있다. 중국어에서 영어로 번역이 되는 경우에 VALL-E X Trans가 베이스라인을 앞서는 모습을 확인할 수 있지만 상한으로 생각할 수 있는 tgt vs src 점수에는 아직 많이 모자라는 결과를 보여준다. 그리고 번역으로 나온 예측 텍스트로 TTS하는 것이 아니라 ground truth를 제공해줬을 때 (cross-lingual TTS와 같아짐) 결과가 어떻게 다른지 보면, speaker similarity에는 미미한 차이가 나타나는 것을 알 수 있다.
translation quality 측면에서는 ASR-BLEU를 보면 되는데 여전히 베이스라인보다 앞서는 모습을 보여주지만, 상한선인 84~87 보다는 점수가 낮다. speech naturalness도 베이스라인보다 높으므로 VALL-E X Trans가 더 자연스러운 번역 음성을 생성할 수 있다.
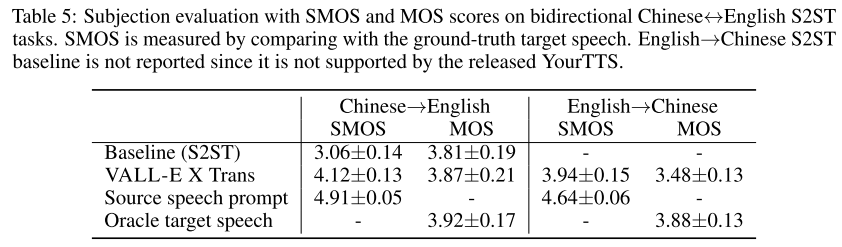
사람들의 평가를 봐도 VALL-E X Trans가 speaker similarity와 speech quality 측면에서 베이스라인을 앞서는 것을 알 수 있다.
Effect of Language ID
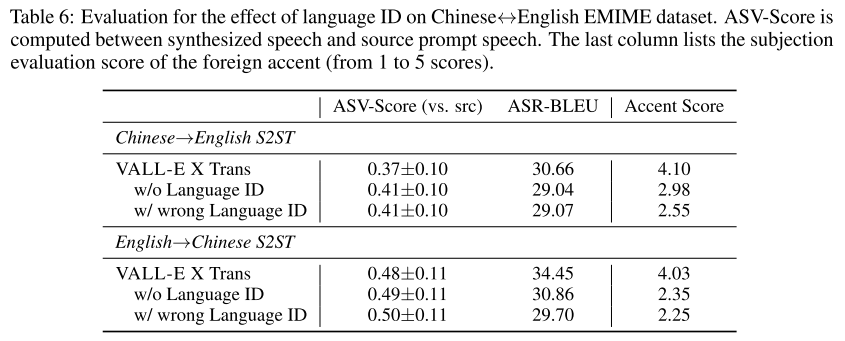
Language ID (LID)의 효과를 분석하는 어블레이션 실험 결과이다. LID를 빼거나 잘못된 LID를 넣어주면 소스 음성과의 speaker similarity는 높아지지만 translation quality가 떨어지는 것을 알 수 있다. 따라서 LID가 컨텐츠의 정확도를 높이는데 기여할 수 있지만, 동시에 타겟 LID가 정보의 전달을 줄이는 역할을 한다는 점도 저자들은 지적하고 있다.
Foreign Accent Control
L2 accent problem, 즉 합성된 음성이 원어민스럽지 않고 외국인답게 accent를 내는 것이 cross-lingual TTS에서는 해결해야할 문제 중 하나이다. 저자들은 사람의 평가를 통해 합성된 음성에 accent score를 매기게 하였고 그 결과 VALL-E X Trans가 L2 accent problem을 완화해준다는 결론을 얻었다.
Voice Emotion Maintenance
EmoV-DB를 통해 소스 음성의 감정이 유지되는지 테스트 해보았고, 이는 S2ST 연구에서 최초로 행해진 것이다. VALL-E X가 소스 음성과 합성 음성 사이에서 어느 정도 감정적 일관성을 유지할 수 있다는 것이 발견되었고, 이는 모델의 대용량 학습 데이터에 감정 표현이 풍부한 음성들이 다양하게 있었기도 하고 VALL-E X의 강력한 in-context learning 능력 덕분이라고 저자들을 해석한다.
Code-Switch Speech Synthesis
한 문장 내에서 언어가 섞여 있는 code-switching도 테스트 해보았다. VALL-E X는 monolingual 데이터만을 이용해서 학습되었고, code-switching이 가능해지도록 특별한 최적화를 적용하지 않았지만 일관된 목소리로 code-switching을 훌륭하게 해낸다.
의견
- VALL-E와 많은 부분이 비슷한 것 같으면서도 프롬프트에 어떤 정보를 제공해줘야 하는지 고심한 흔적이 보여서 훌륭한 연구라고 생각한다.
- 영어와 중국어로만 테스트가 되어서 아쉽고, 다른 언어들에 대한 결과도 궁금하다.
- code-switching 합성 데이터를 모으기 위한 용도로 적합해 보인다.

Leave a comment