
Wave-Tacotron
Weiss, Ron J., et al. “Wave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
들어가며
대부분의 딥러닝 모델을 활용한 음성합성 연구는 텍스트로부터 멜 스펙트로그램을 뽑아내는 합성 모델과 이로부터 오디오를 만들어내는 보코더의 두 갈래로 나뉘어서 진행된다. 이렇게 2-step으로 접근하는 방식이 end-to-end TTS를 쉽게 만들어주기는 했지만, 모델의 훈련과 추론을 복잡하게 할 수 있다. 왜냐하면 최고 품질을 달성하기 위해서는 일반적으로 합성 모델의 약점으로 인해 보코더에 대한 fine-tuning과 훈련이 필요하기 때문이다.
따라서 본 논문에서는 텍스트에서 오디오의 파형을 곧바로 생성해내는 spectrogram-free 모델인 Wave-Tacotron을 제시한다. 파형의 위상 같이 강력한 시간 의존성을 나타내는 특성을 효율적으로 모델링하는 것이 어렵기 때문에 쉬운 과정은 아니지만 본 논문에서는 normalizing flow를 이용하여 모델링하는 시도를 하였고 이 모델로 다른 TTS모델들과 견줄만한 품질의 음성을 합성할 수 있음을 보인다.
핵심 요약
- Tacotron과 Normalizing flow를 활용하여 스펙트로그램 없이 text-to-waveform이 가능한 TTS 모델을 만들었고, 이로부터 합성된 음성이 기존의 2-step 방식으로 합성한 음성과 비슷한 품질을 보인다.
- 손실함수는 간단하게 likelihood를 통해 구성된다는 장점이 있다.
- 자기 회귀적인 본 모델 구조의 특성상 하이퍼파라미터 설정에 따라 모델의 성능이 크게 좌우될 수 있다.
모델 구조
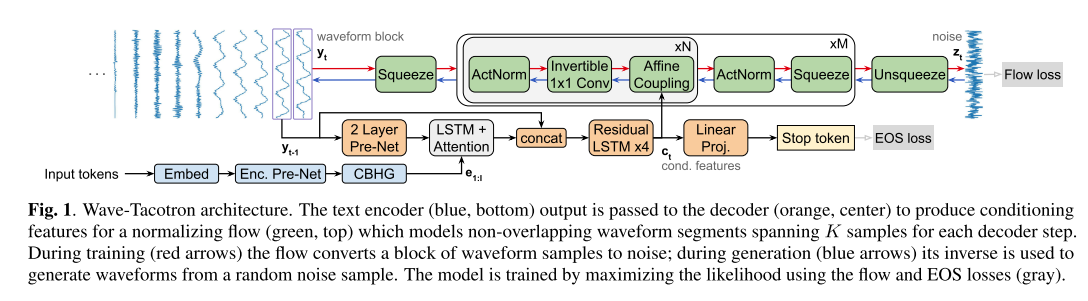
전체적인 모델의 구조는 위와 같고 Tacotron 1,2와 Glow를 합친듯한 형태이다.
인코더
인코더는 CBHG와 pre-net으로 이루어져 있고, 이는 Tacotron 1에서 차용한 구조다.
디코더
디코더는 인코딩된 벡터와 이전 시점까지의 파형벡터를 받아서 컨디셔닝 벡터를 뽑아내고 이 벡터가 노이즈로부터 현 시점의 파형 샘플을 만들어내기 위한 normalizing flow에 컨디셔닝 정보로 쓰이게 된다. 이를 수식으로 쓰면 아래와 같다.
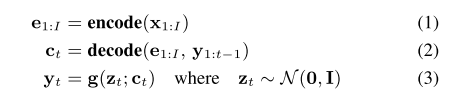
그리고 디코더에서 나온 컨디셔닝 벡터를 linear classifier에 통과시켜서 마지막 토큰(stop token)인지 아닌지 확률을 계산하게 되는데 이 파트는 Tacotron 2에서 똑같이 활용되는 부분이다.
마지막으로 디코더의 입력을 pre-net과 어텐션을 거친 벡터와 합쳐주는 skip connection을 적용했는데 이는 최종적으로 예측하는 파형 샘플 블록들 사이의 경계를 부드럽게 이어주는 역할을 하는 데 필수적이라고 한다.
Flow
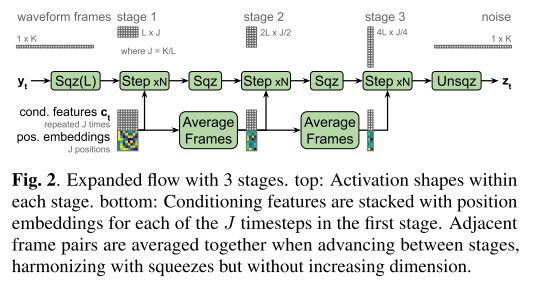
위의 그림에서 나타나는 것과 같이 모델을 학습시킬 때는 크게 3단계를 거치면서 파형 블록이 노이즈로 바뀌어 가는데 각 단계는 squeeze와 Glow를 이용해 다른 시간적 해상도를 갖고 진행된다. 그리고 생성을 할 때는 위의 역과정이 일어난다. (normalizing flow가 invertible한 특징을 갖고 있기 때문에 가능하다.)
손실 함수
Wave-Tacotron을 학습시키기 위한 손실 함수는 두 가지 항으로 구성이 된다.
첫째, 컨디셔닝 벡터가 주어졌을 때 flow로부터 계산되어 나온 파형의 likelihood를 최대화시키는 것이 목적이므로 NLL(negative log likelihood)을 사용한다. (이렇게 직관적인 NLL을 손실 함수로 사용할 수 있다는 것이 flow 모델의 장점이다.) 아래는 그 식을 나타내고 있으며 기본적인 변수 변환(change of variable)에 기반하여 prior인 노이즈 분포에 대한 식으로 표현할 수 있다.
