
WaveGAN & SpecGAN
Donahue, Chris, Julian McAuley, and Miller Puckette. “Adversarial audio synthesis.” arXiv preprint arXiv:1802.04208 (2018).
들어가며
GAN이 이미지 생성 연구에 많이 적용되어 쓰이고 있지만, 오디오 생성에 적용된 연구는 부족한 실정이다. 따라서 본 논문에서는 WaveGAN이라는 일관된 오디오를 합성할 수 있는 GAN 모델을 처음으로 제시한다. 그리고 이 모델의 활용 가능성에 대해 언급하면서 다양한 악기와 새 소리를 합성한 결과를 보여준다.
핵심 요약
- 비지도 방식으로 raw-waveform 오디오를 합성하는 태스크에 처음으로 GAN을 도입한 연구이다.
- phase shuffle 기법을 사용하여 판별자의 일반화된 학습에 도움을 준다.
- raw-waveform뿐만 아니라 spectrogram을 생성하는 GAN도 만들었다.
모델 구조
WaveGAN
- DCGAN에서 수정한 부분
- 2D 컨볼루션(5x5)을 1D 컨볼루션(25)으로 바꿨다.
- stride를 모든 컨볼루션 연산에 대해 늘렸다(2x2→4).
- 생성자와 판별자의 배치 정규화를 제거했다.
- WGAN-GP 전략을 사용하여 모델을 훈련시켰다.
-
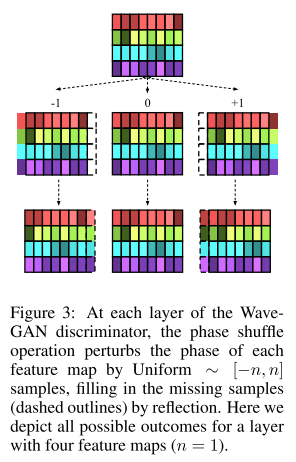
Phase shuffle
transposed convolution에 의해 생성된 이미지에는 ‘체커보드’ 형태를 가진 결점이 나타나는 것으로 알려져 있는데, 오디오에서도 똑같은 결점이 만들어지고 이는 평범한 실제 주파수와 겹쳐진 피치 노이즈로 인식(즉, 실제로 나타날 수 있는 주파수로 인식)이 된다. 그러나 판별자는 특정 위상에서만 나타나는 결점 주파수를 통해 생성된 샘플을 걸러내는 단순한 규칙을 학습할 수 있는데 이는 전체적인 최적화를 저해하기 때문에 phase shuffle 기법을 사용한다.
판별자의 각 층에서 나온 피쳐 맵을 -n~n 사이의 위상만큼 이동시켜 섞어주는 방식으로 판별자는 입력 파형의 위상에 변함 없는(invariant) 특징을 학습해야 하기 때문에 판별자의 학습을 더 어렵게 만들어 줄 수 있다.
SpecGAN
주파수 도메인의 데이터인 스펙트로그램을 생성하는 GAN을 만드는 것이 목표이다.
-
스펙트로그램 표현
이미지 생성을 위해 디자인된 GAN에 잘 맞으면서 오디오로 (거의) 역변환 될 수 있는 스펙트로그램 표현을 연구한다.
- 오디오에 STFT적용하고 사람이 인식할 수 있는 로그 스케일로 변환
- 각 주파수 빈에 대해서는 standard scaling을 적용 (오디오 분류 태스크에서 많이 쓰는 전처리 방식)
- 무계(unbounded) 값을 가지는 스펙트로그램 생성 (이미지 표현 방식에서 기원)
- $3\sigma$ 범위 내의 스펙트로그램을 클리핑하고 [-1,1]로 리스케일링 진행
위와 같은 방식으로 스펙트로그램을 클리핑하고 오디오로 역변환 시켰을 때 나타나는 소리의 차이 없음
준비한 데이터셋에 대해서 위와 같은 전처리가 끝나면 DCGAN을 통해 스펙트로그램을 생성하고 이를 오디오로 바꾸기 위해서 전처리의 역과정으로 선형 스펙트로그램을 만들어낸 뒤에 Griffin-Lim 알고리즘을 적용했다.
실험 결과
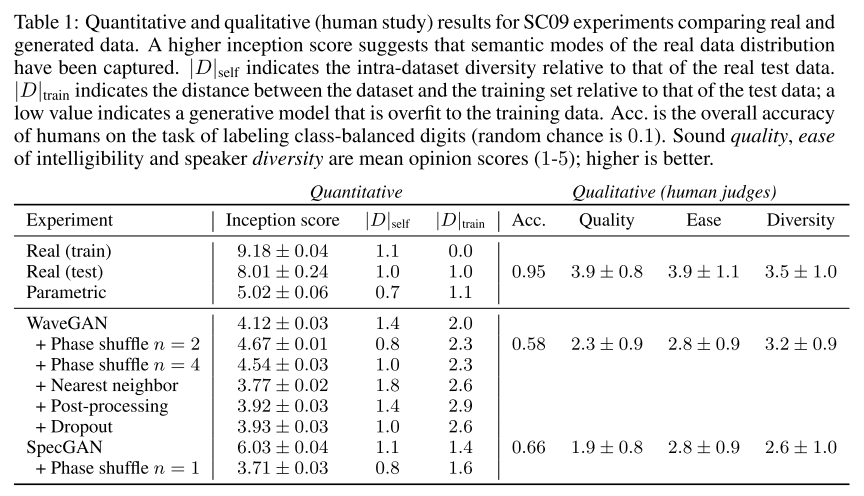
- inception score 사용
-
생성된 오디오의 다양성(diversity), 품질(fidelity, semantic discriminability)을 측정하는 척도
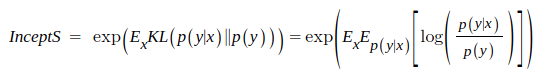
- y: label(class), x: generated sample
- inception-v3 모델을 classifier로 사용 (fc층까지 포함)
-
inception score가 큰 경우는 아래와 같이 샘플의 분포는 예측하기 쉽고(생성 품질이 좋기 때문), 레이블의 분포는 균등한 경우(다양한 오디오가 생성되었기 때문)이다.
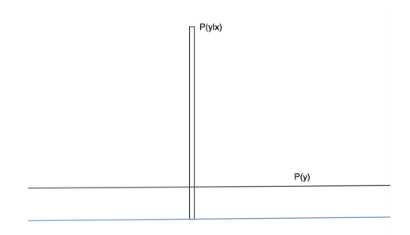
-
의견
- WaveGAN example을 들어봤을 때 악기나 새소리는 괜찮지만 사람 목소리에서 깨지는 경우가 많다.
- 그러나 WaveGAN에서 사용한 phase shuffle기법은 참신하고 실제로 음질을 향상시켜줬기 때문에 다른 GAN모델에 적용 가능하다고 생각된다.
- 생성된 오디오의 결점(artifact)을 면밀하게 관찰하고 이를 완화시키기 위한 조치들을 고민한 내용은 좋은 인사이트를 준다.
- 전반적으로 TTS보다는 음향 효과 생성에 초점을 맞춘 논문이라 사람의 음성합성 품질을 비교하는 측면이 부족하다.




Leave a comment