
VoiceMe
van Rijn, Pol, et al. “VoiceMe: Personalized voice generation in TTS.” arXiv preprint arXiv:2203.15379 (2022).
들어가며
TTS 기술이 발전하여 모델 학습 때 쓰이지 않았던 완전히 새로운 목소리를 만드는 것이 가능해졌지만, 개인화된 목소리를 만드는 것은 여전히 어려운 일이다. 저자들은 고차원의 화자 임베딩 공간에서 개인화된 음성을 찾기 위해 화자 인식 모델의 사전 학습된 화자 임베딩을 사용하는 방법을 제안한다.
이 연구는 사전 학습된 임베딩 값을 반복 조절하는 방식으로 사람의 얼굴이 담긴 사진, 초상화, 만화 등의 이미지와 어울리는 목소리를 생성할 수 있어서 오디오북이나 게임 캐릭터 목소리 생성, 음성 비서 목소리 개인화, 언어 장애를 가진 사람들의 목소리 생성 용도로 활용될 수 있다.
음성 개인화 문제를 화자 생성 모델로 풀고자 한 최초의 시도인 연구에 대해 더 자세히 알아보자.
핵심 요약
- 화자 생성 모델이 발전해 오면서 새로운 목소리를 만들 수 있게 되었지만 무작위의 목소리가 아닌 사람의 인식과 유사한 음색을 생성하는 것은 여전히 어렵다.
- 본 연구는 화자 임베딩 공간에서 human-in-the-loop 라는 반복 샘플링 기법을 활용해 얼굴과 목소리 사이의 관계를 맵핑하려는 시도이다.
- 제안하는 방법으로 생성된 목소리들이 주어진 얼굴 이미지와 강한 유사성을 가진다는 것이 실험을 통해 증명되었다.
모델 구조
모델은 VITS(TTS model) + SpeakerNet(Speaker encoder) + GST(Style encoder) + HiFi-GAN(Vocoder)으로 구성되어 있고 도식화 하면 아래 그림과 같다.
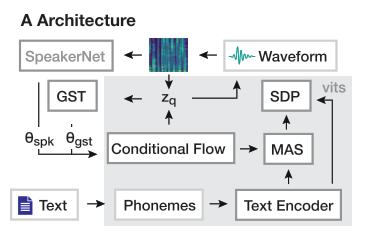
화자 임베딩을 뽑기 위해 SpeakerNet-M 모델이 쓰였으며, 이 모델은 총 7,205명의 화자 인식 데이터로 사전 학습 되었다. 그리고 저자들은 SpeakerNet이 운율(prosody)이 아닌 음성의 피치(pitch)와 음색(timbre) 정보를 주로 인코딩한다는 사실을 발견하여 운율(스타일)을 임베딩할 수 있는 GST를 네트워크에 추가하였다.
학습 시, 화자 임베딩과 스타일 임베딩은 각각 L2-norm 이후 concat 되어 VITS의 Flow 기반 디코더에 condition 정보로 쓰인다. 학습이 끝나고 인간 샘플링 실험을 통해 목소리를 생성할 때는 샘플간 운율에 차이가 없도록 하기 위해 스타일 임베딩으로 0을 사용하였다고 한다.
학습 방법
Adversarial Learning 사용
- 목적: GST가 화자 의존적인 특성을 배우게 되는 것을 방지하기 위함이다.
- Discriminator 추가: 별도의 feed-forward 네트워크를 구성하여 스타일 임베딩으로부터 화자 임베딩을 재건하도록 훈련시킨다.
- Discriminator는 실제 화자 임베딩과 재건된 화자 임베딩 사이의 코사인 유사도를 최소화하도록 목적 함수를 아래와 같이 구성하여 파라미터를 업데이트하고,
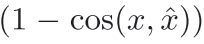
- Generator(GST)는 Discriminator에 의해 재건된 화자 임베딩이 실제 화자 임베딩과 유사하면 패널티를 주도록 목적 함수를 구성하여 파라미터를 업데이트한다.
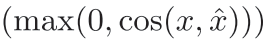
Transfer Learning 사용
- VCTK 데이터셋으로 사전 학습된 VITS 모델의 체크포인트를 사용했다고 한다.
- 초반 400k 스텝은 discriminator만 학습하고 그 이후 2M 스텝은 learning rate 1e-4로 낮춰서 학습한다.