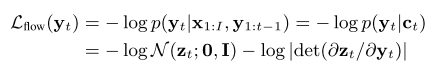
둘째, 디코더에서 예측하는 stop token에 대한 손실 함수이다. 이는 binary cross entropy로 표현할 수 있다.
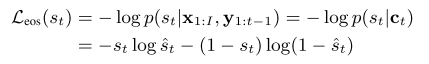
실험 결과
합성 품질
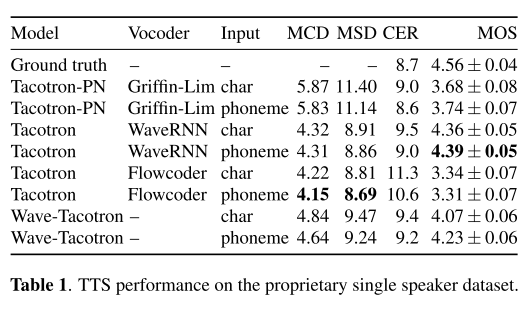
연구진이 자체적으로 수집하여 구축한 단일 화자 데이터셋에 대해서 TTS를 수행한 결과, Wave-Tacotron이 가장 높은 MOS를 기록하지는 못했지만 다른 비교 모델들보다 상대적으로 우수한 품질의 음성을 합성하고 있다고 말할 수 있다. 그리고 Tacotron에 본 연구에서 제안하는 Flowcoder(앞서 본 flow와 형태는 같지만 입력으로 멜 스펙트로그램을 받는 보코더)를 결합한 모델이 가장 높은 MCD, MSD를 기록하는 것으로 보아 flow 과정이 예측 파형과 실제 파형의 간극을 줄이는 데 기여하고 있음을 알 수 있다.
또한 입력으로 phoneme과 character를 넣어서 비교해 본 결과 대부분의 모델에서 phoneme을 입력으로 사용한 경우에 성능이 더 좋다. 이는 아마도 phoneme은 발음에 대한 정보를 이미 갖고 있기 때문에 모델이 학습하기에 조금 더 쉽지만, character를 받게 되면 모델이 문자와 발음 기호 간의 맵핑까지 학습해야 하는 부담이 있기 때문일 것이다.

LJ Speech를 가지고도 성능을 평가했는데 이 경우엔 Wave-Tacotron이 Baseline 모델들보다 현저하게 뒤쳐지는 것을 알 수 있다. 저자들은 이에 대해서 LJ Speech 데이터셋의 크기가 자체적으로 구축했던 데이터셋보다 훨씬 작고, 모델의 하이퍼파라미터들이 자체 데이터셋에 맞게 설정되었기 때문이라고 해명하고 있다.
생성 속도
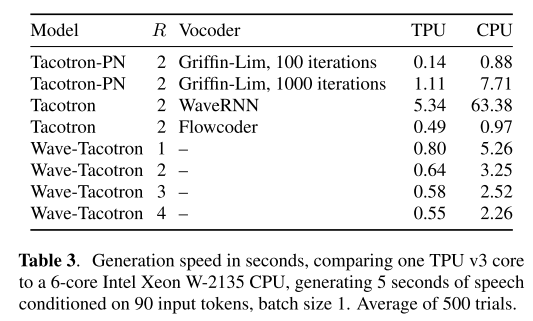
Wave-Tacotron이 다른 Baseline 모델들보다 같은 5초의 음성을 합성하는 데 걸리는 시간이 더 적으므로 속도가 더 빠르다고 할 수 있다. 그리고 디코딩 한 번에 얼마만큼의 샘플 수를 입력으로 사용할지 결정하는 reduction factor(R)가 작아짐에 따라 속도가 느려지는 것을 확인할 수 있다.
Ablation study
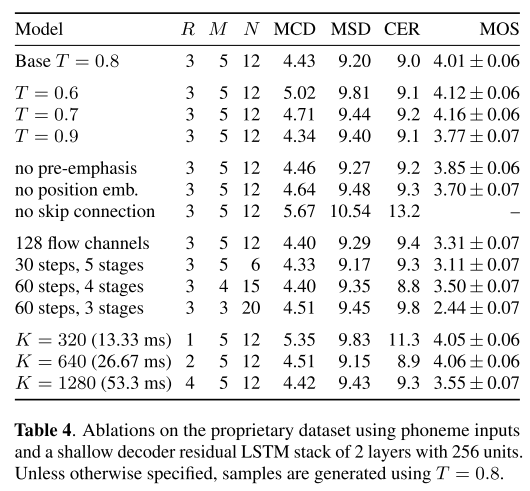
이 밖에 디코더와 flow에서 설정할 수 있었던 구조들을 없애거나 하이퍼파라미터들을 변경해 가면서 음성의 품질을 평가한 결과는 위와 같다. 여기서 알 수 있는 점은 R이 4 이상으로 증가할수록 MOS가 현저히 떨어진다는 점이다. 이를 위의 생성 속도와 결합해서 생각해보면 R은 생성 속도와 MOS 간의 trade-off를 일으킨다는 것을 알 수 있다.
의견
- 어차피 pre-train 과정에는 많은 양의 데이터가 쓰이므로 Wave-Tacotron이 좋은 품질의 음성을 합성하기 위해 많은 데이터가 필요한 것은 큰 단점으로 보이지 않는다.
- R에 의해 생성 속도와 MOS 간의 trade-off가 일어나는 현상은 자기 회귀 모델을 사용하기 때문에 어쩔 수 없이 나타나는 현상인 것 같다. 추후 이를 해결하기 위한 트랜스포머 모델이 나오지 않을까 싶다.

Leave a comment