샘플링 방법
Gibbs Sampling with People (GSP)
본문에서 human-in-the-loop 라고도 묘사되는 Gibbs Sampling with People (GSP)라는 방식을 사용한다. 이름에서 알 수 있듯이 결합 확률 분포에서 하나의 변수만을 변경해가면서 표본을 샘플링하는 방식인 Gibbs Sampling을 변수들간의 조건부 확률에 기반한 확률 과정으로 진행하는 것이 아니라 여러 사람의 판단을 개입시켜 진행하는 샘플링 알고리즘이다. 구체적으로 말하자면 실험 참여자가 화자 임베딩 값을 한 축으로 이동시킬 수 있는 슬라이더를 조절하여 합성된 음성을 들어보고 타겟 얼굴과 가장 매치가 잘되는 음성이라 생각되면 멈춘 다음, 다른 축과 연결된 슬라이더를 조절하는 연쇄과정을 진행한다.
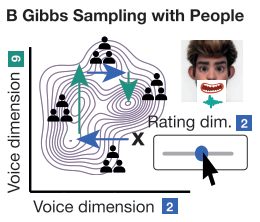
본 연구에서는 각 iteration마다 참여자 3명의 응답을 기록하여 평균을 내면서 임베딩 값을 수정해 나갔다. 이 때 사용한 임베딩 공간의 축은 PCA를 통해 뽑아낸 principal component들이고, 사전 실험을 통해서 principal component들이 직관적인 해석 가능성을 가지고 있음을 확인했으며 일례로 PC2는 성별과 관련된 축이었다고 한다. 또한, 관련 연구에서 10개의 principal component만 사용해도 의미있는 조절이 가능하다고 제안하여 본 실험에서도 10개만 사용한다.
principal component를 계산하기 위해 사용된 SpeakerNet의 임베딩은 English CommonVoice 데이터셋 내 45,825명의 동일 문장 발화 음성으로부터 추출하였다. 슬라이더는 현실적인 이유로 31개의 위치로 균등하게 나누었으며, 좀 더 자연스러운 음성을 만들 수 있도록 Wav2Lip을 이용한 립싱크 영상까지 확인할 수 있는 파이프라인을 고안하였다.
Stimuli
개인화된 음성과 실제 음성을 비교해보기 위해서 RAVDESS 데이터셋의 24명 화자 이미지와 음성에서 추출한 화자 임베딩을 ground truth로 사용한다. 데이터셋 내에 여러 감정을 가진 음성이 있지만 24명 모두 동일한 문장을 중립적으로 발화한 음성을 사용하였다.
더 나아가서 실제 얼굴이 아니어도 제안한 기법이 잘 적용될 수 있는지 확인하기 위해서 실제 이미지를 스타일 트랜스퍼를 활용해 만화(toonify)와 초상화(AI Gahaku: OR, EX3, R00/P00) 스타일로 바꾼 이미지도 실험에 사용하였다. 즉, 한 화자에 대해서 이미지 5개(원본 + 4개 스타일)씩을 사용했으므로 총 120개의 실험이 구성되었다. 한 실험당 (음운적으로 균형을 이루고 의미적으로 중립적인) Harvard 문장 720개 중 하나를 무작위로 샘플링하여 추론용 문장으로 사용하였다.
실험 결과
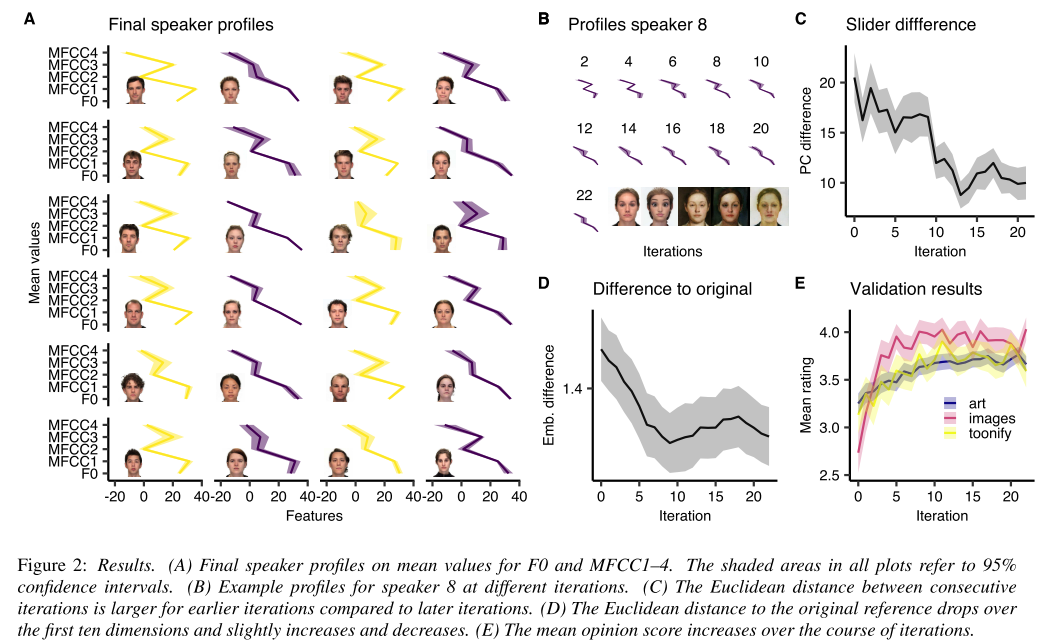
A. 실험 종료 시점에 뽑은 화자 24명의 profile. F0가 성별에 따라 확연히 다르다.
B. iteration에 따른 한 화자의 profile 변화. 초반에 빠르게 변하고 후반부에 가서는 수렴하는 양상을 보여준다.
C. iteration에 따른 slider 위치 변화. 초반에는 slider를 크게 움직이지만 후반부로 갈수록 적게 움직이는 것을 알 수 있다.
D. iteration별 생성된 화자 임베딩과 ground truth 사이 difference 그래프. 초반 10 iteration 동안 급격히 떨어지다가 완만하게 오르고 다시 떨어지는 양상을 보여준다. 결국 ground truth와 가까워진다.
E. 이미지 스타일별 iteration에 따른 MOS 변화. 실제 사진이 가장 빠르게 MOS가 향상되고 가장 높은 수치인 4.0을 기록한다.
임베딩 특성 분석
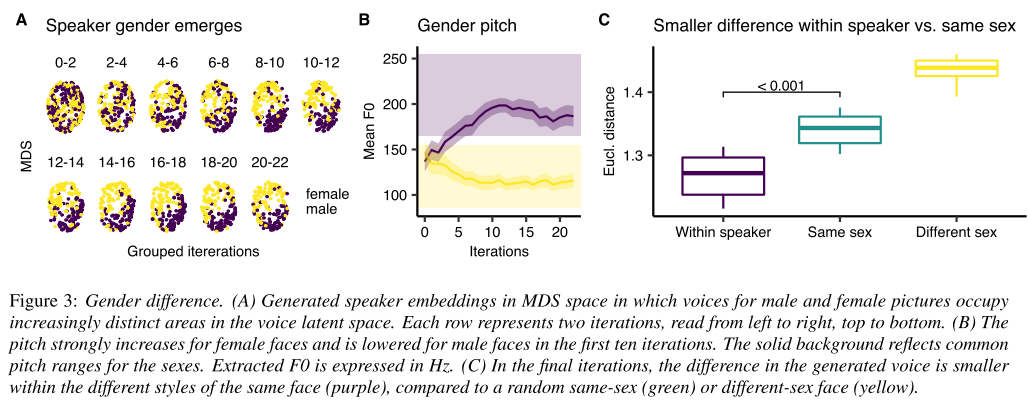
A. 실험 참여자들이 이미지의 어떤 특성에 주목해서 화자 임베딩을 만들었는지 확인하기 위하여 Multi Dimensional Scaling (MDS)으로 모든 음성들을 시각화하였다. iteration이 진행될수록 성별에 따라 임베딩 구역이 명확하게 나뉘는 것이 보인다.
B. MDS 뿐만 아니라 iteration에 따른 gender pitch 그래프도 화자의 이미지에서 성별 정보가 음성을 통해 잘 복원되었음을 보여준다.
C. 그렇다면 사람들이 성별에만 집중하여 목소리를 생성하였는지 알아보기 위해 성별과 화자에 따른 임베딩 값의 euclidean distance를 계산했는데, 같은 화자의 다른 스타일(만화, 초상화 등) 사이에서 가장 작은 distance가 나타났다. 즉, 화자 임베딩이 성별뿐만 아니라 얼굴에서 나타나는 사람의 아이덴티티와 관련된 특징도 담아내는 것으로 해석된다.
의견
- SpeakerNet이 prosody 정보는 인코딩하지 못한다는 생각에 대한 근거나 레퍼런스 논문을 첨부해주었다면 모델 설계에 더 신뢰가 갔을 것 같다.
- GSP에서 사용하는 임베딩 값을 무작위로 초기화하지 말고 화자 이미지에서 추출한 정보를 이용해 초기화할 수 있는 모듈을 추가한다면 수렴을 위한 iteration 수가 줄어 사람의 개입을 줄일 수 있겠다.
- 데모 코드를 실행시켜 테스트를 해봤는데 PCA 축마다 어떤 특징을 표상하고 있는지 분명하지 않은 경우가 많아서 아쉽다.

Leave a comment